
Quelle est la méthodologie de l’apprentissage par renforcement profond ?
Publié: 2024-02-28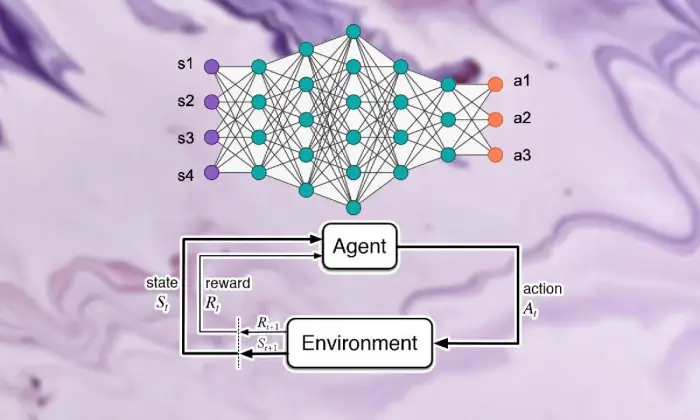
L’apprentissage par renforcement profond reste à l’avant-garde du raisonnement artificiel de pointe, mélangeant les domaines de l’apprentissage profond et aidant à trouver comment permettre aux machines d’apprendre de manière indépendante et de simplement décider.
L'apprentissage par renforcement profond (DRL) consiste à préparer des calculs pour se connecter à un climat et à tirer parti des critiques sous forme de récompenses ou de punitions. Cette procédure solide associe la force emblématique des réseaux cérébraux profonds aux capacités dynamiques des spécialistes de l’apprentissage de support.
DRL a suscité une énorme considération en raison de son habileté remarquable à gérer des missions complexes dans différents espaces, depuis les jeux et la technologie mécanique jusqu'aux services médicaux et médicaux. Sa flexibilité et sa viabilité en font une base dans le domaine de l'examen et de l'application de l'intelligence informatique, promettant des effets extraordinaires sur les entreprises et les enseignants.
À mesure que nous approfondissons les complexités de l’apprentissage par renforcement profond, nous devrions découvrir son approche et démêler sa véritable capacité à changer la façon dont les machines voient et collaborent avec leur environnement général.

Fondamentaux de l'apprentissage par renforcement
Se lancer dans l’excursion de l’apprentissage par renforcement profond nécessite une solide maîtrise des éléments essentiels de l’apprentissage de soutien. En son centre, RL est une vision du monde de l’IA qui s’intéresse à la manière dont les spécialistes parviennent à prendre des décisions successives dans un climat visant à augmenter les récompenses combinées.
Dans le domaine de l’apprentissage de soutien, quelques éléments et idées essentiels jouent un rôle essentiel dans la formation de l’expérience croissante. Nous devrions creuser ces angles pour démêler le caractère essentiel de l’approche RL :
Concepts de base et terminologie
Pour comprendre l’apprentissage par renforcement profond, il faut d’abord accepter les idées essentielles et la formulation intrinsèques pour soutenir l’apprentissage. Ceux-ci intègrent des pensées telles que l’état, l’activité, le prix et la stratégie, qui structurent les blocs structurels des calculs RL.
Composantes de l'apprentissage par renforcement
Dans le contexte de l’apprentissage par renforcement profond, il est essentiel de comprendre les éléments de base de l’apprentissage de soutien. L'apprentissage de soutien contient quelques éléments clés qui façonnent la manière dont les spécialistes se connectent à leur situation actuelle et apprennent les systèmes idéaux après un certain temps.
Ces parties, comprenant le spécialiste, le climat, les activités et les prix, structurent les blocs structurels des cadres d'apprentissage de soutien. En appréciant ces composants essentiels, nous pouvons acquérir des connaissances sur la capacité des calculs d'apprentissage par renforcement profond et comment ils sont appliqués pour résoudre des problèmes dynamiques ahurissants.
Agent
L'agent de l'apprentissage par renforcement fait allusion à la substance chargée de simplement décider et de se connecter avec le climat. Il s'agit de découvrir comment explorer le climat à la lumière des rencontres et critiques antérieures à travers des rémunérations ou des punitions.
Environnement
L'environnement caractérise le cadre extérieur avec lequel le spécialiste collabore. Il critique le spécialiste à mesure que l'État progresse et récompense, formant ainsi une expérience croissante.
Actions
Les actions représentent les décisions accessibles au spécialiste à chaque point de choix. Le spécialiste choisit les activités en raison de leur statut actuel et du résultat idéal, ce qui signifie augmenter les récompenses combinées sur le long terme.
Récompenses
Les récompenses agissent comme un instrument d'entrée pour l'agent, démontrant l'attractivité de ses activités. Les récompenses positives renforcent les comportements recherchés, tandis que les récompenses négatives freinent les activités malheureuses.
Processus décisionnels de Markov (MDP)
Les processus de décision markoviens (MDP) donnent une structure conventionnelle pour démontrer les problèmes dynamiques successifs dans l'apprentissage par renforcement. Ils comprennent des états, des activités, des probabilités de changement et des prix, illustrant les éléments du climat de manière probabiliste.
Comprendre l'apprentissage profond
Partir en excursion pour découvrir l'apprentissage par renforcement profond implique de plonger dans le domaine de l'apprentissage profond, une partie de base qui permet aux calculs de séparer les exemples et les représentations complexes des informations. L’apprentissage profond constitue le fondement de nombreuses approches de pointe en matière de raisonnement artificiel, donnant aux machines la possibilité d’apprendre des connexions complexes et de faire des choix raffinés.
Bases des réseaux de neurones
Pour comprendre la substance de l’apprentissage par renforcement profond, il faut d’abord maîtriser les rudiments de l’organisation cérébrale. Les réseaux cérébraux imitent la construction et les capacités de l'esprit humain, impliquant des couches interconnectées de neurones qui cyclent et modifient les informations d'entrée. Ces organisations sont habiles à apprendre des représentations progressives, ce qui leur permet de saisir des exemples et des éléments aux multiples facettes dans des ensembles de données complexes.
Architectures d'apprentissage profond
Dans le domaine de l’apprentissage par renforcement profond, comprendre les complexités des structures d’apprentissage profond est primordial. Des structures d'apprentissage approfondies servent de base à de nombreux calculs de haut niveau, engageant des spécialistes pour obtenir des exemples et des représentations complexes à partir d'informations.
En étudiant ces structures, nous pouvons démêler les composants qui permettent aux spécialistes de traiter et de déchiffrer les données, en travaillant avec une dynamique astucieuse dans des conditions uniques.
Réseaux de neurones convolutifs (CNN)
Les réseaux de neurones convolutifs (CNN) possèdent une certaine expertise dans le traitement des informations de type réseau, telles que les images et les enregistrements. Ils influencent les couches convolutives pour supprimer progressivement les éléments spatiaux, leur permettant ainsi d'effectuer des tâches de pointe telles que l'ordre des images, la reconnaissance d'objets et la division.
Réseaux de neurones récurrents (RNN)
Les réseaux de neurones récurrents (RNN) réussissent à prendre en charge des informations successives dans des conditions transitoires, comme les séries chronologiques et le langage régulier. Ils ont des associations intermittentes qui leur permettent de suivre la mémoire au fil du temps, ce qui les rend appropriés pour des tâches telles que l'affichage du langage, l'interprétation automatique et la reconnaissance du discours.
Réseaux Q profonds (DQN)
Les Deep Q-Networks (DQN) répondent à une ingénierie spécifique pour la prise en charge et la consolidation de réseaux cérébraux profonds avec des calculs de Q-learning. Ces organisations parviennent à améliorer la capacité de valorisation de l'activité, en leur permettant de prendre des décisions idéales dans des conditions comportant des espaces d'État à plusieurs niveaux.
Formation des réseaux de neurones
La formation des réseaux de neurones est un élément fondamental de l’apprentissage par renforcement profond, important pour permettre aux spécialistes de gagner en réalité et de développer davantage leurs capacités dynamiques. Les réseaux de neurones sont prêts à utiliser des calculs, par exemple la rétropropagation et la chute de pente, qui modifient les limites de l'organisation pour limiter les erreurs d'attente.
Tout au long du cycle de préparation, l'information est prise en charge dans l'organisation et le modèle détermine de manière itérative comment faire des prévisions plus précises. En actualisant de manière itérative les limites de l'organisation en fonction des erreurs constatées, les réseaux cérébraux travaillent régulièrement sur leur présentation de la mission donnée. Ce processus d'amélioration itératif occupe une place centrale dans l'apprentissage par renforcement profond, permettant aux spécialistes d'ajuster et de rationaliser leurs systèmes sur le long terme.
Rétropropagation
La rétropropagation constitue le fondement de la préparation des organisations cérébrales, leur permettant de tirer parti des informations en modifiant de manière itérative leurs limites afin de limiter les erreurs d'attente. Ce calcul représente les pentes de la capacité de malheur pour les limites du réseau, en travaillant avec une amélioration productive grâce à la chute d'inclinaison.
Descente graduelle
La descente de gradient est au cœur du renforcement des limites du réseau cérébral, orientant l'expérience éducative vers les minima de la capacité de malheur. En rafraîchissant de manière itérative les limites vers la chute la plus raide, les calculs de plongée en angle permettent aux organisations cérébrales de se joindre aux arrangements idéaux.
Lire aussi : Deep Learning vs Machine Learning : principales différences
Intégration de l'apprentissage par renforcement et du Deep Learning
La coordination de l'apprentissage par renforcement avec l'apprentissage profond répond à une progression essentielle dans le domaine de la conscience artificielle, en utilisant en synergie les qualités des deux modèles idéaux pour gérer des entreprises dynamiques complexes avec une viabilité exceptionnelle.
Combinaison cohérente de stratégies d'apprentissage profond et d'apprentissage de soutien, révélant un aperçu des inspirations qui motivent leur adhésion, des difficultés présentées par l'apprentissage de soutien habituel et des avantages révolutionnaires offerts par la fusion des méthodes d'apprentissage en profondeur.

Motivation pour l'apprentissage par renforcement profond
L'adhésion à l'apprentissage par renforcement profond est propulsée par la mission de trouver des moyens plus polyvalents, adaptables et efficaces de gérer les arrangements idéaux d'apprentissage dans des conditions complexes. Les calculs d’apprentissage par renforcement conventionnels se heurtent souvent à des espaces d’états à niveaux élevés et à des récompenses maigres, ce qui contrecarre leur pertinence par rapport aux problèmes réels.
L'apprentissage profond offre une réponse en enrichissant les spécialistes de l'apprentissage par renforcement de la capacité d'obtenir des représentations progressives à partir de sources d'informations tactiles brutes, leur permettant ainsi d'extraire des éléments et des exemples remarquables fondamentaux pour la navigation.
Défis de l’apprentissage par renforcement traditionnel
L'apprentissage par renforcement traditionnel est confronté à de nombreuses difficultés, notamment l'échec des tests, les espaces d'états non directs et à niveaux élevés, ainsi que le fléau de la dimensionnalité. De plus, certaines applications certifiées offrent des récompenses maigres et différées, ce qui oblige les calculs RL habituels à apprendre des arrangements puissants. Ces obstacles nécessitent l’incorporation de méthodes d’apprentissage approfondies pour vaincre les limites intrinsèques de l’apprentissage par renforcement traditionnel.
Avantages du Deep Learning dans l’apprentissage par renforcement
La consolidation de l’apprentissage profond dans l’apprentissage par renforcement présente divers avantages, réformant le domaine et permettant des progrès dans différents domaines.
Les réseaux neuronaux profonds permettent aux spécialistes de l'apprentissage par renforcement d'obtenir efficacement des cartographies complexes à partir de contributions tangibles brutes aux arrangements d'activités, en contournant l'exigence de conception manuelle d'éléments.
En outre, les méthodes d'apprentissage en profondeur fonctionnent avec la spéculation des approches apprises dans des conditions variées, améliorant ainsi l'adaptabilité et la force des algorithmes d'apprentissage par renforcement.
Méthodologie d'apprentissage par renforcement profond
En approfondissant la philosophie de l'apprentissage par renforcement profond, on découvre une riche scène de systèmes et de procédures destinés à préparer les spécialistes à faire des choix idéaux dans des conditions complexes.
En comprenant ces procédures, les professionnels acquièrent de l'expérience dans les composants de base de l'expérience croissante, les engageant à planifier des algorithmes d'apprentissage par renforcement plus productifs et plus efficaces.
A. Apprentissage par renforcement sans modèle ou basé sur un modèle
Dans l’apprentissage par renforcement profond, la décision entre les approches sans modèle et basées sur un modèle façonne généralement l’expérience éducative. Sans stratégie de modèle, on obtient en fait la stratégie idéale, en contournant l’exigence d’un modèle climatique sans équivoque.
D'un autre côté, les techniques basées sur des modèles incluent l'apprentissage d'un modèle des éléments climatiques et son utilisation pour concevoir des activités futures. Chaque approche présente ses avantages et ses compromis, sans que les stratégies de modèles réussissent en termes d'adaptabilité et de polyvalence, tandis que les techniques basées sur des modèles offrent de meilleurs exemples d'efficacité et de spéculation.
Compromis entre exploration et exploitation
Le compromis entre l'enquête et le double jeu est au cœur de l'apprentissage par renforcement, déterminant la manière dont les spécialistes équilibrent entre l'évaluation de nouvelles activités pour trouver éventuellement de meilleures stratégies (enquête) et l'exploitation d'informations connues pour augmenter les récompenses rapides (abus).
Les calculs d'apprentissage par renforcement profond devraient établir une sorte d'harmonie entre l'enquête et les abus afin d'apprendre des stratégies idéales dans des conditions complexes. Différentes procédures d'enquête, telles que les tests epsilon-avaricious, softmax et Thompson, sont utilisées pour explorer ce compromis et guider le processus d'apprentissage.
Méthodes de gradient politique
Les techniques de pente stratégique abordent une classe de calculs d’apprentissage par renforcement qui rationalisent directement les limites de l’arrangement pour élargir les récompenses attendues. Ces stratégies définissent la stratégie comme un réseau neuronal et utilisent l'augmentation de la pente pour rafraîchir les charges de l'organisation en raison des angles de compensations anticipés pour les limites de l'approche.
Les techniques d'angle stratégique offrent quelques avantages, notamment la capacité de gérer des espaces d'activité non-stop et des stratégies stochastiques, ce qui les rend appropriées pour les entreprises complexes d'apprentissage par renforcement profond.
Méthodes de fonction de valeur
Les techniques d’estime de capacité visent à évaluer la valeur des États ou des correspondances État-activité, en donnant des expériences sur le rendement normal dans le cadre d’une stratégie donnée. Les calculs d'apprentissage par renforcement profond utilisent fréquemment des approximateurs de capacité d'estime, par exemple les réseaux Q profonds (DQN), pour obtenir la capacité de valeur idéale.
En utilisant des réseaux neuronaux profonds, les systèmes de capacité de confiance peuvent évaluer les capacités de valeur complexes et fonctionner avec un développement de stratégie et une navigation efficaces.
Méthodes acteur-critique
Les méthodes d'acteur-critique consolident les avantages des techniques de pente stratégique et de capacité de valeur, en utilisant des organisations distinctes d'artistes et d'experts pour se familiariser simultanément avec le système et la capacité de valeur.
Le réseau d'acteurs apprend les paramètres politiques, tandis que le réseau critique estime la fonction de valeur pour fournir un retour sur la qualité des actions.
Cette architecture permet aux méthodes acteur-critique d’atteindre un équilibre entre stabilité et efficacité, ce qui les rend largement utilisées dans la recherche et les applications de l’apprentissage par renforcement profond.
Algorithmes d'apprentissage par renforcement profond
En explorant le domaine des algorithmes d’apprentissage par renforcement, on découvre une scène différente de systèmes destinés à permettre aux spécialistes d’apprendre de manière indépendante et de s’adapter à des conditions complexes. Ces calculs s'attaquent à la force des organisations cérébrales profondes pour inculquer aux agents d'apprentissage par renforcement la capacité d'explorer des espaces de choix ahurissants et d'améliorer leurs façons de se comporter après un certain temps.
Réseaux Q profonds (DQN)
Les Deep Q-Networks (DQN) représentent une avancée originale dans l'apprentissage par renforcement profond, présentant un mélange de réseaux neuronaux profonds avec des calculs de Q-learning. En approchant la capacité d'estime d'activité à l'aide des organisations cérébrales, les DQN permettent aux spécialistes d'obtenir des arrangements idéaux à partir d'espaces d'états de haut niveau, les préparant ainsi à faire un bond en avant dans des domaines tels que les jeux et la robotique.
Gradient politique déterministe profond (DDPG)
Les calculs de gradient politique déterministe profond (DDPG) élargissent les normes des techniques des experts du divertissement à des espaces d'activité constants, permettant aux spécialistes d'apprendre des approches déterministes par la montée de pente. En consolidant des réseaux cérébraux profonds avec le calcul de pente stratégique déterministe, DDPG travaille avec l'apprentissage de dispositions de contrôle ahurissantes dans des projets tels que le contrôle mécanique et la conduite indépendante.
Optimisation de la politique proximale (PPO)
Les calculs d’optimisation proximale des politiques (PPO) offrent un moyen fondé sur des principes de gérer les limites de la stratégie de rationalisation grâce aux impératifs des districts de confiance, garantissant ainsi une actualisation régulière et productive des arrangements. En avançant de manière itérative les limites des arrangements en utilisant l'augmentation de l'angle stochastique, les calculs PPO réalisent une exécution de pointe dans différents tests d'apprentissage de support, faisant preuve de cordialité et de polyvalence dans des conditions variées.
Optimisation des politiques de région de confiance (TRPO)
Les calculs d'optimisation de la politique de région de confiance (TRPO) se concentrent sur la stabilité et testent la productivité en obligeant à actualiser les dispositions au sein d'un district de confiance, modérant ainsi le risque d'énormes écarts stratégiques.
En tirant parti des contraintes de région de confiance pour guider les mises à jour des politiques, les algorithmes TRPO présentent des propriétés de convergence améliorées et une robustesse aux variations d'hyperparamètres, ce qui les rend bien adaptés aux applications d'apprentissage par renforcement du monde réel.
Acteur-Critique de l’Avantage Asynchrone (A3C)
Les calculs Asynchronous Advantage Actor-Critic (A3C) utilisent des cycles de préparation non simultanés pour accélérer l'apprentissage et développer davantage l'efficacité des tests dans les entreprises d'apprentissage par renforcement. En utilisant différents acteurs égaux connectés au climat de manière non simultanée, les calculs A3C fonctionnent avec des recherches plus variées et permettent aux spécialistes d'apprendre des arrangements puissants dans des conditions complexes et dynamiques.
Conclusion
Dans l’ensemble, la stratégie d’apprentissage par renforcement profond illustre une manière à plusieurs niveaux de gérer les machines qui leur permettent d’apprendre et de poursuivre leurs choix de manière indépendante dans des conditions complexes. Tout au long de cette enquête, nous avons plongé dans l'essentiel de l'apprentissage par renforcement, la coordination des procédures d'apprentissage en profondeur et les différentes démonstrations de calculs qui font progresser le domaine.
En comprenant les normes et les stratégies du centre, nous acquérons des connaissances sur l'importance de l'apprentissage par renforcement profond dans la gestion des difficultés certifiables dans différents espaces, depuis la mécanique avancée et les jeux jusqu'aux soins médicaux et à l'argent. Comme nous le prévoyons, les portes ouvertes potentielles pour des progrès et des améliorations supplémentaires dans l’apprentissage par renforcement profond sont illimitées.
Avec un examen et des progressions continus, nous pouvons nous attendre à des calculs considérablement plus raffinés, à une adaptabilité améliorée et à une pertinence plus étendue dans différents contextes. Pour rester au courant de la tournure des événements les plus récents et rejoindre la discussion, n’hésitez pas à partager vos considérations et critiques dans les remarques ci-dessous.
N'oubliez pas de transmettre ces données significatives à vos compagnons et partenaires, permettant ainsi aux autres d'explorer l'univers intéressant de l'apprentissage par renforcement profond. Ensemble, nous pouvons faire progresser le progrès et exploiter au maximum les capacités de l’intelligence artificielle.