
ما هي منهجية التعلم المعزز العميق؟
نشرت: 2024-02-28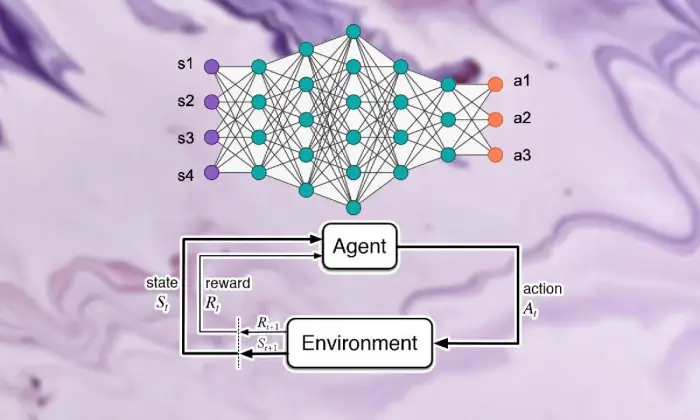
يظل التعلم المعزز العميق في مقدمة أحدث أساليب التفكير التي صنعها الإنسان، حيث يمزج بين مجالات التعلم العميق ويدعم اكتشاف كيفية تمكين الآلات من التعلم بشكل مستقل واتخاذ القرار ببساطة.
يتضمن التعلم المعزز العميق (DRL) إعداد الحسابات للتواصل مع المناخ والاستفادة من النقد كمكافآت أو عقوبات. يجمع هذا الإجراء القوي بين القوة الرمزية لشبكات الدماغ العميقة والقدرات الديناميكية لمتخصصي دعم التعلم.
لقد حظيت DRL باهتمام كبير بسبب مهارتها المذهلة في التعامل مع المهام المعقدة عبر مساحات مختلفة، بدءًا من الألعاب والتكنولوجيا الميكانيكية وحتى الخدمات المساندة والطبية. إن مرونته وقابليته للاستمرار تجعله أساسًا في مجال فحص وتطبيق الذكاء المعتمد على الكمبيوتر، مما يعد بتأثيرات غير عادية عبر المشاريع والمدرسين.
وبينما نتعمق أكثر في تعقيدات التعلم المعزز العميق، يجب علينا أن نكشف عن منهجه ونفك قدرته الحقيقية على تغيير كيفية رؤية الآلات وتعاونها مع محيطها العام.

أساسيات التعلم المعزز
إن الانطلاق في رحلة لرؤية التعلم المعزز العميق يتطلب التعامل القوي مع أساسيات دعم التعلم. في مركزها، تمثل RL رؤية عالمية للذكاء الاصطناعي تشعر بالقلق إزاء كيفية اكتشاف المتخصصين لكيفية اتخاذ قرارات متتالية في مناخ لتعزيز المكافآت المجمعة.
داخل مجال دعم التعلم، هناك بعض الأجزاء والأفكار الحيوية التي تفترض أجزاء أساسية في تشكيل التجربة المتنامية. يجب أن نتعمق في هذه الزوايا لتفكيك جوهر نهج RL:
المفاهيم الأساسية والمصطلحات
لفهم التعلم المعزز العميق، يجب على المرء في البداية قبول الأفكار الأساسية والصياغة الجوهرية لدعم التعلم. تتضمن هذه أفكارًا مثل الحالة والنشاط والجائزة والاستراتيجية، والتي تشكل الكتل الهيكلية لحسابات RL.
مكونات التعلم المعزز
في مشهد التعلم المعزز العميق، يعد فهم الأجزاء الأساسية للتعلم المساند أمرًا حيويًا. يحتوي دعم التعلم على بعض المكونات الأساسية التي تشكل كيفية تواصل المتخصصين مع ظروفهم الحالية وتعلم الأنظمة المثالية بعد مرور بعض الوقت.
هذه الأجزاء، بما في ذلك التخصص والمناخ والأنشطة والجوائز، تشكل الكتل الهيكلية لأطر التعلم الداعمة. من خلال تقدير هذه المكونات الأساسية، يمكننا اكتساب المعرفة حول مدى عمق قدرة حسابات التعلم المعزز وكيفية تطبيقها للتعامل مع المشكلات الديناميكية المحيرة للعقل.
عامل
يشير العامل في التعلم المعزز إلى المادة المسؤولة عن تحديد المناخ والتواصل معه بسهولة. ويتعرف على كيفية استكشاف المناخ في ضوء المواجهات والانتقادات السابقة من خلال المكافآت أو العقوبات.
بيئة
تمثل البيئة الإطار الخارجي الذي يتعاون معه المتخصص. إنه يعطي انتقادات للمتخصص مع تقدم الدولة ومكافآتها، مما يشكل التجربة المتنامية.
أجراءات
تمثل الإجراءات القرارات التي يمكن للمتخصص الوصول إليها في كل نقطة اختيار. يختار المتخصص الأنشطة بسبب وضعها الحالي والنتيجة المثالية، مما يعني تعزيز الجوائز المجمعة على المدى الطويل.
المكافآت
تعمل المكافآت كأداة إدخال للوكيل، مما يدل على جاذبية أنشطته. الجوائز الإيجابية تبني طرقًا مطلوبة للتصرف، بينما الجوائز السلبية تحبط الأنشطة المؤسفة.
عمليات اتخاذ القرار ماركوف (MDPs)
توفر عمليات اتخاذ القرار في ماركوف (MDPs) هيكلًا تقليديًا لإظهار المشكلات الديناميكية المتعاقبة في التعلم المعزز. وهي تتألف من حالات وأنشطة واحتمالات التغيير وجوائز، وتجسد عناصر المناخ بطريقة احتمالية.
فهم التعلم العميق
إن ترك رحلة رؤية التعلم المعزز العميق ينطوي على الغوص في مجال التعلم العميق، وهو جزء أساسي يمكّن الحسابات من فصل الأمثلة والتصويرات المعقدة عن المعلومات. يعد التعلم العميق أساسًا للعديد من أفضل الأساليب في مجال التفكير الذي من صنع الإنسان، مما يمنح الآلات القدرة على تعلم الروابط المعقدة واتخاذ خيارات محسنة.
أساسيات الشبكات العصبية
لفهم جوهر التعلم المعزز العميق، يجب على المرء في البداية أن يتعرف على أساسيات تنظيم الدماغ. تحاكي شبكات الدماغ بنية العقل البشري وقدراته، وتتضمن طبقات مترابطة من الخلايا العصبية التي تقوم بدورة وتغير المعلومات المدخلة. وتتمتع هذه المنظمات ببراعة في تعلم الصور التقدمية، وتمكينها من التقاط أمثلة وعناصر متعددة الجوانب داخل مجموعات البيانات المعقدة.
بنيات التعلم العميق
في مجال التعلم المعزز العميق، يعد فهم تعقيدات هياكل التعلم العميق أمرًا أساسيًا. تعمل هياكل التعلم العميقة كأساس للعديد من الحسابات عالية المستوى، حيث تقوم بإشراك المتخصصين للحصول على أمثلة وصور معقدة من المعلومات.
من خلال التحقيق في هذه الهياكل، يمكننا فك تشابك المكونات التي تمكن المتخصصين من معالجة البيانات وفك تشفيرها، والعمل بديناميكيات ذكية في ظروف فريدة.
الشبكات العصبية التلافيفية (CNN)
تتمتع الشبكات العصبية التلافيفية (CNNs) ببعض الخبرة في التعامل مع المعلومات المشابهة للشبكة، مثل الصور والتسجيلات. فهي تؤثر على الطبقات التلافيفية لإزالة العناصر المكانية تدريجيًا، وتمكينها من أداء المهام المتطورة مثل ترتيب الصور، والتعرف على الكائنات، والتقسيم.
الشبكات العصبية المتكررة (RNNs)
تنجح الشبكات العصبية المتكررة (RNNs) في الاهتمام بالمعلومات المتتابعة بشروط عابرة، مثل السلاسل الزمنية واللغة العادية. لديهم ارتباطات متقطعة تسمح لهم بمواكبة الذاكرة عبر الخطوات الزمنية، مما يجعلها مناسبة لمهام مثل عرض اللغة، والترجمة الآلية، والتعرف على الخطاب.
شبكات Q العميقة (DQNs)
تعالج شبكات Deep Q (DQNs) هندسة محددة لالتقاط الدعم وتعزيز شبكات الدماغ العميقة من خلال حسابات Q-learning. تتعرف هذه المنظمات على كيفية تقريب قدرة تقدير النشاط، وتمكينها من اتخاذ القرار بشأن الخيارات المثالية في الظروف ذات المساحات الحكومية ذات الطبقات العالية.
تدريب الشبكات العصبية
يعد تدريب الشبكات العصبية جزءًا أساسيًا من التعلم المعزز العميق، وهو مهم في تمكين المتخصصين من تحقيق مكاسب في واقع الأمر، ومواصلة تطوير قدراتهم الديناميكية. الشبكات العصبية جاهزة لاستخدام حسابات مثل الانتشار العكسي وانحدار الهبوط، والتي تغير حدود الشركة للحد من أخطاء التوقعات.
طوال دورة الإعداد، يتم الاهتمام بالمعلومات في المنظمة، ويحدد النموذج بشكل متكرر كيفية عمل تنبؤات أكثر دقة. ومن خلال التحديث المتكرر لحدود المنظمة في ضوء الأخطاء الفادحة التي تم ملاحظتها، تعمل شبكات الدماغ بثبات على عرضها للمهمة المحددة. يفترض هذا المسار التكراري للتحسين دورًا محوريًا في التعلم المعزز العميق، مما يمكّن المتخصصين من ضبط وتبسيط أنظمتهم على المدى الطويل.
الانتشار العكسي
يعمل الانتشار العكسي كأساس لتدريب منظمات الدماغ، وتمكينها من الاستفادة من المعلومات عن طريق تغيير حدودها بشكل متكرر للحد من أخطاء التوقعات. يوضح هذا الحساب انحدارات القدرة على التحمل لحدود الشبكة، والعمل على تحسين الإنتاجية من خلال انخفاض الميل.
نزول متدرج
يكمن النزول المتدرج في جوهر تعزيز حدود شبكة الدماغ، وتوجيه التجربة التعليمية نحو الحد الأدنى من القدرة على سوء الحظ. من خلال تحديث الحدود بشكل متكرر نحو الهبوط الأكثر انحدارًا، تعمل حسابات زاوية الهبوط على تمكين منظمات الدماغ من الانضمام إلى الترتيبات المثالية.
اقرأ أيضًا: التعلم العميق مقابل التعلم الآلي: الاختلافات الرئيسية

تكامل التعلم المعزز والتعلم العميق
إن تنسيق التعلم المعزز مع التعلم العميق يعالج تطورًا أساسيًا في مجال الوعي من صنع الإنسان، وذلك باستخدام صفات النموذجين المثاليين بشكل تآزري للتعامل مع المهام الديناميكية المعقدة بقدرة استثنائية على الاستمرار.
مزيج متسق من التعلم العميق واستراتيجيات التعلم الداعمة، مما يكشف عن نظرة ثاقبة للإلهام الذي يدفعهم إلى الانضمام، والصعوبات التي يمثلها التعلم المساند العرفي تقترب، والمزايا الرائدة التي يوفرها دمج أساليب التعلم العميق.
الدافع للتعلم المعزز العميق
يتم الدفع بالانضمام إلى التعلم المعزز العميق من خلال المهمة للحصول على طرق أكثر تنوعًا وقابلية للتكيف وفعالة للتعامل مع ترتيبات التعلم المثالية في الظروف المعقدة. غالبًا ما تتعارض حسابات التعلم المعزز التقليدية مع مساحات الدولة ذات الطبقات العالية والجوائز الضئيلة، مما يحبط ملاءمتها للقضايا الحقيقية.
يقدم التعلم العميق إجابة من خلال إثراء متخصصي التعلم المعزز بالقدرة على الحصول على صور تقدمية من مصادر المعلومات اللمسية الخام، وتمكينهم من استخلاص العناصر الرائعة والأمثلة الأساسية للملاحة.
تحديات التعلم المعزز التقليدي
يواجه التعلم المعزز التقليدي كومة من الصعوبات، بما في ذلك الفشل في الاختبار، ومساحات الحالة غير المباشرة وعالية الطبقات، وآفة الأبعاد. بالإضافة إلى ذلك، تقدم بعض التطبيقات المعتمدة مكافآت ضئيلة ومؤجلة، مما يجعلها تحاول حسابات RL التقليدية تعلم ترتيبات قوية. تتطلب هذه العوائق دمج أساليب التعلم العميقة للتغلب على القيود الجوهرية التي يقترب منها التعلم المعزز التقليدي.
فوائد التعلم العميق في التعلم المعزز
يقدم دمج التعلم العميق في التعلم المعزز مزايا مختلفة، وإصلاح المجال وتمكين قفزات للأمام في مجالات مختلفة.
تعمل الشبكات العصبية العميقة على تمكين متخصصي التعلم المعزز من الحصول بشكل فعال على خرائط معقدة من المساهمات الملموسة الخام في ترتيبات النشاط، متجاوزة متطلبات تصميم العناصر اليدوية.
علاوة على ذلك، تعمل أساليب التعلم العميق مع تصور الأساليب المستفادة عبر ظروف متنوعة، مما يؤدي إلى تحسين القدرة على التكيف وقوة خوارزميات التعلم المعزز.
منهجية التعلم المعزز العميق
يكشف التنقيب في فلسفة التعلم المعزز العميق عن مشهد غني من الأنظمة والإجراءات الموجهة نحو إعداد المتخصصين لاتخاذ القرارات المثالية في الظروف المعقدة.
من خلال فهم هذه الإجراءات، يكتسب المحترفون خبرات في المكونات الأساسية للتجربة المتنامية، وإشراكهم في تخطيط خوارزميات التعلم المعزز الأكثر إنتاجية ونجاحًا.
أ. التعلم المعزز القائم على النموذج مقابل التعلم المعزز القائم على النموذج
في التعلم المعزز العميق، فإن الاختيار بين النهج بلا نموذج والأساليب القائمة على النموذج يشكل بشكل عام التجربة التعليمية. بدون الاستراتيجيات النموذجية، تحصل بشكل مباشر على الإستراتيجية المثالية في واقع الأمر، متجاوزة متطلبات نموذج لا لبس فيه للمناخ.
ومن ناحية أخرى، تشمل التقنيات المبنية على النماذج تعلم نموذج لعناصر المناخ والاستفادة منه في تصميم الأنشطة المستقبلية. ويتمتع كل نهج بفوائده وتسوياته، دون أن تنجح الاستراتيجيات النموذجية في القدرة على التكيف والتنوع، في حين تقدم التقنيات القائمة على النماذج أمثلة أفضل للفعالية والمضاربة.
الاستكشاف مقابل الاستغلال المقايضة
تكمن مقايضة التعامل المزدوج في التحقيق في جوهر التعلم المعزز، وتوجيه كيفية موازنة المتخصصين بين تقييم الأنشطة الجديدة للعثور على استراتيجيات أفضل (التحقيق) والاستفادة من المعلومات المعروفة لزيادة المكافآت السريعة (إساءة الاستخدام).
يجب أن تعمل حسابات التعلم المعزز العميق على تحقيق نوع من الانسجام بين التحقيق وسوء الاستخدام لتعلم استراتيجيات مثالية في الظروف المعقدة. يتم استخدام إجراءات تحقيق مختلفة، مثل اختبار epsilon-avaricious وsoftmax وThompson، لاستكشاف هذه المقايضة وتوجيه عملية التعلم.
طرق التدرج في السياسة
تتناول تقنيات انحدار الإستراتيجية فئة من حسابات التعلم المعزز التي تعمل على تبسيط حدود الترتيب بشكل مباشر لتوسيع المكافآت المتوقعة. تحدد هذه الاستراتيجيات الاستراتيجية على أنها شبكة عصبية وتستخدم ارتفاع المنحدر لتحديث الأحمال التنظيمية بسبب زوايا التعويضات المتوقعة لحدود الاقتراب.
توفر تقنيات زاوية الإستراتيجية بعض الفوائد، بما في ذلك القدرة على التعامل مع مساحات النشاط بدون توقف والاستراتيجيات العشوائية، مما يجعلها مناسبة للمهام المعقدة في التعلم المعزز العميق.
طرق دالة القيمة
تهدف تقنيات القدرة على التقدير إلى قياس قيمة الحالات أو تطابقات نشاط الدولة، مما يوفر تجارب في العائد الطبيعي في ظل استراتيجية معينة. غالبًا ما تستخدم حسابات التعلم المعزز العميق أدوات تقريبية لقدرة القيمة، مثل شبكات Q العميقة (DQNs)، للحصول على قدرة القيمة المثالية.
من خلال استخدام الشبكات العصبية العميقة، يمكن لتقنيات القدرة على التقدير أن تخطئ في قدرات القيمة المعقدة وأن تعمل مع تحسين النهج والتنقل بكفاءة.
أساليب الممثل الناقد
تعمل أساليب الممثل الناقد على توحيد فوائد كل من تقنيات انحدار الإستراتيجية والقدرة على القيمة، وذلك باستخدام منظمات منفصلة للفنانين والنقاد للتعرف على الترتيب والقدرة على القيمة في وقت واحد.
تتعلم شبكة الجهات الفاعلة معلمات السياسة، بينما تقوم شبكة الناقد بتقدير وظيفة القيمة لتقديم تعليقات حول جودة الإجراءات.
تتيح هذه البنية لأساليب الممثل الناقد تحقيق التوازن بين الاستقرار والكفاءة، مما يجعلها مستخدمة على نطاق واسع في أبحاث وتطبيقات التعلم المعزز العميق.
خوارزميات التعلم المعزز العميق
يكشف البحث في مجال خوارزميات التعلم المعزز عن مشهد مختلف للأنظمة الموجهة نحو تمكين المتخصصين من التعلم بشكل مستقل والتكيف مع الظروف المعقدة. تعالج هذه الحسابات قوة منظمات الدماغ العميقة لغرس عملاء التعلم المعزز مع القدرة على استكشاف مساحات الاختيار المحيرة للعقل وتحسين طرق تصرفهم بعد مرور بعض الوقت.
شبكات Q العميقة (DQN)
تعالج شبكات Deep Q-Networks (DQN) تقدمًا أصليًا في التعلم المعزز العميق، حيث تقدم مزيجًا من الشبكات العصبية العميقة مع حسابات Q-learning. من خلال تقريب قدرة تقدير النشاط باستخدام منظمات الدماغ، تعمل DQNs على تمكين المتخصصين من الحصول على ترتيبات مثالية من مساحات الحالة عالية الطبقات، مما يجعلهم جاهزين للقفز إلى الأمام في مجالات مثل الألعاب والروبوتات.
التدرج العميق للسياسة الحتمية (DDPG)
تعمل حسابات التدرج العميق للسياسة الحتمية (DDPG) على توسيع معايير تقنيات النقاد الترفيهية لتشمل مساحات نشاط ثابتة، مما يمكّن المتخصصين من تعلم الأساليب الحتمية من خلال تسلق المنحدرات. من خلال دمج شبكات الدماغ العميقة مع حساب المنحدر الاستراتيجي الحتمي، تعمل DDPG على تعلم ترتيبات التحكم المذهلة في مهام مثل التحكم الميكانيكي والقيادة المستقلة.
تحسين السياسة القريبة (PPO)
توفر حسابات تحسين السياسة القريبة (PPO) طريقة مبدئية للتعامل مع تبسيط حدود الإستراتيجية من خلال ضرورات منطقة الثقة، مما يضمن تحديث الترتيبات الثابتة والمثمرة. من خلال تطوير حدود الترتيب بشكل متكرر باستخدام ارتفاع الزاوية العشوائي، تحقق حسابات PPO تنفيذًا متطورًا في معايير تعلم دعم مختلفة، مما يُظهر الحماس والتنوع عبر ظروف متنوعة.
تحسين سياسة منطقة الثقة (TRPO)
تركز حسابات تحسين سياسة منطقة الثقة (TRPO) على الثبات واختبار الإنتاجية من خلال إلزام تحديث الترتيبات داخل منطقة الثقة، مما يخفف من مقامرة الانحرافات الإستراتيجية الضخمة.
من خلال الاستفادة من قيود منطقة الثقة لتوجيه تحديثات السياسة، تعرض خوارزميات TRPO خصائص تقارب محسنة ومتانة لتغيرات المعلمات الفائقة، مما يجعلها مناسبة تمامًا لتطبيقات التعلم المعزز في العالم الحقيقي.
الناقد الفاعل ذو الميزة غير المتزامنة (A3C)
تستخدم حسابات الممثل والناقد للميزة غير المتزامنة (A3C) دورات إعداد غير متزامنة لتسريع التعلم ومواصلة تطوير فعالية الاختبار في مهام التعلم المعزز. من خلال الاستفادة من وسائل الترفيه المتساوية المختلفة التي تتصل بالطقس بشكل غير متزامن، تعمل حسابات A3C مع بحث أكثر تنوعًا وتمكن المتخصصين من تعلم الترتيبات الفعالة في ظروف معقدة وديناميكية.
خاتمة
بشكل عام، تمثل استراتيجية التعلم المعزز العميق طريقة متعددة الطبقات للتعامل مع تمكين الآلات من التعلم ومتابعة الاختيارات بشكل مستقل في الظروف المعقدة. طوال هذا التحقيق، تعمقنا في أساسيات التعلم المعزز، وتنسيق إجراءات التعلم العميق، والعروض المختلفة للحسابات التي تقود التقدم في هذا المجال.
من خلال فهم معايير واستراتيجيات المركز، نكتسب المعرفة بأهمية التعلم المعزز العميق في التعامل مع الصعوبات المعتمدة عبر مساحات مختلفة، بدءًا من الميكانيكا المتقدمة والألعاب وحتى الرعاية الطبية والمال. كما نخطط، فإن الأبواب المفتوحة المحتملة لمزيد من التقدم والتحسين في التعلم المعزز العميق غير محدودة.
ومن خلال الفحص المستمر والتقدم، يمكننا أن نتوقع حسابات أكثر دقة إلى حد كبير، وتحسين القدرة على التكيف، وملاءمة أكثر شمولاً في البيئات المختلفة. للبقاء على اطلاع بأحدث التطورات والانضمام إلى المناقشة، تابع وشارك اعتباراتك وانتقاداتك في التعليقات أدناه.
تذكر أن تنقل هذه البيانات المهمة إلى رفاقك وشركائك، مما يتيح للآخرين استكشاف العالم المثير للاهتمام للتعلم المعزز العميق. معًا، يمكننا دفع عجلة التقدم وفتح أقصى سعة للذكاء الاصطناعي.