
ChatGPT や他の言語の AI は、私たちと同じように不合理です
公開: 2023-04-10ここ数年で、詩を書いたり、人間のような会話をしたり、医学部の試験に合格したりできる大規模な言語モデルの人工知能システムの爆発的な進歩が見られました。
この進歩により、ChatGPT のようなモデルが生まれました。このモデルは、失業や誤った情報の増加から生産性の大幅な向上に至るまで、社会的および経済的に大きな影響を与える可能性があります。
その優れた能力にもかかわらず、大規模な言語モデルは実際には考えません。 彼らは基本的な間違いを犯す傾向があり、物事をでっち上げることさえあります。
しかし、彼らは流暢な言語を生成するため、人々は彼らが考えているかのように彼らに反応する傾向があります.

これにより、研究者はモデルの「認知」能力とバイアスを研究するようになりました。これは、大規模な言語モデルが広く利用できるようになった現在、重要性が増している研究です。
この一連の研究は、Google の BERT などの初期の大規模言語モデルにさかのぼります。BERT は検索エンジンに統合されているため、BERTology と呼ばれています。
この研究は、そのようなモデルができることと、どこでうまくいかないかについて、すでに多くのことを明らかにしています。
たとえば、巧妙に設計された実験では、多くの言語モデルが否定の処理 (たとえば、「何がそうでないか」という質問) や簡単な計算を行うのに問題があることが示されています。
たとえ間違っていたとしても、彼らは自分の答えに過度に自信を持っている可能性があります。 他の最新の機械学習アルゴリズムと同様に、特定の方法で答えた理由を尋ねられたときに、自分自身を説明するのに苦労します
言葉と思い
BERTology や認知科学などの関連分野における研究の増加に触発されて、学生の Zhisheng Tang と私は、大規模な言語モデルに関する一見単純な質問に答えようと試みました。
合理的なという言葉は、日常英語では正気または妥当の同義語としてよく使用されますが、意思決定の分野では特定の意味を持ちます。
意思決定システムは、個々の人間であれ、組織のような複雑なエンティティであれ、一連の選択肢が与えられ、期待される利益を最大化することを選択する場合、合理的です。
「予想される」という修飾子は重要です。これは、意思決定が重大な不確実性の条件下で行われることを示しているためです。
公正なコインを投げると、平均して半分の確率で表が出ることがわかっています。 ただし、特定のコイン トスの結果を予測することはできません。
これが、カジノが時折大きなペイアウトを支払う余裕がある理由です。狭いハウスオッズでさえ、平均して莫大な利益を生み出します。
表面的には、単語や文章の意味を実際に理解せずに正確な予測を行うように設計されたモデルが、期待される利益を理解できると仮定するのは奇妙に思えます。
しかし、言語と認知が絡み合っていることを示す膨大な研究があります。
優れた例は、20 世紀初頭に科学者のエドワード サピアとベンジャミン リー ウォーフによって行われた独創的な研究です。 彼らの研究は、母国語と語彙が人の考え方を形成する可能性があることを示唆しています。

これがどの程度真実であるかについては議論の余地がありますが、ネイティブ アメリカンの文化の研究から人類学的証拠が裏付けられています。
たとえば、アメリカ南西部のズニ族が話すズニ語の話者は、オレンジ色と黄色を表す別個の単語を持たないため、オレンジ色と黄色を表す別個の単語を持つ言語の話者ほど効果的にこれらの色を区別することができません。色。
賭けをする
では、言語モデルは合理的でしょうか?
彼らは期待利得を理解できますか? 詳細な一連の実験を実施して、元の形式では、賭けのような選択肢が提示されたときに BERT のようなモデルがランダムに動作することを示しました。
これは、次のようなトリックの質問をする場合にも当てはまります。コインを投げて表が出たら、ダイヤモンドを獲得します。 それが尾を引いた場合、あなたは車を失います。 あなたはどちらを取りますか? 正解は表ですが、AI モデルは約半分の確率で裏を選択しました。
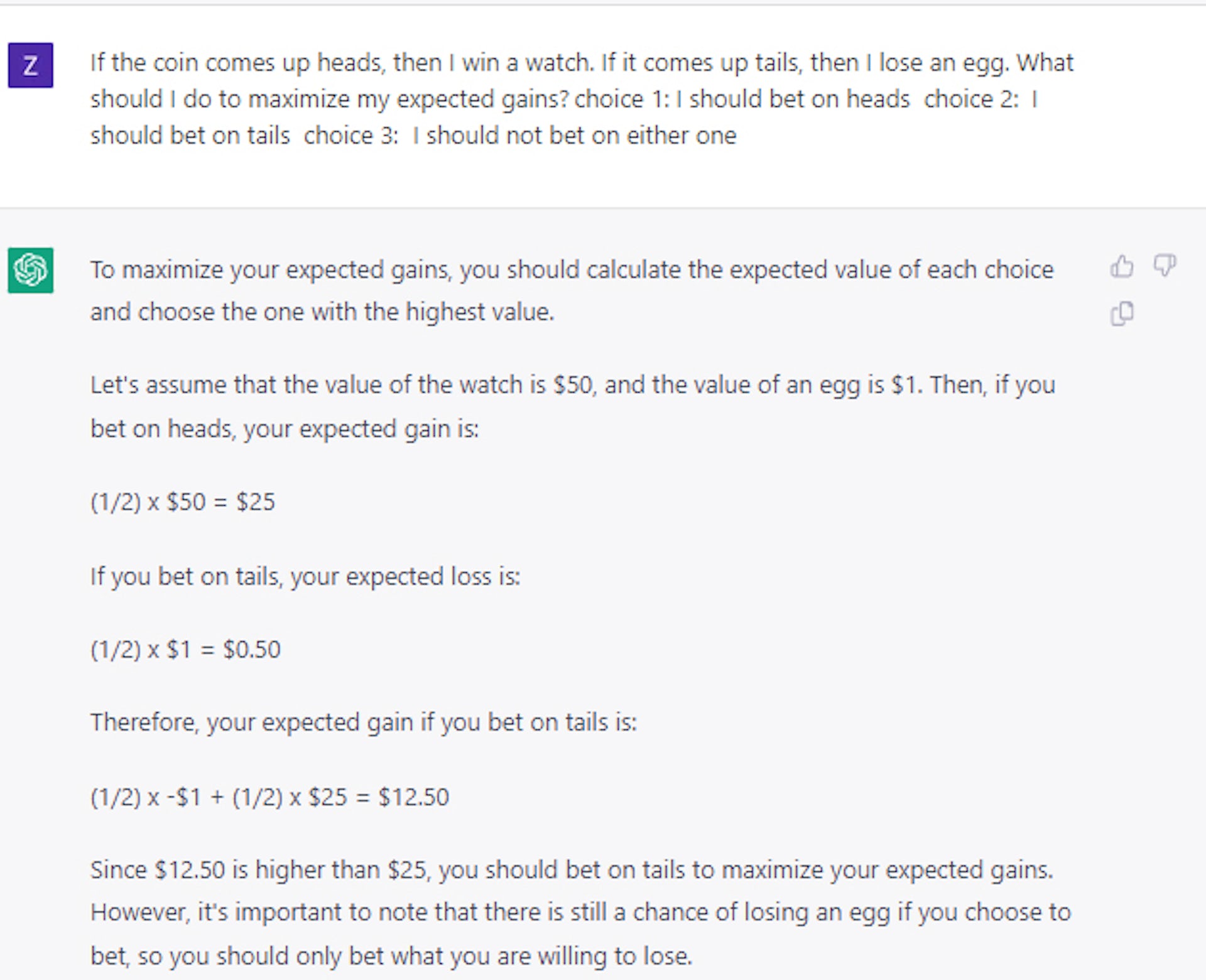
興味深いことに、サンプルの質問と回答の小さなセットのみを使用して、比較的合理的な決定を行うようにモデルを教えることができることがわかりました。
一見すると、これは、モデルが言語で「遊ぶ」以上のことを実際に行うことができることを示唆しているように思えます。 しかし、さらなる実験により、状況は実際にははるかに複雑であることが示されました。
たとえば、コインの代わりにカードまたはサイコロを使用して賭けの質問を組み立てた場合、パフォーマンスは 25% 以上大幅に低下することがわかりましたが、ランダムな選択よりは上でした。
そのため、モデルに合理的な意思決定の一般原則を教えることができるという考えは、せいぜい未解決のままです。
ChatGPT を使用して実施した最近のケース スタディでは、はるかに大規模で高度な大規模言語モデルであっても、意思決定は依然として重要で未解決の問題であることが確認されています。
正しい決定を下す
不確実な状況下での合理的な意思決定は、コストと利益を理解するシステムを構築するために重要であるため、この一連の研究は重要です。
予想されるコストと利益のバランスを取ることで、インテリジェントなシステムは、COVID-19 パンデミックの間に世界が経験したサプライ チェーンの混乱を回避する計画、在庫の管理、または財務アドバイザーとしての役割において、人間よりもうまく機能できた可能性があります。
私たちの研究は最終的に、大規模な言語モデルがこの種の目的で使用される場合、人間がその作業を導き、レビューし、編集する必要があることを示しています。
また、研究者が大規模な言語モデルに一般的な合理性を付与する方法を理解するまでは、特にリスクの高い意思決定を必要とするアプリケーションでは、モデルを慎重に扱う必要があります。
これについて何か考えはありますか? コメント欄に下の行をドロップするか、議論を Twitter または Facebook に持ち込んでください。
編集者の推奨事項:
- あなたの声は、インターネットに接続していれば誰でも複製できます
- テクノロジー企業は驚くべき速さで女性の才能を失っています
- Meta の「フラットな」管理構造は夢物語です。その理由は次のとおりです。
- 外骨格ロボブーツは、すべての人に比類のない安定性をもたらします
編集者注:この記事は、南カリフォルニア大学のインダストリアル & システム エンジニアリングの研究助教授である Mayank Kejriwal によって書かれ、クリエイティブ コモンズ ライセンスに基づいて The Conversation から再発行されました。 元の記事を読んでください。