
¿Qué es la Metodología del Aprendizaje por Refuerzo Profundo?
Publicado: 2024-02-28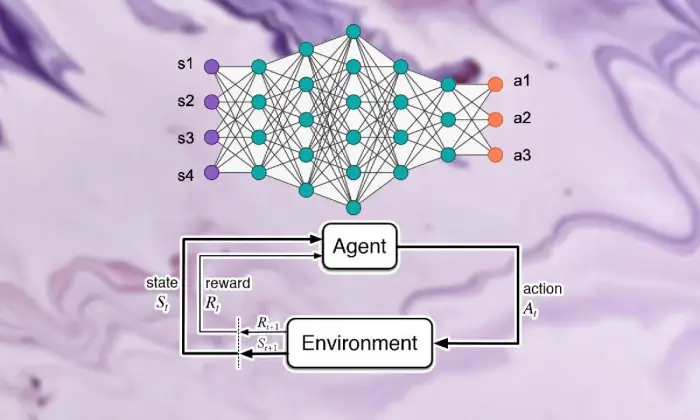
El aprendizaje por refuerzo profundo sigue estando a la vanguardia del razonamiento creado por el hombre de última generación, combinando los dominios del aprendizaje profundo y apoyando la idea de cómo capacitar a las máquinas para que aprendan de forma independiente y simplemente decidan.
El aprendizaje por refuerzo profundo (DRL) incluye preparar cálculos para conectarse con un clima y beneficiarse de las críticas como remuneraciones o castigos. Este sólido procedimiento une la fuerza emblemática de las redes cerebrales profundas con las capacidades dinámicas de los especialistas en aprendizaje de apoyo.
DRL ha ganado una enorme consideración debido a su sorprendente habilidad para manejar tareas complejas en diferentes espacios, desde juegos y tecnología mecánica hasta servicios médicos y de respaldo. Su flexibilidad y viabilidad lo convierten en una base en el ámbito del examen y la aplicación de inteligencia basada en computadora, prometiendo efectos extraordinarios en empresas y docentes.
A medida que profundizamos en las complejidades del aprendizaje por refuerzo profundo, debemos descubrir su enfoque y desentrañar su verdadera capacidad para cambiar la forma en que las máquinas ven y colaboran con su entorno general.

Fundamentos del aprendizaje por refuerzo
Emprender la excursión de ver el aprendizaje por refuerzo profundo requiere un buen manejo de los aspectos esenciales del aprendizaje de apoyo. En esencia, RL es una visión del mundo de la IA preocupada por cómo los expertos descubren cómo tomar decisiones sucesivas en un entorno para aumentar las recompensas combinadas.
Dentro del ámbito del aprendizaje de apoyo, algunas partes e ideas vitales asumen papeles esenciales en la formación de la experiencia en crecimiento. Deberíamos profundizar en estos ángulos para desentrañar la esencia del enfoque RL:
Conceptos básicos y terminología
Para comprender el aprendizaje por refuerzo profundo, inicialmente se deben aceptar las ideas esenciales y la redacción intrínseca para apoyar el aprendizaje. Estos incorporan pensamientos como estado, actividad, premio y estrategia, que estructuran los bloques estructurales de los cálculos de RL.
Componentes del aprendizaje por refuerzo
En el escenario del aprendizaje por refuerzo profundo, comprender las partes básicas del aprendizaje de apoyo es vital. El aprendizaje de apoyo contiene algunos componentes clave que dan forma a la forma en que los especialistas se conectan con sus circunstancias actuales y aprenden los sistemas ideales después de un tiempo.
Estas partes, incluido el especialista, el clima, las actividades y los premios, estructuran los bloques estructurales de los marcos de aprendizaje de apoyo. Al apreciar estos componentes esenciales, podemos adquirir conocimientos sobre cómo funcionan los cálculos del aprendizaje por refuerzo profundo y cómo se aplican para solucionar problemas dinámicos alucinantes.
Agente
El agente en el aprendizaje por refuerzo alude a la sustancia responsable de decidir y conectarse con el clima. Descubre cómo explorar el clima a la luz de encuentros previos y críticas a través de remuneraciones o castigos.
Ambiente
El entorno tipifica el marco exterior con el que colabora el especialista. Critica al especialista a medida que el Estado avanza y premia, formando la experiencia creciente.
Comportamiento
Las acciones representan las decisiones accesibles al especialista en cada momento de elección. El especialista elige las actividades debido a su estado actual y al resultado ideal, lo que significa aumentar los premios combinados a largo plazo.
Recompensas
Las recompensas actúan como instrumento de entrada para el agente, demostrando el atractivo de sus actividades. Los premios positivos fomentan formas de comportamiento deseadas, mientras que los premios negativos reprimen actividades desafortunadas.
Procesos de decisión de Markov (MDP)
Los procesos de decisión de Markov (MDP) brindan una estructura convencional para demostrar cuestiones dinámicas sucesivas en el aprendizaje por refuerzo. Forman parte de estados, actividades, probabilidades de cambio y premios, ejemplificando los elementos del clima de forma probabilística.
Comprender el aprendizaje profundo
Salir de la excursión de ver el aprendizaje por refuerzo profundo implica sumergirse en el dominio del aprendizaje profundo, una parte básica que permite realizar cálculos para separar ejemplos y representaciones complejos de la información. El aprendizaje profundo constituye la base de muchos de los mejores enfoques de su clase en el razonamiento creado por el hombre, brindando a las máquinas la capacidad de aprender conexiones complicadas y tomar decisiones refinadas.
Conceptos básicos de las redes neuronales
Para comprender la esencia del aprendizaje por refuerzo profundo, inicialmente hay que dominar los rudimentos de la organización cerebral. Las redes cerebrales personifican la construcción y la capacidad de la mente humana, involucrando capas interconectadas de neuronas que ciclan y cambian la información de entrada. Estas organizaciones son hábiles para aprender representaciones progresivas, lo que les permite captar ejemplos y elementos multifacéticos dentro de conjuntos de datos complejos.
Arquitecturas de aprendizaje profundo
En el ámbito del aprendizaje por refuerzo profundo, lo principal es comprender las complejidades de las estructuras de aprendizaje profundo. Las estructuras de aprendizaje profundas actúan como base de muchos cálculos de alto nivel, involucrando a especialistas para obtener ejemplos y representaciones complejos a partir de la información.
Al investigar estas estructuras, podemos desentrañar los componentes que permiten a los especialistas procesar y descifrar datos, trabajando con dinámicas astutas en condiciones únicas.
Redes neuronales convolucionales (CNN)
Las redes neuronales convolucionales (CNN) tienen cierta experiencia en el manejo de información similar a una red, como imágenes y grabaciones. Influyen en las capas convolucionales para eliminar elementos espaciales progresivamente, permitiéndoles realizar tareas de vanguardia como orden de imágenes, reconocimiento de objetos y división.
Redes neuronales recurrentes (RNN)
Las redes neuronales recurrentes (RNN) logran cuidar información sucesiva con condiciones transitorias, como series temporales y lenguaje regular. Tienen asociaciones intermitentes que les permiten mantenerse al día con la memoria a través de pasos de tiempo, lo que los hace apropiados para tareas como visualización del lenguaje, interpretación automática y reconocimiento del discurso.
Redes Q profundas (DQN)
Las Deep Q-Networks (DQN) abordan una ingeniería específica para ayudar a captar y consolidar redes cerebrales profundas con cálculos de Q-learning. Estas organizaciones logran superar la capacidad de valoración de la actividad, permitiéndoles tomar decisiones ideales en situaciones con espacios estatales de alto nivel.
Entrenamiento de redes neuronales
El entrenamiento de redes neuronales es una parte básica del aprendizaje por refuerzo profundo, importante para capacitar a los especialistas para que ganen y desarrollen aún más sus capacidades dinámicas. Las redes neuronales están preparadas para utilizar cálculos como la retropropagación y la caída de pendiente, que cambian los límites de la organización para limitar los errores de expectativas.
A lo largo del ciclo de preparación, la organización cuida la información y el modelo descubre de forma iterativa cómo hacer pronósticos más precisos. Al actualizar iterativamente los límites de la organización ante los errores detectados, las redes cerebrales trabajan constantemente en la presentación de la tarea encomendada. Este proceso iterativo de mejora asume un papel central en el aprendizaje por refuerzo profundo, lo que permite a los especialistas ajustar y optimizar sus sistemas a largo plazo.
Propagación hacia atrás
La retropropagación sirve como base para preparar las organizaciones cerebrales, capacitándolas para obtener información cambiando iterativamente sus límites para limitar los errores de expectativas. Este cálculo calcula las pendientes de la capacidad de desgracia para los límites de la red, trabajando con la mejora productiva a través de la caída de inclinación.
Descenso de gradiente
El descenso de gradientes es fundamental para mejorar los límites de la red cerebral, dirigiendo la experiencia educativa hacia los mínimos de la capacidad de desgracia. Al actualizar iterativamente los límites hacia la caída más pronunciada, los cálculos de caída de ángulo permiten que las organizaciones cerebrales se unan a acuerdos ideales.
Lea también: Aprendizaje profundo versus aprendizaje automático: diferencias clave
Integración del aprendizaje por refuerzo y el aprendizaje profundo
La coordinación del aprendizaje por refuerzo con el aprendizaje profundo aborda una progresión esencial en el dominio de la conciencia creada por el hombre, utilizando sinérgicamente las cualidades de los dos modelos ideales para manejar empresas dinámicas complejas con una viabilidad excepcional.
Combinación consistente de estrategias de aprendizaje profundo y aprendizaje de apoyo, que revela información sobre las inspiraciones que impulsaron su unión, las dificultades que presenta el aprendizaje de apoyo habitual que se acerca y las ventajas innovadoras que brinda la fusión de métodos de aprendizaje profundo.

Motivación para el aprendizaje por refuerzo profundo
La incorporación del aprendizaje por refuerzo profundo está impulsada por la misión de encontrar formas más versátiles, adaptables y efectivas de abordar las disposiciones ideales del aprendizaje en condiciones complejas. Los cálculos convencionales de aprendizaje por refuerzo a menudo luchan con espacios estatales de altos niveles y premios escasos, frustrando su idoneidad para problemas genuinos.
El aprendizaje profundo ofrece una respuesta al enriquecer a los especialistas en aprendizaje por refuerzo con la capacidad de obtener representaciones progresivas de fuentes de información táctil crudas, permitiéndoles extraer elementos notables y ejemplos fundamentales para la navegación.
Desafíos del aprendizaje por refuerzo tradicional
El aprendizaje por refuerzo tradicional enfrenta un montón de dificultades, que incluyen fallas en las pruebas, espacios de estado no directos y de alto nivel, y el flagelo de la dimensionalidad. Además, algunas aplicaciones certificables ofrecen recompensas escasas y pospuestas, lo que hace que sea necesario realizar cálculos de RL estándar para aprender arreglos eficaces. Estos impedimentos requieren la incorporación de métodos de aprendizaje profundo para conquistar las limitaciones intrínsecas del aprendizaje por refuerzo tradicional.
Beneficios del aprendizaje profundo en el aprendizaje por refuerzo
La consolidación del aprendizaje profundo en el aprendizaje por refuerzo presenta varias ventajas, reformando el campo y potenciando avances en diferentes áreas.
Las redes neuronales profundas permiten a los especialistas en aprendizaje por refuerzo obtener de manera efectiva mapeos complejos a partir de contribuciones tangibles y crudas a los arreglos de actividades, evitando el requisito del diseño manual de elementos.
Además, los métodos de aprendizaje profundo funcionan con la especulación de enfoques aprendidos en una variedad de condiciones, mejorando la adaptabilidad y la solidez de los algoritmos de aprendizaje por refuerzo.
Metodología del aprendizaje por refuerzo profundo
Profundizar en la filosofía del aprendizaje por refuerzo profundo descubre un rico escenario de sistemas y procedimientos destinados a preparar especialistas para tomar decisiones ideales en condiciones complejas.
Al comprender estos procedimientos, los profesionales adquieren experiencia en los componentes básicos de la experiencia de crecimiento, involucrándolos en la planificación de algoritmos de aprendizaje por refuerzo más productivos y exitosos.
A. Aprendizaje por refuerzo sin modelos versus aprendizaje por refuerzo basado en modelos
En el aprendizaje por refuerzo profundo, la decisión entre los enfoques sin modelo y basados en modelos generalmente da forma a la experiencia educativa. Sin estrategias modelo, de hecho se obtiene fácilmente la estrategia ideal, evitando así la exigencia de un modelo climático inequívoco.
Por otro lado, las técnicas basadas en modelos incluyen aprender un modelo de los elementos del clima y utilizarlo para diseñar actividades futuras. Cada enfoque disfruta de sus beneficios y compromisos, sin que las estrategias modelo logren adaptabilidad y versatilidad, mientras que las técnicas basadas en modelos ofrecen mejores ejemplos de efectividad y especulación.
Compensación entre exploración y explotación
El doble trato de la investigación se encuentra en el núcleo del aprendizaje por refuerzo, dirigiendo cómo los especialistas equilibran entre evaluar nuevas actividades para encontrar estrategias posiblemente mejores (investigación) y aprovechar la información conocida para aumentar recompensas rápidas (abuso).
Los cálculos del aprendizaje por refuerzo profundo deberían generar algún tipo de armonía entre la investigación y el abuso para aprender estrategias ideales en condiciones complejas. Se utilizan diferentes procedimientos de investigación, como las pruebas épsilon-avaricious, softmax y Thompson, para explorar esta compensación y guiar el proceso de aprendizaje.
Métodos de gradiente de políticas
Las técnicas de pendiente estratégica abordan una clase de cálculos de aprendizaje por refuerzo que simplifican directamente los límites del sistema para ampliar las recompensas esperadas. Estas estrategias definen la estrategia como una red neuronal y utilizan el aumento de pendiente para actualizar las cargas de la organización debido a los ángulos de compensaciones anticipadas para los límites de aproximación.
Las técnicas de ángulo estratégico ofrecen algunos beneficios, incluida la capacidad de lidiar con espacios de actividad ininterrumpidos y estrategias estocásticas, lo que las hace apropiadas para tareas complejas en el aprendizaje por refuerzo profundo.
Métodos de función de valor
Los métodos de capacidad de estima tienen como objetivo medir el valor de los estados o las coincidencias entre estado y actividad, brindando experiencias sobre el rendimiento normal bajo una estrategia determinada. Los cálculos de aprendizaje por refuerzo profundo suelen utilizar aproximadores de capacidad de valoración, como redes Q profundas (DQN), para obtener la capacidad de valor ideal.
Al utilizar redes neuronales profundas, las técnicas de capacidad de estimación pueden inexactar capacidades de valor complejas y funcionar con una mejora de enfoque y navegación competentes.
Métodos actor-crítico
Los métodos de actor-crítico consolidan los beneficios de la pendiente estratégica y las técnicas de capacidad de valor, utilizando organizaciones separadas de artistas y expertos para familiarizarse con la disposición y la capacidad de valor simultáneamente.
La red de actores aprende los parámetros de la política, mientras que la red crítica estima la función de valor para proporcionar retroalimentación sobre la calidad de las acciones.
Esta arquitectura permite que los métodos de actor crítico logren un equilibrio entre estabilidad y eficiencia, lo que los hace ampliamente utilizados en investigaciones y aplicaciones de aprendizaje por refuerzo profundo.
Algoritmos de aprendizaje por refuerzo profundo
Profundizar en el dominio de los algoritmos de aprendizaje por refuerzo descubre un escenario diferente de sistemas destinados a capacitar a los especialistas para que aprendan de forma independiente y se adapten a condiciones complejas. Estos cálculos abordan la fuerza de las organizaciones cerebrales profundas para inculcar a los agentes de aprendizaje por refuerzo la capacidad de explorar espacios de elección alucinantes y mejorar sus formas de comportarse después de un tiempo.
Redes Q profundas (DQN)
Deep Q-Networks (DQN) aborda un avance original en el aprendizaje por refuerzo profundo, presentando una combinación de redes neuronales profundas con cálculos de Q-learning. Al aproximar la capacidad de estimación de actividad utilizando organizaciones cerebrales, los DQN permiten a los especialistas obtener arreglos ideales de espacios estatales de alto nivel, preparándolos para avances en áreas como los juegos y la robótica.
Profundo gradiente determinista de políticas (DDPG)
Los cálculos del gradiente de política determinista profunda (DDPG) amplían los estándares de las técnicas de los expertos en entretenimiento a espacios de actividad constante, lo que permite a los especialistas aprender enfoques deterministas a través de la subida de pendientes. Al consolidar redes cerebrales profundas con el cálculo determinista de la pendiente de la estrategia, DDPG trabaja con el aprendizaje de disposiciones de control alucinantes en tareas como el control mecánico y la conducción independiente.
Optimización de políticas próximas (PPO)
Los cálculos de optimización de políticas próximas (PPO) ofrecen una forma basada en principios de abordar la racionalización de los límites de la estrategia a través de los imperativos del distrito fiduciario, garantizando actualizaciones constantes y productivas de los acuerdos. Al ampliar iterativamente los límites del sistema utilizando un aumento de ángulo estocástico, los cálculos de PPO logran una ejecución de vanguardia en diferentes puntos de referencia de aprendizaje de soporte, mostrando solidez y versatilidad en una variedad de condiciones.
Optimización de políticas de región de confianza (TRPO)
Los cálculos de optimización de políticas de región de confianza (TRPO) se centran en la estabilidad y prueban la productividad al obligar a actualizar la configuración dentro de un distrito de confianza, moderando el riesgo de grandes desviaciones estratégicas.
Al aprovechar las limitaciones de la región de confianza para guiar las actualizaciones de políticas, los algoritmos TRPO exhiben propiedades de convergencia mejoradas y solidez a las variaciones de hiperparámetros, lo que los hace muy adecuados para aplicaciones de aprendizaje por refuerzo del mundo real.
Ventaja asincrónica actor-crítico (A3C)
Los cálculos de ventaja asíncrona actor-crítico (A3C) utilizan ciclos de preparación no simultáneos para acelerar el aprendizaje y desarrollar aún más la efectividad de las pruebas en iniciativas de aprendizaje por refuerzo. Al utilizar diferentes actores iguales que se conectan con el clima de forma no simultánea, los cálculos de A3C funcionan con investigaciones más variadas y permiten a los especialistas aprender arreglos eficaces en condiciones complejas y dinámicas.
Conclusión
En definitiva, la estrategia del aprendizaje por refuerzo profundo ejemplifica una forma de múltiples niveles de abordar el empoderamiento de las máquinas para que aprendan y tomen decisiones de forma independiente en condiciones complejas. A lo largo de esta investigación, nos hemos sumergido en los conceptos básicos del aprendizaje por refuerzo, la coordinación de procedimientos de aprendizaje profundo y las diferentes formas de cálculo que impulsan los avances en este campo.
Al comprender los estándares y estrategias del centro, adquirimos conocimiento sobre la importancia del aprendizaje por refuerzo profundo en el manejo de dificultades certificables en diferentes espacios, desde mecánica avanzada y juegos hasta atención médica y dinero. Tal como lo planeamos, las puertas abiertas potenciales para avances y mejoras adicionales en el aprendizaje por refuerzo profundo son ilimitadas.
Con un examen y progresiones continuos, podemos esperar cálculos considerablemente más refinados, una adaptabilidad mejorada y una pertinencia más amplia en diferentes entornos. Para mantenerse actualizado sobre los acontecimientos más recientes y unirse a la discusión, continúe y comparta sus consideraciones y críticas en los comentarios a continuación.
Recuerde compartir estos importantes datos con sus compañeros y socios, permitiendo que otros investiguen el interesante universo del aprendizaje por refuerzo profundo. Juntos podemos impulsar el progreso y abrir la máxima capacidad de la Inteligencia Artificial.