
Apa Metodologi Pembelajaran Penguatan Mendalam?
Diterbitkan: 2024-02-28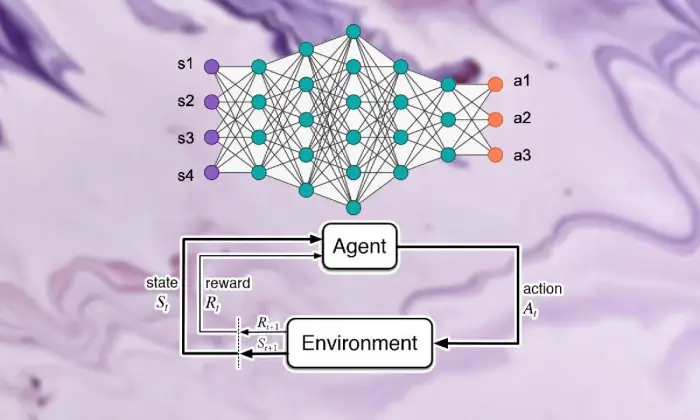
Pembelajaran penguatan mendalam tetap menjadi yang terdepan dalam penalaran buatan manusia yang canggih, memadukan domain pembelajaran mendalam dan mendukung mencari cara memberdayakan mesin untuk belajar secara mandiri dan mengambil keputusan dengan mudah.
Pembelajaran penguatan mendalam (DRL) mencakup mempersiapkan perhitungan untuk berhubungan dengan iklim dan memperoleh kritik sebagai imbalan atau hukuman. Prosedur yang kuat ini menggabungkan kekuatan simbolis dari jaringan otak yang mendalam dengan kapasitas dinamis dari spesialis pendukung pembelajaran.
DRL telah menarik perhatian besar karena keahliannya yang luar biasa dalam menangani tugas-tugas kompleks di berbagai ruang, mulai dari permainan dan teknologi mekanis hingga layanan punggung dan medis. Fleksibilitas dan kelayakannya menjadikannya landasan dalam bidang pemeriksaan dan penerapan kecerdasan berbasis komputer, sehingga menjanjikan dampak luar biasa di seluruh usaha dan guru.
Saat kita menyelami lebih jauh kompleksitas pembelajaran penguatan mendalam, kita harus mengungkap pendekatannya dan menguraikan kapasitas sebenarnya untuk mengubah cara mesin melihat dan berkolaborasi dengan lingkungan umumnya.

Dasar-dasar Pembelajaran Penguatan
Memulai perjalanan untuk melihat pembelajaran penguatan yang mendalam memerlukan pemahaman yang kuat tentang esensi pembelajaran dukungan. Pada intinya, RL adalah pandangan dunia AI yang membahas tentang bagaimana para ahli mencari cara untuk membuat keputusan berturut-turut dalam iklim untuk meningkatkan imbalan gabungan.
Dalam bidang pembelajaran pendukung, beberapa bagian dan ide penting berperan penting dalam membentuk pengalaman yang berkembang. Kita harus menggali sudut-sudut ini untuk menguraikan inti dari pendekatan RL:
Konsep Dasar dan Terminologi
Untuk memahami pembelajaran penguatan mendalam, seseorang harus terlebih dahulu menerima ide-ide penting dan kata-kata intrinsik untuk mendukung pembelajaran. Ini mencakup pemikiran seperti keadaan, aktivitas, hadiah, dan strategi, yang menyusun blok struktur perhitungan RL.
Komponen Pembelajaran Penguatan
Dalam konteks pembelajaran penguatan mendalam, memahami bagian dasar pembelajaran dukungan sangatlah penting. Pembelajaran dukungan berisi beberapa komponen utama yang membentuk cara spesialis terhubung dengan keadaan mereka saat ini dan mempelajari sistem ideal setelah beberapa waktu.
Bagian-bagian ini, termasuk spesialis, iklim, kegiatan, dan hadiah, menyusun blok struktur kerangka pembelajaran pendukung. Dengan mengapresiasi komponen-komponen penting ini, kita dapat memperoleh pengetahuan tentang seberapa dalam kemampuan perhitungan pembelajaran penguatan dan bagaimana penerapannya untuk menangani masalah dinamis yang membingungkan.
Agen
Agen dalam pembelajaran penguatan mengacu pada substansi yang bertanggung jawab untuk memutuskan dan menghubungkan dengan iklim. Pendekatan ini mencari cara untuk mengeksplorasi iklim berdasarkan pertemuan dan kritik sebelumnya melalui pemberian imbalan atau hukuman.
Lingkungan
Lingkungan melambangkan kerangka luar yang digunakan oleh spesialis untuk berkolaborasi. Ini memberikan kritik kepada spesialis seiring kemajuan dan penghargaan negara, membentuk pengalaman yang berkembang.
Tindakan
Tindakan mewakili keputusan yang dapat diakses oleh spesialis pada setiap titik pilihan. Spesialis memilih aktivitas karena statusnya saat ini dan hasil yang ideal, yang berarti meningkatkan penghargaan gabungan dalam jangka panjang.
Hadiah
Imbalan bertindak sebagai instrumen masukan bagi agen, yang menunjukkan daya tarik aktivitasnya. Hadiah positif membangun cara berperilaku yang diinginkan, sementara hadiah negatif menurunkan aktivitas yang tidak menguntungkan.
Proses Keputusan Markov (MDP)
Proses Keputusan Markov (MDPs) memberikan struktur konvensional untuk menunjukkan masalah dinamis yang berurutan dalam pembelajaran penguatan. Mereka terdiri dari negara bagian, aktivitas, probabilitas perubahan, dan hadiah, yang memberikan contoh elemen iklim secara probabilistik.
Memahami Pembelajaran Mendalam
Berangkat dari perjalanan melihat pembelajaran penguatan mendalam melibatkan penyelaman ke dalam domain pembelajaran mendalam, bagian dasar yang memungkinkan penghitungan untuk memisahkan contoh dan penggambaran kompleks dari informasi. Pembelajaran mendalam berfungsi sebagai dasar dari banyak pendekatan terbaik di kelasnya dalam penalaran buatan manusia, memberikan kemampuan pada mesin untuk mempelajari koneksi yang rumit dan mengambil pilihan yang lebih baik.
Dasar-dasar Jaringan Neural
Untuk memahami substansi pembelajaran penguatan mendalam, pertama-tama seseorang harus memahami dasar-dasar pengorganisasian otak. Jaringan otak meniru konstruksi dan kemampuan pikiran manusia, yang melibatkan lapisan neuron yang saling berhubungan yang memutar dan mengubah informasi masukan. Organisasi-organisasi ini cerdik dalam mempelajari gambaran progresif, memberdayakan mereka untuk menangkap banyak contoh dan elemen dalam kumpulan data yang kompleks.
Arsitektur Pembelajaran Mendalam
Dalam domain pembelajaran penguatan mendalam, memahami kompleksitas struktur pembelajaran mendalam adalah hal yang mendasar. Struktur pembelajaran yang mendalam bertindak sebagai dasar dari banyak perhitungan tingkat tinggi, melibatkan spesialis untuk mendapatkan contoh dan gambaran kompleks dari informasi.
Dengan menyelidiki struktur ini, kita dapat menguraikan komponen-komponen yang memberdayakan para spesialis untuk memproses dan menguraikan data, bekerja dengan dinamika yang cerdik dalam kondisi yang unik.
Jaringan Neural Konvolusional (CNN)
Jaringan Neural Konvolusional (CNN) memiliki keahlian dalam menangani informasi mirip jaringan, seperti gambar dan rekaman. Mereka mempengaruhi lapisan konvolusional untuk menghilangkan elemen spasial secara progresif, memberdayakan mereka untuk melakukan tugas-tugas mutakhir seperti urutan gambar, pengenalan objek, dan pembagian.
Jaringan Neural Berulang (RNN)
Jaringan Neural Berulang (RNN) berhasil menangani informasi yang berurutan dengan kondisi sementara, seperti deret waktu dan bahasa reguler. Mereka mempunyai asosiasi yang terputus-putus yang memungkinkan mereka untuk mengingat ingatan sepanjang waktu, menjadikannya cocok untuk tugas-tugas seperti menampilkan bahasa, interpretasi mesin, dan pengenalan wacana.
Jaringan Q Dalam (DQN)
Deep Q-Networks (DQNs) menangani rekayasa khusus untuk pengambilan dukungan, dan mengkonsolidasikan jaringan otak yang mendalam dengan perhitungan Q-learning. Organisasi-organisasi ini berhasil memanfaatkan kapasitas nilai aktivitas, memberdayakan mereka untuk membuat pilihan yang tepat dalam kondisi dengan ruang negara yang berlapis-lapis.
Pelatihan Jaringan Syaraf Tiruan
Melatih jaringan saraf adalah bagian dasar dari pembelajaran penguatan mendalam, yang penting dalam memberdayakan spesialis untuk mendapatkan keuntungan, dan mengembangkan lebih lanjut kapasitas dinamis mereka. Jaringan saraf dirancang untuk memanfaatkan perhitungan, misalnya propagasi mundur dan penurunan kemiringan, yang mengubah batas-batas organisasi untuk membatasi kesalahan ekspektasi.
Sepanjang siklus persiapan, informasi ditangani dalam organisasi, dan model secara berulang-ulang mencari cara untuk membuat perkiraan yang lebih tepat. Dengan berulang kali menyegarkan batas-batas organisasi mengingat kesalahan yang diketahui, jaringan otak terus bekerja dalam menyajikan tugas yang diberikan. Proses perbaikan yang berulang ini berperan penting dalam pembelajaran penguatan mendalam, sehingga memungkinkan para spesialis untuk menyesuaikan dan menyederhanakan sistem mereka dalam jangka panjang.
Propagasi mundur
Propagasi mundur berperan sebagai fondasi dalam mempersiapkan organisasi otak, memberdayakan mereka untuk memperoleh informasi dengan mengubah batasan mereka secara berulang untuk membatasi kesalahan ekspektasi. Perhitungan ini menggambarkan kemiringan kemampuan kerugian untuk batas-batas jaringan, bekerja dengan peningkatan produktif melalui penurunan kemiringan.
Penurunan Gradien
Penurunan gradien merupakan inti dari peningkatan batas jaringan otak, mengarahkan pengalaman pendidikan menuju kemampuan kemalangan minimum. Dengan memperbarui batasan secara berulang menuju penurunan paling curam, penghitungan sudut terjun memberdayakan organisasi otak untuk bergabung ke pengaturan yang ideal.
Baca Juga: Pembelajaran Mendalam vs Pembelajaran Mesin: Perbedaan Utama
Integrasi Pembelajaran Penguatan dan Pembelajaran Mendalam
Mengkoordinasikan pembelajaran penguatan dengan pembelajaran mendalam mengatasi kemajuan penting dalam domain kesadaran buatan manusia, secara sinergis memanfaatkan kualitas dari dua model ideal untuk menangani upaya dinamis yang kompleks dengan kelangsungan hidup yang luar biasa.

Kombinasi yang konsisten antara strategi pembelajaran mendalam dan pembelajaran dukungan, mengungkapkan wawasan tentang inspirasi yang mendorong bergabungnya mereka, kesulitan-kesulitan yang ditimbulkan oleh pembelajaran dukungan biasa semakin dekat, dan keuntungan inovatif yang diberikan oleh perpaduan metode pembelajaran mendalam.
Motivasi untuk Pembelajaran Penguatan Mendalam
Penggabungan pembelajaran penguatan mendalam didorong oleh misi untuk cara yang lebih fleksibel, mudah beradaptasi, dan efektif untuk menangani pengaturan pembelajaran yang ideal dalam kondisi yang kompleks. Perhitungan pembelajaran penguatan konvensional sering kali bertentangan dengan ruang negara yang berlapis-lapis dan hadiah yang sedikit, sehingga menggagalkan kesesuaiannya dengan masalah yang sebenarnya.
Pembelajaran mendalam menawarkan jawaban dengan memperkaya spesialis pembelajaran penguatan dengan kapasitas untuk memperoleh gambaran progresif dari sumber informasi taktil yang kasar, memberdayakan mereka untuk mengekstraksi elemen dan contoh luar biasa yang mendasar dalam navigasi.
Tantangan Pembelajaran Penguatan Tradisional
Pembelajaran penguatan tradisional menghadapi banyak kesulitan, termasuk kegagalan tes, ruang keadaan tidak langsung dan berlapis-lapis, dan momok dimensi. Selain itu, beberapa aplikasi tersertifikasi memberikan imbalan yang sedikit dan tertunda, sehingga mencoba penghitungan RL biasa untuk mempelajari pengaturan yang efektif. Hambatan ini memerlukan penggabungan metode pembelajaran mendalam untuk mengatasi keterbatasan intrinsik pembelajaran penguatan tradisional.
Manfaat Pembelajaran Mendalam dalam Pembelajaran Penguatan
Konsolidasi pembelajaran mendalam dalam pembelajaran penguatan menghadirkan berbagai keuntungan, mereformasi bidang dan memberdayakan lompatan maju di berbagai bidang.
Jaringan neural dalam memberdayakan spesialis pembelajaran penguatan untuk secara efektif mendapatkan pemetaan kompleks mulai dari kontribusi nyata yang kasar hingga pengaturan aktivitas, tanpa memerlukan perancangan elemen manual.
Selain itu, metode pembelajaran mendalam bekerja dengan spekulasi pendekatan yang dipelajari di berbagai kondisi, meningkatkan kemampuan beradaptasi dan kekuatan algoritma pembelajaran penguatan.
Metodologi Pembelajaran Penguatan Mendalam
Menggali filosofi pembelajaran penguatan mendalam akan mengungkap beragam sistem dan prosedur yang ditujukan untuk mempersiapkan spesialis untuk menentukan pilihan ideal dalam kondisi kompleks.
Dengan memahami prosedur ini, para profesional memperoleh pengalaman ke dalam komponen-komponen dasar pengalaman yang berkembang, melibatkan mereka untuk merencanakan algoritma pembelajaran penguatan yang lebih produktif dan sukses.
A. Pembelajaran Penguatan Tanpa Model vs. Berbasis Model
Dalam pembelajaran penguatan mendalam, keputusan antara model sans dan pendekatan berbasis model umumnya membentuk pengalaman pendidikan. Tanpa strategi model, kita akan langsung mendapatkan strategi yang ideal, tanpa memerlukan model iklim yang tegas.
Di sisi lain, teknik berbasis model mencakup pembelajaran model elemen iklim dan memanfaatkannya untuk merancang kegiatan di masa depan. Masing-masing pendekatan mempunyai manfaat dan kompromi, tanpa strategi model yang berhasil dalam hal kemampuan beradaptasi dan keserbagunaan, sedangkan teknik berbasis model menawarkan contoh efektivitas dan spekulasi yang lebih baik.
Pengorbanan Eksplorasi vs. Eksploitasi
Pertukaran transaksi ganda investigasi terletak pada inti pembelajaran penguatan, mengarahkan bagaimana spesialis menyeimbangkan antara mengevaluasi aktivitas baru untuk menemukan strategi yang mungkin lebih baik (investigasi) dan memanfaatkan informasi yang diketahui untuk meningkatkan imbalan yang cepat (penyalahgunaan).
Perhitungan pembelajaran penguatan yang mendalam harus menghasilkan semacam keselarasan antara penyelidikan dan pelecehan untuk mempelajari strategi ideal dalam kondisi kompleks. Prosedur investigasi yang berbeda, seperti pengujian epsilon-avaricious, softmax, dan Thompson, digunakan untuk mengeksplorasi tradeoff ini dan memandu proses pembelajaran.
Metode Gradien Kebijakan
Teknik kemiringan strategi membahas kelas perhitungan pembelajaran penguatan yang secara langsung menyederhanakan batasan pengaturan untuk memperluas imbalan yang diantisipasi. Strategi ini mendefinisikan strategi sebagai jaringan saraf dan memanfaatkan kenaikan kemiringan untuk menyegarkan beban organisasi karena sudut kompensasi yang diantisipasi untuk batas pendekatan.
Teknik sudut strategi menawarkan beberapa manfaat, termasuk kemampuan untuk menangani ruang aktivitas tanpa henti dan strategi stokastik, sehingga cocok untuk tugas kompleks dalam pembelajaran penguatan mendalam.
Metode Fungsi Nilai
Teknik kemampuan penilaian bertujuan untuk mengukur nilai negara bagian atau kecocokan aktivitas negara, memberikan pengalaman dalam pengembalian normal berdasarkan strategi tertentu. Perhitungan pembelajaran penguatan mendalam sering kali menggunakan perkiraan kemampuan nilai, misalnya, jaringan Q dalam (DQN), untuk mendapatkan kemampuan nilai yang ideal.
Dengan memanfaatkan jaringan saraf dalam, teknik kemampuan harga diri dapat menghilangkan kemampuan nilai yang kompleks dan bekerja dengan peningkatan pendekatan dan navigasi yang mahir.
Metode Aktor-Kritikus
Metode aktor-kritikus menggabungkan manfaat dari teknik kemiringan strategi dan kemampuan nilai, memanfaatkan organisasi penghibur dan pakar yang terpisah untuk memahami pengaturan dan kemampuan nilai secara bersamaan.
Jaringan aktor mempelajari parameter kebijakan, sedangkan jaringan kritikus memperkirakan fungsi nilai untuk memberikan umpan balik mengenai kualitas tindakan.
Arsitektur ini memungkinkan metode aktor-kritikus mencapai keseimbangan antara stabilitas dan efisiensi, menjadikannya banyak digunakan dalam penelitian dan aplikasi pembelajaran penguatan mendalam.
Algoritma Pembelajaran Penguatan Mendalam
Menggali ke dalam domain algoritme pembelajaran penguatan mengungkap gambaran sistem berbeda yang mengarah pada pemberdayaan spesialis untuk belajar secara mandiri dan menyesuaikan diri dengan kondisi kompleks. Perhitungan ini mengatasi kekuatan organisasi otak yang mendalam untuk menanamkan agen pembelajaran penguatan dengan kemampuan untuk mengeksplorasi ruang pilihan yang membingungkan dan meningkatkan cara mereka berperilaku setelah beberapa waktu.
Jaringan Q Dalam (DQN)
Deep Q-Networks (DQN) mengatasi kemajuan awal dalam pembelajaran penguatan mendalam, menghadirkan perpaduan jaringan saraf dalam dengan penghitungan Q-learning. Dengan memperkirakan kemampuan nilai aktivitas yang memanfaatkan organisasi otak, DQN memberdayakan para spesialis untuk mendapatkan solusi ideal dari ruang negara berlapis tinggi, membuat mereka siap untuk melakukan lompatan maju di bidang-bidang seperti game dan robotika.
Gradien Kebijakan deterministik mendalam (DDPG)
Perhitungan Gradien Kebijakan Deterministik Mendalam (DDPG) memperluas standar teknik pakar penghibur ke ruang aktivitas konstan, memberdayakan spesialis untuk mempelajari pendekatan deterministik melalui pendakian lereng. Dengan menggabungkan jaringan otak yang mendalam dengan perhitungan kemiringan strategi deterministik, DDPG bekerja dengan pembelajaran pengaturan kendali yang menakjubkan dalam tugas-tugas seperti kendali mekanis dan mengemudi mandiri.
Optimalisasi Kebijakan Proksimal (PPO)
Penghitungan Optimasi Kebijakan Proksimal (PPO) menawarkan cara yang berprinsip untuk menangani penyederhanaan batas-batas strategi melalui keharusan kepercayaan daerah, yang menjamin penyegaran pengaturan yang stabil dan produktif. Dengan memajukan batas-batas pengaturan secara berulang-ulang memanfaatkan peningkatan sudut stokastik, perhitungan PPO mencapai eksekusi mutakhir dalam tolok ukur pembelajaran dukungan yang berbeda, menunjukkan ketelitian dan keserbagunaan di berbagai kondisi.
Pengoptimalan Kebijakan Wilayah Kepercayaan (TRPO)
Penghitungan Pengoptimalan Kebijakan Wilayah Perwalian (TRPO) berfokus pada stabilitas dan menguji produktivitas dengan mewajibkan penyegaran pengaturan di dalam wilayah perwalian, sehingga mengurangi risiko penyimpangan strategi yang besar.
Dengan memanfaatkan batasan wilayah kepercayaan untuk memandu pembaruan kebijakan, algoritme TRPO menunjukkan sifat konvergensi yang ditingkatkan dan ketahanan terhadap variasi hyperparameter, menjadikannya sangat cocok untuk aplikasi pembelajaran penguatan di dunia nyata.
Aktor-Kritikus Keuntungan Asinkron (A3C)
Perhitungan Asynchronous Advantage Actor-Critic (A3C) memanfaatkan siklus persiapan yang tidak bersamaan untuk mempercepat pembelajaran dan lebih lanjut mengembangkan efektivitas tes dalam upaya pembelajaran penguatan. Dengan memanfaatkan berbagai penghibur setara yang terhubung dengan iklim secara bersamaan, perhitungan A3C bekerja dengan penyelidikan yang lebih beragam dan memberdayakan para spesialis untuk mempelajari pengaturan yang kuat dalam kondisi yang rumit dan dinamis.
Kesimpulan
Secara keseluruhan, strategi pembelajaran penguatan mendalam merupakan contoh cara berlapis untuk menangani pemberdayaan mesin untuk belajar dan mengejar pilihan secara mandiri dalam kondisi yang kompleks. Sepanjang penyelidikan ini, kami telah mendalami esensi pembelajaran penguatan, koordinasi prosedur pembelajaran mendalam, dan berbagai contoh perhitungan yang mendorong kemajuan di lapangan.
Dengan memahami standar dan strategi pusat, kami memperoleh pengetahuan tentang pentingnya pembelajaran penguatan mendalam dalam menangani kesulitan yang dapat disertifikasi di berbagai bidang, mulai dari mekanika tingkat lanjut dan permainan hingga perawatan medis dan keuangan. Sesuai rencana kami, potensi pintu terbuka untuk kemajuan dan peningkatan tambahan dalam pembelajaran penguatan mendalam tidak terbatas.
Dengan pengujian dan pengembangan yang berkelanjutan, kita dapat mengharapkan penghitungan yang jauh lebih baik, kemampuan beradaptasi yang lebih baik, dan relevansi yang lebih luas dalam berbagai situasi. Untuk tetap mengetahui perkembangan terkini dan bergabung dalam diskusi, silakan sampaikan pertimbangan dan kritik Anda dalam komentar di bawah.
Ingatlah untuk menyebarkan data penting ini kepada rekan dan mitra Anda, sehingga memungkinkan orang lain menyelidiki dunia pembelajaran penguatan mendalam yang menarik. Bersama-sama, kita dapat mendorong kemajuan dan membuka kapasitas maksimal kecerdasan buatan.