
Qu'est-ce que le Big Data ? Pourquoi l'analyse du Big Data est-elle importante ?
Publié: 2019-11-02Depuis des siècles, les données jouent un rôle important dans nos vies. Cela dit, nous créons quotidiennement 2,5 quintillions d'octets de données. Cela signifie que 90 % des données mondiales ont été créées au cours des deux dernières années seulement. Et ce vaste ensemble de données volumineux qui est si grand qu'il ne peut pas être analysé à l'aide de méthodes traditionnelles s'appelle Big Data. Pour examiner ces données structurées et non structurées, la technique d'analyse Big Data est utilisée.
Dans cet article, nous discuterons de ce qu'est ce grand volume de données, de ce qu'est le Big Data Analytics et pourquoi est-ce important.
Qu'est-ce que le Big Data ?
- Est-ce un produit ?
- Est-ce un ensemble d'outils?
- S'agit-il d'un ensemble de données utilisé uniquement par les grandes entreprises ?
- Comment les grandes entreprises gèrent-elles les référentiels de données volumineuses ?
- Quelle est la taille de ces données ?
- Qu'est-ce que l'analyse de données volumineuses ?
- Quelle est la différence entre le big data et Hadoop ?
Ces questions et plusieurs autres nous viennent à l'esprit lorsque nous cherchons la réponse à ce qu'est le big data ? Ok, la dernière question n'est peut-être pas ce que vous demandez, mais d'autres sont une possibilité.
Par conséquent, nous définirons ici de quoi il s'agit, quel est son objectif ou sa valeur et pourquoi nous utilisons ce grand volume de données.
Aujourd'hui, les entreprises recherchent de nouvelles et meilleures façons de rester compétitives, rentables et préparées pour l'avenir, et, selon les experts du secteur, l'analyse du Big Data offre des moyens d'apprendre de nouvelles idées, d'extraire de nouvelles informations et de garder une longueur d'avance.
Le Big Data fait référence à un volume massif de données structurées et non structurées qui submerge les entreprises au quotidien. Mais ce n'est pas la taille des données qui compte, ce qui compte, c'est la façon dont elles sont utilisées et traitées. Il peut être analysé à l'aide d'analyses de données volumineuses pour prendre de meilleures décisions stratégiques pour que les entreprises déménagent.
Selon Gartner :
Les mégadonnées sont des actifs d'information à volume élevé, à grande vitesse et à grande variété qui exigent des formes de traitement de l'information rentables et innovantes pour une meilleure compréhension et une meilleure prise de décision.
Importance des mégadonnées
La meilleure façon de comprendre une chose est de connaître son histoire.
Les données existent depuis des années; mais le concept a pris de l'ampleur au début des années 2000 et depuis lors, les entreprises ont commencé à collecter des informations, à exécuter des analyses de données volumineuses pour découvrir des détails pour une utilisation future. Donnant ainsi aux organisations la capacité de travailler rapidement et de rester agiles.
C'était l'époque où Doug Laney définissait ces données comme les trois V (volume, vélocité et variété) :

Volume : c'est la quantité de données déplacées de gigaoctets à téraoctets et au-delà.
Vélocité : la vitesse de traitement des données est la vélocité.
Variété : les données sont de différents types, de structurées à non structurées. Les données structurées sont généralement numériques alors qu'elles ne sont pas structurées - texte, documents, e-mail, vidéo, audio, transactions financières, etc.
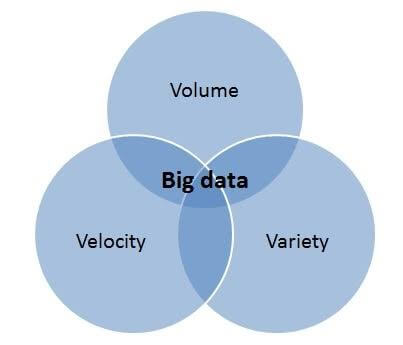
Là où ces trois V ont facilité la compréhension du Big Data, ils ont même précisé que la gestion de ce grand volume de données à l'aide du cadre traditionnel ne sera pas facile. C'était l'époque où Hadoop est né et certaines questions comme :
- Qu'est-ce qu'Hadoop ?
- Hadoop est-il un autre nom du Big Data ?
- Hadoop est-il différent du Big Data ?
Tout cela a vu le jour.
Alors, commençons à y répondre.
Big Data et Hadoop
Prenons l'analogie du restaurant comme exemple pour comprendre la relation entre le big data et Hadoop
Tom a récemment ouvert un restaurant avec un chef où il reçoit 2 commandes par jour, il peut facilement gérer ces commandes, tout comme RDBMS. Mais avec le temps, Tom a pensé à développer l'entreprise et donc à engager plus de clients, il a commencé à prendre des commandes en ligne. En raison de ce changement, le rythme auquel il recevait des commandes a augmenté et maintenant, au lieu de 2, il a commencé à recevoir 10 commandes par heure. La même chose s'est produite avec les données. Avec l'introduction de diverses sources telles que les smartphones, les médias sociaux, etc., la croissance des données est devenue énorme, mais en raison d'un changement soudain, la gestion de commandes/données volumineuses n'est pas facile. D'où la nécessité d'une stratégie différente pour faire face à ce problème.
Conscient de cette situation, Tom a commencé à réfléchir à une solution. De même, avec l'avancement de la technologie, les données ont commencé à se générer à un rythme alarmant. Pour gérer le taux énorme de commandes, Tom a embauché 4 autres chefs. Tout se passait bien mais comme l'étagère alimentaire utilisée par 4 chefs était la même, cela devenait un goulot d'étranglement, donc la solution n'était pas si efficace
De même, pour résoudre le problème des données, d'énormes ensembles de données, plusieurs unités de traitement ont été installées, mais cela n'a pas été efficace non plus car l'unité de stockage centralisée est devenue le goulot d'étranglement. Cela signifie que si l'unité centralisée tombe en panne, tout le système est compromis. Par conséquent, il était nécessaire de rechercher une meilleure solution pour les données et le restaurant.
Tom est venu avec une solution efficace, il a divisé les chefs en deux hiérarchies, c'est-à-dire le chef junior et le chef et a attribué à chaque chef junior une étagère de nourriture. Disons par exemple que le plat est une sauce pour pâtes. Maintenant, selon le plan de Tom, un chef junior préparera les pâtes et l'autre chef junior préparera la sauce. À l'avenir, ils remettront les pâtes et la sauce au chef cuisinier, où le chef cuisinier préparera la sauce pour pâtes après avoir combiné les deux ingrédients, la commande finale sera livrée. Cette solution a parfaitement fonctionné pour le restaurant de Tom et pour le Big Data, cela est fait par Hadoop.
Hadoop est un framework logiciel open source utilisé pour stocker et traiter les données de manière distribuée sur de grands clusters de matériel de base. Hadoop stocke les données de manière distribuée avec des réplications, pour fournir une tolérance aux pannes et donner un résultat final sans faire face à un problème de goulot d'étranglement. Maintenant, vous devez avoir une idée de la façon dont Hadoop résout le problème du Big Data, c'est-à-dire
- Stockage d'énormes quantités de données.
- Stockage des données dans différents formats : non structurés, semi-structurés et structurés.
- La vitesse de traitement des données.
Cela signifie-t-il que Big Data et Hadoop sont identiques ?
Nous ne pouvons pas dire cela, car il existe des différences entre les deux.
Quelle est la différence entre Big Data et Hadoop ?
- Le Big Data n'est rien de plus qu'un concept qui représente une grande quantité de données alors qu'Apache Hadoop est utilisé pour gérer cette grande quantité de données.
- Il est complexe avec de nombreuses significations alors qu'Apache Hadoop est un programme qui atteint un ensemble de buts et d'objectifs.
- Ce grand volume de données est une collection de divers enregistrements, avec plusieurs formats tandis qu'Apache Hadoop gère différents formats de données.
- Hadoop est une machine de traitement et le big data est la matière première.
Maintenant que nous savons ce que sont ces données, comment Hadoop et le big data fonctionnent. Il est temps de savoir comment les entreprises bénéficient de ces données.
Comment les entreprises profitent-elles du Big Data ?
Quelques exemples pour expliquer comment ces données volumineuses aident les entreprises à obtenir un avantage supplémentaire :
Coca Cola et les mégadonnées
Coca-Cola est une entreprise qui n'a pas besoin d'être présentée. Depuis des siècles, cette entreprise est un chef de file dans le domaine des biens de consommation emballés. Tous ses produits sont distribués dans le monde entier. Une chose qui fait gagner Coca Cola, ce sont les données. Mais comment?
Coca Cola et Big data :
En utilisant les données collectées et en les analysant via l'analyse de données volumineuses, Coca Cola est en mesure de décider des facteurs suivants :
- Sélection du bon mélange d'ingrédients pour produire des produits à base de jus
- Fourniture de produits dans les restaurants, commerces de détail, etc.
- Campagne sur les réseaux sociaux pour comprendre le comportement des acheteurs, programme de fidélité
- Création de centres de services numériques pour les achats et le processus RH
Netflix et les mégadonnées
Pour garder une longueur d'avance sur les autres services de streaming vidéo, Netflix analyse en permanence les tendances et s'assure que les gens obtiennent ce qu'ils recherchent sur Netflix. Ils recherchent des données dans :
- Programmes les plus regardés
- Tendances, montre que les clients consomment et attendent
- Visuels promotionnels, clics, temps passé à le regarder
- Appareils utilisés par les clients pour regarder ses programmes
- Ce que les téléspectateurs aiment regarder en boucle, regarder par parties, dos à dos ou une série complète.
Pour de nombreuses sociétés de streaming vidéo et de divertissement, l'analyse des mégadonnées est la clé pour fidéliser les abonnés, sécuriser les revenus et comprendre le type de contenu que les téléspectateurs aiment en fonction des emplacements géographiques. Ces données volumineuses donnent non seulement cette capacité à Netflix, mais aident même d'autres services de streaming vidéo à comprendre ce que veulent les téléspectateurs et comment Netflix et d'autres peuvent le fournir.
Parallèlement, il existe des entreprises qui stockent les données suivantes qui aident l'analyse de données volumineuses à donner des résultats précis tels que :
- Tweets enregistrés sur les serveurs de Twitter
- Informations stockées à partir du suivi des trajets en voiture par Google
- Résultats des élections locales et nationales
- Les traitements suivis et le nom de l'hôpital
- Types de cartes de crédit utilisées et achats effectués à différents endroits
- Quoi, quand les gens regardent sur Netflix, Amazon Prime, IPTV, etc. et pendant combien de temps
Hmm, c'est ainsi que les entreprises connaissent notre comportement et qu'elles conçoivent des services pour nous.
Qu'est-ce que l'analyse du Big Data ?
Le processus d'étude et d'examen de grands ensembles de données pour comprendre les modèles et obtenir des informations est appelé analyse de données volumineuses. Cela implique un processus algorithmique et mathématique pour dériver une corrélation significative. L'objectif de l'analyse des données est de tirer des conclusions basées sur ce que les chercheurs savent.
Importance de l'analyse des mégadonnées
Idéalement, les mégadonnées gèrent les prédictions/prévisions des vastes données recueillies à partir de diverses sources. Cela aide les entreprises à prendre de meilleures décisions. Certains des domaines où les données sont utilisées sont l'apprentissage automatique, l'intelligence artificielle, la robotique, la santé, la réalité virtuelle et diverses autres sections. Par conséquent, nous devons garder les données sans encombrement et organisées.
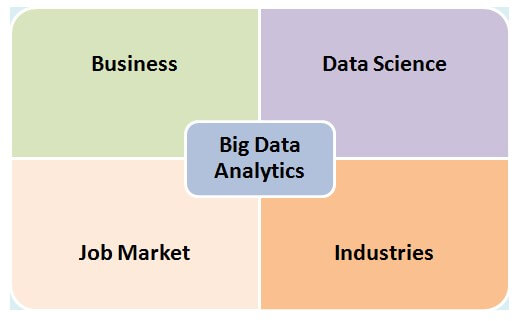
Cela donne aux organisations une chance de changer et de se développer. Et c'est pourquoi l'analyse des mégadonnées devient populaire et revêt une importance capitale. En fonction de sa nature, nous pouvons le diviser en 4 parties différentes :

En plus de cela, les données volumineuses jouent également un rôle important dans les domaines suivants :
- Identification de nouvelles opportunités
- Exploitation des données dans les organisations
- Gagner des bénéfices plus élevés et des opérations efficaces
- Commercialisation efficace
- Meilleur service client
- Avantages concurrentiels par rapport aux concurrents
Maintenant, que nous savons dans tous les domaines les données jouent un rôle important. Il est temps de comprendre le fonctionnement du big data et de ses 4 parties différentes.
Big Data Analytics et sciences des données
L'analyse des données implique l'utilisation de techniques et d'outils avancés comme l'apprentissage automatique, l'exploration de données, les statistiques. Les données ainsi extraites de différentes sources et de différentes tailles sont utilisées pour fournir une analyse.
Les sciences des données, quant à elles, sont un terme générique qui inclut les méthodes scientifiques de traitement des données. Les sciences des données combinent plusieurs domaines tels que les mathématiques, le nettoyage des données, etc. pour préparer et aligner le Big Data.

En raison des complexités impliquées, la science des données est assez difficile, mais avec la croissance sans précédent des informations générées à l'échelle mondiale, le concept de données volumineuses évolue également. Par conséquent, le domaine des sciences des données qui impliquent le big data est indissociable. Les données englobent des informations structurées et non structurées, tandis que la science des données est une approche plus ciblée qui implique des domaines scientifiques spécifiques.
Entreprises et Big Data Analytics
En raison de l'augmentation de la demande, l'utilisation d'outils d'analyse de données augmente car ils aident les organisations à trouver de nouvelles opportunités et à acquérir de nouvelles connaissances pour gérer efficacement leur entreprise.
De plus, en se concentrant sur les clients, les entreprises peuvent améliorer leurs opérations et gagner plus de profits. Des outils comme Hadoop aident à réduire les coûts de stockage. Augmenter ainsi l'efficacité de l'entreprise, ce qui, à son tour, conduit à économiser de l'argent, de l'énergie et à prendre des décisions plus rapidement.
Avantages en temps réel de l'analyse du Big Data
Au fil des ans, les données ont connu une croissance énorme en raison de laquelle l'utilisation des données a augmenté dans des secteurs allant de :
- Bancaire
- Soins de santé
- Énergie
- La technologie
- Consommateur
- Fabrication
Dans l'ensemble, l'analyse de données est devenue aujourd'hui un élément essentiel des entreprises.
Opportunités d'emploi et analyse de données volumineuses
Les données sont presque partout, il est donc urgent de collecter et de conserver toutes les données générées. C'est pourquoi l'analyse de données volumineuses se situe aux frontières de l'informatique et est devenue cruciale pour améliorer les entreprises et prendre des décisions. Les professionnels qualifiés dans l'analyse des données ont un océan d'opportunités. Car ce sont eux qui peuvent combler le fossé entre les techniques d'analyse commerciale traditionnelles et nouvelles qui aident les entreprises à se développer.
Avantages de l'analyse des mégadonnées
- Réduction des coûts
- Meilleure prise de décision
- Nouveaux produits et services
- Détection de fraude
- De meilleures informations sur les ventes
- Comprendre les conditions du marché
- Précision des données
- Tarification améliorée
Comment fonctionne l'analytique du Big Data et ses technologies clés
Aucune technologie unique ne peut englober des données volumineuses, mais l'analyse avancée des données volumineuses peut être appliquée aux données, pour tirer le meilleur parti des informations.
Voici les plus gros joueurs :
Apprentissage automatique : Apprentissage automatique, entraîne une machine à apprendre et à analyser des données plus volumineuses et plus complexes pour fournir des résultats plus rapides et précis. L'utilisation d'un sous-ensemble d'organisations d'IA d'apprentissage automatique peut identifier des opportunités rentables - en évitant les risques inconnus.
Gestion des données : les données entrant et sortant constamment de l'organisation, nous devons savoir si elles sont de haute qualité et peuvent être analysées de manière fiable. Une fois que les données sont fiables, un programme de gestion des données de référence est utilisé pour mettre l'organisation sur la même longueur d'onde et analyser les données.
Exploration de données : la technologie d'exploration de données aide à analyser les modèles de données cachés afin qu'ils puissent être utilisés dans une analyse plus approfondie pour obtenir une réponse à des questions commerciales complexes. En utilisant l'algorithme d'exploration de données, les entreprises peuvent prendre de meilleures décisions et peuvent même identifier les zones problématiques pour augmenter les revenus en réduisant les coûts. L'exploration de données est également connue sous le nom de découverte de données et découverte de connaissances.
Hadoop : Hadoop est un logiciel open source qui aide à gérer le traitement des données et le stockage des applications de données de manière organisée sur des serveurs informatiques. Hadoop est devenu une technologie clé qui prend en charge les initiatives avancées d'analyse de mégadonnées, y compris l'apprentissage automatique, l'exploration de données, etc. Le système Hadoop peut gérer différentes formes de données structurées et non structurées, ce qui donne un avantage supplémentaire pour collecter, traiter et analyser facilement les données.
Analyse en mémoire : cette méthodologie de Business Intelligence (BI) est utilisée pour résoudre des problèmes commerciaux complexes. En analysant les données de la mémoire système de l'ordinateur RAM, le temps de réponse aux requêtes peut être raccourci et des décisions commerciales plus rapides peuvent être prises. Cette technologie élimine même les frais généraux liés au stockage des tables agrégées de données ou à l'indexation des données, ce qui se traduit par un temps de réponse plus rapide. Non seulement cette analyse en mémoire aide même l'organisation à exécuter des analyses de données volumineuses itératives et interactives.
Analyse prédictive : L'analyse prédictive est la méthode d'extraction d'informations à partir de données existantes pour déterminer et prédire les résultats et tendances futurs. des techniques telles que l'exploration de données, la modélisation, l'apprentissage automatique et l'IA sont utilisées pour analyser les données actuelles afin de faire des prévisions futures. L'analyse prédictive permet aux organisations de devenir proactives, de prévoir l'avenir, d'anticiper le résultat, etc. De plus, elle va plus loin et suggère des actions pour bénéficier de la prédiction et également fournir une décision pour bénéficier de ses prédictions et de ses implications.

Exploration de texte : L'exploration de texte, également appelée exploration de données textuelles, est le processus consistant à obtenir des informations de haute qualité à partir de données textuelles non structurées. Grâce à la technologie d'exploration de texte, vous découvrez des informations que vous n'aviez pas remarquées auparavant. L'exploration de texte utilise l'apprentissage automatique et est plus pratique pour les scientifiques des données et d'autres utilisateurs pour développer des plateformes de mégadonnées et aider à analyser les données pour découvrir de nouveaux sujets.
Les défis de l'analyse des données volumineuses et les moyens de les résoudre
Une énorme quantité de données est produite chaque minute, il devient donc difficile de les stocker, de les gérer, de les utiliser et de les analyser. Même les grandes entreprises ont du mal avec la gestion et le stockage des données pour utiliser une énorme quantité de données. Ce problème ne peut pas être résolu en stockant simplement les données qui sont la raison pour laquelle les organisations doivent identifier les défis et travailler à les résoudre :
- Mauvaise compréhension et acceptation des mégadonnées
- Des informations significatives grâce à l'analyse de données volumineuses
- Stockage et qualité des données
- Sécurité et confidentialité des données
- Collecte de données significatives en temps réel : Pénurie de compétences
- Synchronisation des données
- Représentation visuelle des données
- Confusion dans la gestion des données
- Structuration de données volumineuses
- Extraction d'informations à partir de données
Avantages organisationnels du Big Data
Le Big Data n'est pas utile pour organiser les données, mais il apporte même une multitude d'avantages pour les entreprises. Les cinq premiers sont :
- Comprendre les tendances du marché : à l'aide de données volumineuses et d'analyses de données volumineuses, les entreprises peuvent facilement prévoir les tendances du marché, prédire les préférences des clients, évaluer l'efficacité des produits, les préférences des clients et mieux comprendre le comportement des clients. Ces informations aident en retour à comprendre les habitudes d'achat, les habitudes d'achat, les préférences et plus encore. Ces informations préalables aident à planifier et à gérer les choses.
- Comprendre les besoins des clients : l'analyse du Big Data aide les entreprises à comprendre et à planifier une meilleure satisfaction client. Influant ainsi sur la croissance d'une entreprise. Assistance 24 heures sur 24, 7 jours sur 7, résolution des plaintes, collecte cohérente des commentaires, etc.
- Améliorer la réputation de l'entreprise : Le Big Data aide à faire face aux fausses rumeurs, offre un meilleur service aux besoins des clients et entretient l'image de l'entreprise. À l'aide d'outils d'analyse de données volumineuses, vous pouvez analyser les émotions négatives et positives qui aident à comprendre les besoins et les attentes des clients.
- Favorise les mesures de réduction des coûts : les coûts initiaux du déploiement du Big Data sont élevés, mais les retours et les informations utiles dépassent ce que vous payez. Le Big Data peut être utilisé pour stocker les données plus efficacement.
- Rend les données disponibles : Les outils modernes de Big Data peuvent en temps réel disposer de portions de données requises à tout moment dans un format structuré et facilement lisible.
Secteurs où le Big Data est utilisé :
- Commerce de détail et commerce électronique
- Services financiers
- Télécommunications
Conclusion
Avec cela, nous pouvons conclure qu'il n'y a pas de définition spécifique de ce que sont les mégadonnées, mais nous serons tous d'accord pour dire qu'une grande quantité volumineuse de données est du mégadonnées. De plus, avec le temps, l'importance de l'analyse des mégadonnées augmente car elle contribue à améliorer les connaissances et à aboutir à une conclusion rentable.
Si vous souhaitez bénéficier du Big Data, l'utilisation de Hadoop vous aidera sûrement. Car c'est une méthode qui sait gérer le big data et le rendre compréhensible.