
Was ist die Methodik des Deep Reinforcement Learning?
Veröffentlicht: 2024-02-28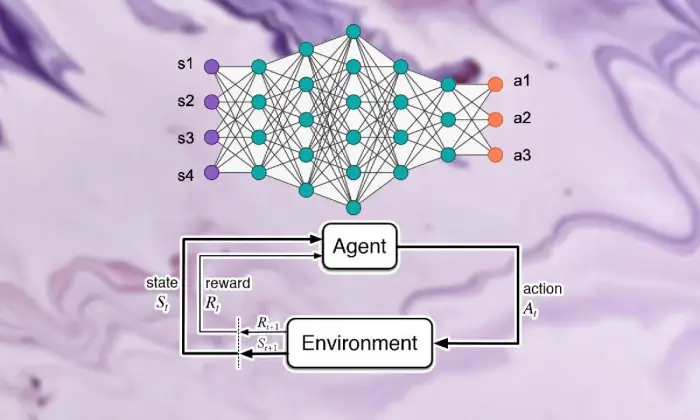
Deep Reinforcement Learning steht nach wie vor an der Spitze des modernen künstlichen Denkens, indem es die Bereiche des tiefgreifenden Lernens vermischt und dabei hilft, herauszufinden, wie Maschinen in die Lage versetzt werden können, unabhängig zu lernen und einfach zu entscheiden.
Deep Reinforcement Learning (DRL) umfasst die Vorbereitung von Berechnungen, um eine Verbindung zu einer Umgebung herzustellen und von Kritik als Belohnung oder Strafe zu profitieren. Dieses starke Verfahren verbindet die symbolische Kraft tiefgreifender Gehirnnetzwerke mit den dynamischen Fähigkeiten unterstützender Lernspezialisten.
DRL hat aufgrund seiner herausragenden Kompetenz bei der Bewältigung komplexer Aufgaben in verschiedenen Bereichen, von Gaming und mechanischer Technologie bis hin zu Rücken- und medizinischen Dienstleistungen, enorme Beachtung gefunden. Seine Flexibilität und Praktikabilität machen es zu einer Grundlage im Bereich der computergestützten Intelligenzprüfung und -anwendung und versprechen außergewöhnliche Auswirkungen für Unternehmen und Lehrer.
Wenn wir tiefer in die Komplexität des Deep Reinforcement Learning eintauchen, sollten wir seinen Ansatz aufdecken und seine wahre Fähigkeit entschlüsseln, die Art und Weise zu verändern, wie Maschinen ihre allgemeine Umgebung sehen und mit ihr zusammenarbeiten.

Grundlagen des Reinforcement Learning
Wenn man sich auf den Weg machen möchte, tiefes Reinforcement Learning zu erleben, muss man sich mit den Grundlagen des unterstützenden Lernens gut auskennen. Im Kern handelt es sich bei RL um eine Weltanschauung der KI, bei der es darum geht, wie Experten herausfinden, wie sie in einem Umfeld, in dem die gemeinsamen Belohnungen gesteigert werden, aufeinanderfolgende Entscheidungen treffen können.
Im Bereich des unterstützenden Lernens spielen einige wichtige Teile und Ideen eine wesentliche Rolle bei der Gestaltung der Lernerfahrung. Wir sollten uns mit diesen Aspekten befassen, um den Kern des RL-Ansatzes zu entschlüsseln:
Grundlegende Konzepte und Terminologie
Um Deep Reinforcement Learning zu verstehen, muss man zunächst die wesentlichen Ideen und Formulierungen akzeptieren, die zur Unterstützung des Lernens inhärent sind. Dazu gehören Gedanken wie Zustand, Aktivität, Preis und Strategie, die die Strukturblöcke der RL-Berechnungen strukturieren.
Komponenten des Reinforcement Learning
In der Szene des Deep Reinforcement Learning ist das Verständnis der grundlegenden Teile des Support Learnings von entscheidender Bedeutung. Unterstützendes Lernen enthält einige Schlüsselkomponenten, die bestimmen, wie sich Spezialisten mit ihren aktuellen Umständen auseinandersetzen und nach einiger Zeit ideale Systeme erlernen.
Diese Teile, einschließlich der Fachkraft, des Klimas, der Aktivitäten und der Preise, strukturieren die Strukturblöcke der unterstützenden Lernrahmen. Durch die Wertschätzung dieser wesentlichen Komponenten können wir uns Kenntnisse darüber aneignen, wie tiefgreifende Reinforcement-Learning-Berechnungen funktionieren und wie sie angewendet werden, um verblüffende dynamische Probleme zu lösen.
Agent
Der Agent beim verstärkenden Lernen bezieht sich auf die Substanz, die für die einfache Entscheidung und Verbindung mit der Umwelt verantwortlich ist. Es wird herausgefunden, wie man das Klima im Lichte früherer Begegnungen und Kritik durch Belohnungen oder Strafen erkunden kann.
Umfeld
Die Umgebung verkörpert den äußeren Rahmen, mit dem der Spezialist zusammenarbeitet. Es gibt dem Fachmann Kritik, während der Staat voranschreitet und belohnt und so die wachsende Erfahrung formt.
Aktionen
Aktionen stellen die Entscheidungen dar, die dem Spezialisten an jedem Wahlpunkt zugänglich sind. Der Spezialist wählt Aktivitäten aufgrund ihres aktuellen Status und des idealen Ergebnisses aus, um die Gesamtprämien langfristig zu steigern.
Belohnung
Belohnungen dienen dem Agenten als Inputinstrument und zeigen die Attraktivität seiner Aktivitäten auf. Positive Preise fördern gewünschte Verhaltensweisen, während negative Preise unglückliche Aktivitäten abschwächen.
Markov-Entscheidungsprozesse (MDPs)
Markov-Entscheidungsprozesse (MDPs) bieten eine konventionelle Struktur zur Demonstration aufeinanderfolgender dynamischer Probleme beim verstärkenden Lernen. Sie bestehen aus Zuständen, Aktivitäten, Änderungswahrscheinlichkeiten und Preisen und veranschaulichen die Elemente des Klimas auf probabilistische Weise.
Deep Learning verstehen
Um den Ausflug in die Betrachtung von Deep Reinforcement Learning fortzusetzen, muss man in den Bereich des Deep Reinforcement Learning eintauchen, einem grundlegenden Teil, der Berechnungen ermöglicht, um komplexe Beispiele und Darstellungen von den Informationen zu trennen. Deep Learning bildet die Grundlage für viele erstklassige Ansätze im künstlichen Denken und gibt Maschinen die Möglichkeit, komplizierte Zusammenhänge zu lernen und verfeinerte Entscheidungen zu treffen.
Grundlagen neuronaler Netze
Um die Substanz des Deep Reinforcement Learning zu ergründen, muss man zunächst die Grundlagen der Gehirnorganisation in den Griff bekommen. Gehirnnetzwerke imitieren den Aufbau und die Fähigkeiten des menschlichen Geistes und umfassen miteinander verbundene Schichten von Neuronen, die Eingabeinformationen wechseln und verändern. Diese Organisationen sind geschickt im Erlernen progressiver Darstellungen und befähigen sie, vielseitige Beispiele und Elemente in komplexen Datensätzen zu erfassen.
Deep-Learning-Architekturen
Im Bereich des Deep Reinforcement Learning ist das Verständnis der Komplexität tiefgreifender Lernstrukturen von zentraler Bedeutung. Tiefgründige Lernstrukturen bilden die Grundlage für viele hochrangige Berechnungen und fordern Spezialisten dazu auf, aus Informationen komplexe Beispiele und Darstellungen zu gewinnen.
Durch die Untersuchung dieser Strukturen können wir die Komponenten entwirren, die es Spezialisten ermöglichen, Daten zu verarbeiten und zu entschlüsseln und dabei mit scharfsinniger Dynamik unter einzigartigen Bedingungen zu arbeiten.
Faltungs-Neuronale Netze (CNNs)
Convolutional Neural Networks (CNNs) verfügen über gewisse Fachkenntnisse im Umgang mit netzwerkähnlichen Informationen wie Bildern und Aufzeichnungen. Sie beeinflussen Faltungsschichten, um räumliche Elemente schrittweise zu entfernen, und befähigen sie so, hochmoderne Aufgaben wie Bildreihenfolge, Objekterkennung und Teilung auszuführen.
Wiederkehrende neuronale Netze (RNNs)
Rekurrente neuronale Netze (RNNs) sind in der Lage, aufeinanderfolgende Informationen mit vorübergehenden Bedingungen wie Zeitreihen und regulärer Sprache zu verarbeiten. Sie haben intermittierende Assoziationen, die es ihnen ermöglichen, über Zeitschritte hinweg mit dem Gedächtnis Schritt zu halten, was sie für Besorgungen wie Sprachanzeige, maschinelle Interpretation und Diskursbestätigung geeignet macht.
Tiefe Q-Netzwerke (DQNs)
Deep Q-Networks (DQNs) befassen sich mit einer speziellen Technik zur Unterstützung der Aufnahme und Konsolidierung tiefgreifender Gehirnnetzwerke mit Q-Learning-Berechnungen. Diese Organisationen finden heraus, wie sie die Leistungsfähigkeit verbessern können, um in Situationen mit hochgradig geschichteten Zustandsräumen optimale Entscheidungen treffen zu können.
Training neuronaler Netze
Das Training neuronaler Netze ist ein grundlegender Bestandteil des Deep Reinforcement Learning und trägt entscheidend dazu bei, dass Experten tatsächlich Gewinne erzielen und ihre dynamischen Fähigkeiten weiterentwickeln können. Neuronale Netze sind darauf vorbereitet, Berechnungen wie Backpropagation und Slope Plummet zu nutzen, die die Grenzen der Organisation verändern, um Erwartungsfehler zu begrenzen.
Während des gesamten Vorbereitungszyklus werden die Informationen in der Organisation verwaltet und das Modell ermittelt iterativ, wie präzisere Prognosen erstellt werden können. Durch die iterative Aktualisierung der Organisationsgrenzen bei festgestellten Fehlern arbeiten Gehirnnetzwerke kontinuierlich an ihrer Präsentation des jeweiligen Auftrags. Dieser iterative Verbesserungsprozess nimmt eine zentrale Rolle beim Deep Reinforcement Learning ein und ermöglicht es Experten, ihre Systeme langfristig anzupassen und zu optimieren.
Backpropagation
Backpropagation dient als Grundlage für die Vorbereitung von Gehirnorganisationen und befähigt sie, von Informationen zu profitieren, indem sie ihre Grenzen iterativ ändern, um Erwartungsfehler zu begrenzen. Diese Berechnung berechnet Steigungen der Unglückskapazität für Netzwerkgrenzen und arbeitet mit produktiver Verbesserung durch Neigungseinbruch.
Gradientenabstieg
Der Gradientenabstieg ist der Kern der Verbesserung der Netzwerkgrenzen des Gehirns und lenkt die Lernerfahrung auf die Minima der Unglücksfähigkeit. Durch die iterative Aktualisierung der Grenzen in Richtung des steilsten Abfalls ermöglichen Winkeleinbruchsberechnungen Gehirnorganisationen, sich zu idealen Vereinbarungen zusammenzuschließen.
Lesen Sie auch: Deep Learning vs. Machine Learning: Hauptunterschiede
Integration von Reinforcement Learning und Deep Learning
Die Koordinierung von Reinforcement Learning mit Deep Learning adressiert einen wesentlichen Fortschritt im Bereich des vom Menschen geschaffenen Bewusstseins und nutzt synergetisch die Qualitäten der beiden idealen Modelle, um komplexe dynamische Unternehmungen mit außergewöhnlicher Realisierbarkeit zu bewältigen.
Konsequente Kombination von Deep-Learning- und Support-Learning-Strategien, die Einblicke in die Inspirationen gibt, die ihren Beitritt vorantreiben, die Schwierigkeiten, die das Herannahen herkömmlicher Support-Learning mit sich bringt, und die bahnbrechenden Vorteile, die sich aus der Kombination tiefgreifender Lernmethoden ergeben.

Motivation für Deep Reinforcement Learning
Der Zusammenschluss von Deep Reinforcement Learning wird durch das Ziel vorangetrieben, vielseitigere, anpassungsfähigere und effektivere Methoden für den Umgang mit idealen Lernarrangements unter komplexen Bedingungen zu finden. Herkömmliche Reinforcement-Learning-Berechnungen kämpfen oft mit hochschichtigen Zustandsräumen und dürftigen Preisen, was ihre Eignung für echte Probleme beeinträchtigt.
Deep Learning bietet eine Antwort, indem es Spezialisten für Reinforcement Learning mit der Fähigkeit ausstattet, fortschrittliche Darstellungen aus groben taktilen Informationsquellen zu gewinnen, und sie so in die Lage versetzt, bemerkenswerte Elemente und Beispiele herauszuarbeiten, die für die Navigation von grundlegender Bedeutung sind.
Herausforderungen des traditionellen Reinforcement Learning
Traditionelles verstärkendes Lernen ist mit einer Menge Schwierigkeiten konfrontiert, darunter Testversagen, nicht-direkte und hochschichtige Zustandsräume und die Geißel der Dimensionalität. Darüber hinaus bieten einige zertifizierbare Anwendungen dürftige und verzögerte Belohnungen, was es schwierig macht, mit herkömmlichen RL-Berechnungen leistungsstarke Vereinbarungen zu treffen. Diese Hindernisse erfordern die Einbeziehung tiefgreifender Lernmethoden, um die intrinsischen Einschränkungen des traditionellen verstärkenden Lernens zu überwinden.
Vorteile von Deep Learning beim Reinforcement Learning
Die Konsolidierung von Deep Learning im Reinforcement Learning bietet verschiedene Vorteile, reformiert das Fachgebiet und ermöglicht Fortschritte in verschiedenen Bereichen.
Tiefe neuronale Netze ermöglichen es Spezialisten für Reinforcement Learning, effektiv komplexe Zuordnungen aus groben, greifbaren Beiträgen zu Aktivitätsanordnungen zu gewinnen, ohne dass eine manuelle Elementgestaltung erforderlich ist.
Darüber hinaus arbeiten Deep-Learning-Methoden mit der Spekulation gelernter Ansätze über verschiedene Bedingungen hinweg und verbessern so die Anpassungsfähigkeit und Stärke von Reinforcement-Learning-Algorithmen.
Methodik des Deep Reinforcement Learning
Wenn man sich mit der Philosophie des Deep Reinforcement Learning befasst, entdeckt man eine Vielzahl von Systemen und Verfahren, die darauf abzielen, Spezialisten darauf vorzubereiten, unter komplexen Bedingungen ideale Entscheidungen zu treffen.
Durch das Verständnis dieser Verfahren sammeln Fachleute Erfahrungen mit den Komponenten, die der wachsenden Erfahrung zugrunde liegen, und motivieren sie, produktivere und erfolgreichere Reinforcement-Learning-Algorithmen zu planen.
A. Modellfreies vs. modellbasiertes Verstärkungslernen
Beim Deep Reinforcement Learning prägt die Entscheidung zwischen modelllosen und modellbasierten Ansätzen im Allgemeinen die Bildungserfahrung. Ohne Modellstrategien erhalten Sie einfach die ideale Strategie, ohne dass ein eindeutiges Klimamodell erforderlich ist.
Andererseits umfassen modellbasierte Techniken das Erlernen eines Modells der Klimaelemente und dessen Nutzung zur Gestaltung zukünftiger Aktivitäten. Jeder Ansatz hat seine Vorteile und Kompromisse, ohne dass Modellstrategien hinsichtlich Anpassungsfähigkeit und Vielseitigkeit erfolgreich sind, während modellbasierte Techniken bessere Beispiele für Wirksamkeit und Spekulation bieten.
Kompromiss zwischen Exploration und Ausbeutung
Der Kompromiss zwischen der Untersuchung und dem doppelten Handeln liegt im Kern des Reinforcement Learning und legt fest, wie Spezialisten zwischen der Bewertung neuer Aktivitäten, um möglicherweise bessere Strategien zu finden (Untersuchung), und der Nutzung bekannter Informationen, um schnelle Belohnungen zu steigern (Missbrauch), ein Gleichgewicht finden.
Berechnungen des tiefgreifenden Verstärkungslernens sollten eine Art Harmonie zwischen Ermittlung und Missbrauch herstellen, um ideale Strategien unter komplexen Bedingungen zu erlernen. Verschiedene Untersuchungsverfahren wie Epsilon-Avaricious-, Softmax- und Thompson-Tests werden verwendet, um diesen Kompromiss zu untersuchen und den Lernprozess zu steuern.
Richtliniengradientenmethoden
Strategieneigungstechniken befassen sich mit einer Klasse von Reinforcement-Learning-Berechnungen, die die Arrangementgrenzen einfach rationalisieren, um erwartete Belohnungen zu erweitern. Diese Strategien definieren die Strategie als neuronales Netzwerk und nutzen Steigungsanstiege, um die Organisationslasten aufgrund der Winkel der erwarteten Kompensationen für die Annäherungsgrenzen zu aktualisieren.
Strategiewinkeltechniken bieten einige Vorteile, darunter die Fähigkeit, mit ununterbrochenen Aktivitätsräumen und stochastischen Strategien umzugehen, wodurch sie für komplexe Unternehmungen im Bereich Deep Reinforcement Learning geeignet sind.
Wertfunktionsmethoden
Wertschätzungstechniken zielen darauf ab, den Wert von Staaten oder Zustands-Aktivitäts-Übereinstimmungen zu messen und Erfahrungen in die normale Rendite im Rahmen einer bestimmten Strategie einzubeziehen. Berechnungen des Deep Reinforcement Learning nutzen häufig Näherungswerte für Wertschätzungsfähigkeiten, beispielsweise Deep Q-Networks (DQNs), um die Idealwertfähigkeit zu ermitteln.
Durch den Einsatz tiefer neuronaler Netze können Wertschätzungstechniken komplexe Wertfähigkeiten exakt erfassen und mit einer effizienten Ansatzverbesserung und -navigation arbeiten.
Schauspielerkritische Methoden
Schauspielerkritische Methoden konsolidieren die Vorteile sowohl der Strategieneigung als auch der Wertfähigkeitsstrategien und nutzen separate Künstler- und Expertenteams, um sich gleichzeitig mit der Struktur und der Wertfähigkeit vertraut zu machen.
Das Akteursnetzwerk lernt die Richtlinienparameter, während das Kritikernetzwerk die Wertefunktion schätzt, um Feedback zur Qualität der Maßnahmen zu geben.
Diese Architektur ermöglicht es akteurskritischen Methoden, ein Gleichgewicht zwischen Stabilität und Effizienz zu erreichen, wodurch sie in der Forschung und in Anwendungen des Deep Reinforcement Learning weit verbreitet sind.
Deep-Reinforcement-Learning-Algorithmen
Wenn man sich mit den Algorithmen des verstärkenden Lernens befasst, entdeckt man eine andere Szene von Systemen, die darauf abzielen, Spezialisten in die Lage zu versetzen, selbstständig zu lernen und sich an komplexe Bedingungen anzupassen. Diese Berechnungen befassen sich mit der Kraft tiefgreifender Gehirnorganisationen, Agenten des verstärkenden Lernens die Fähigkeit zu vermitteln, verblüffende Wahlräume zu erkunden und ihre Verhaltensweisen nach einiger Zeit zu verbessern.
Tiefe Q-Netzwerke (DQN)
Deep Q-Networks (DQN) stellen einen neuen Fortschritt im Deep Reinforcement Learning dar und bieten eine Mischung aus tiefen neuronalen Netzen und Q-Learning-Berechnungen. Durch die Annäherung der Leistungsfähigkeit an die Wertschätzung mithilfe von Gehirnstrukturen ermöglichen DQNs Fachleuten, aus hochschichtigen Zustandsräumen ideale Arrangements zu gewinnen, und machen sie so bereit für Fortschritte in Bereichen wie Gaming und Robotik.
Deep Deterministic Policy Gradient (DDPG)
Deep Deterministic Policy Gradient (DDPG)-Berechnungen erweitern die Standards der Entertainer-Pandit-Techniken auf konstante Aktivitätsräume und befähigen Spezialisten, deterministische Ansätze durch Hangklettern zu erlernen. Durch die Konsolidierung tiefgreifender Gehirnnetzwerke mit der deterministischen Strategie-Steigungsberechnung arbeitet DDPG an der Erlernung verblüffender Steuerungsanordnungen in Unternehmungen wie mechanischer Steuerung und autonomem Fahren.
Proximale Richtlinienoptimierung (PPO)
Berechnungen der Proximal Policy Optimization (PPO) bieten eine prinzipielle Möglichkeit, mit der Straffung von Strategiegrenzen durch Trust-Distrikt-Imperative umzugehen und so stabile und produktive Vereinbarungsaktualisierungen zu gewährleisten. Durch die iterative Erweiterung der Strukturgrenzen unter Verwendung stochastischer Winkelanstiege ermöglichen PPO-Berechnungen eine hochmoderne Ausführung in unterschiedlichen Support-Learning-Benchmarks und zeigen Zuverlässigkeit und Vielseitigkeit unter verschiedenen Bedingungen.
Optimierung der Trust-Region-Richtlinie (TRPO)
TRPO-Berechnungen (Trust Region Policy Optimization) konzentrieren sich auf Stabilität und Testproduktivität, indem sie Systemaktualisierungen innerhalb eines Vertrauensbezirks erzwingen und so das Risiko großer Strategieabweichungen verringern.
Durch die Nutzung von Einschränkungen der Vertrauensregion zur Steuerung von Richtlinienaktualisierungen weisen TRPO-Algorithmen verbesserte Konvergenzeigenschaften und Robustheit gegenüber Hyperparametervariationen auf, wodurch sie sich gut für reale Anwendungen des Reinforcement Learning eignen.
Asynchronous Advantage Actor-Critic (A3C)
Asynchronous Advantage Actor-Critic (A3C)-Berechnungen nutzen nicht gleichzeitige Vorbereitungszyklen, um das Lernen zu beschleunigen und die Testeffektivität bei Reinforcement-Learning-Unternehmungen weiter zu verbessern. Durch den Einsatz unterschiedlicher gleichberechtigter Akteure, die sich gleichzeitig mit der Umgebung verbinden, arbeiten A3C-Berechnungen mit vielfältigeren Untersuchungen und ermöglichen es Fachleuten, leistungsstarke Systeme in komplizierten und dynamischen Situationen zu erlernen.
Abschluss
Alles in allem ist die Strategie des Deep Reinforcement Learning ein Beispiel für einen vielschichtigen Umgang mit der Befähigung von Maschinen, unter komplexen Bedingungen selbstständig zu lernen und Entscheidungen zu treffen. Im Laufe dieser Untersuchung haben wir uns mit den Grundlagen des verstärkenden Lernens, der Koordination tiefgreifender Lernprozesse und den verschiedenen Beispielen von Berechnungen befasst, die in diesem Bereich Fortschritte machen.
Durch das Verständnis der Standards und Strategien des Zentrums gewinnen wir Erkenntnisse über die Bedeutung von Deep Reinforcement Learning für den Umgang mit nachweisbaren Schwierigkeiten in verschiedenen Bereichen, von fortgeschrittener Mechanik und Spielen bis hin zu medizinischer Versorgung und Geld. Wie wir planen, sind die potenziellen offenen Türen für weitere Fortschritte und Verbesserungen im Deep Reinforcement Learning unbegrenzt.
Bei kontinuierlicher Prüfung und Weiterentwicklung können wir deutlich verfeinerte Berechnungen, eine verbesserte Anpassungsfähigkeit und eine umfassendere Relevanz in verschiedenen Umgebungen erwarten. Um über die neuesten Entwicklungen auf dem Laufenden zu bleiben und an der Diskussion teilzunehmen, teilen Sie Ihre Überlegungen und Kritik in den folgenden Kommentaren mit.
Denken Sie daran, diese wichtigen Daten an Ihre Freunde und Partner weiterzugeben, damit andere das interessante Universum des Deep Reinforcement Learning erkunden können. Gemeinsam können wir den Fortschritt vorantreiben und das maximale Potenzial der künstlichen Intelligenz erschließen.