
Qual è la metodologia dell'apprendimento per rinforzo profondo?
Pubblicato: 2024-02-28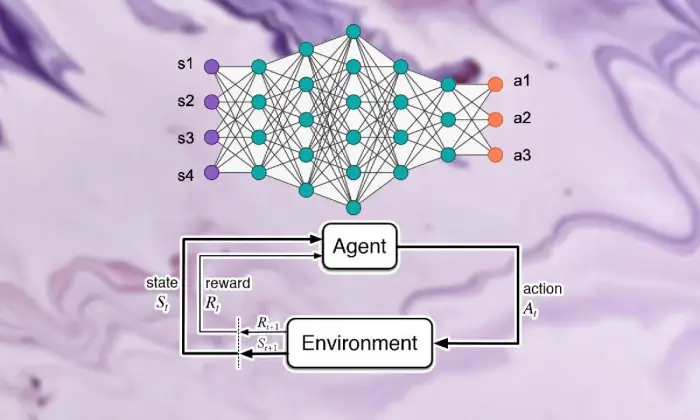
L’apprendimento profondo per rinforzo rimane all’avanguardia nel ragionamento artificiale all’avanguardia, mescolando i domini dell’apprendimento profondo e supportando la comprensione di come consentire alle macchine di apprendere in modo indipendente e decidere semplicemente.
L'apprendimento profondo per rinforzo (DRL) include la preparazione di calcoli per connettersi a un clima e trarre vantaggio dalle critiche come remunerazioni o punizioni. Questa potente procedura unisce la forza emblematica delle reti cerebrali profonde con le capacità dinamiche degli specialisti dell’apprendimento di supporto.
DRL ha guadagnato un'enorme considerazione grazie alla sua straordinaria abilità nel gestire incarichi complessi in diversi spazi, dai giochi e dalla tecnologia meccanica ai servizi medici e di assistenza. La sua flessibilità e fattibilità ne fanno una base nel campo dell’esame e dell’applicazione dell’intelligence basata su computer, promettendo effetti straordinari tra imprese e insegnanti.
Mentre ci immergiamo ulteriormente nelle complessità dell’apprendimento per rinforzo profondo, dovremmo scoprire il suo approccio e districare la sua vera capacità di cambiare il modo in cui le macchine vedono e collaborano con l’ambiente circostante.

Fondamenti dell'apprendimento per rinforzo
Partire per l’escursione alla scoperta dell’apprendimento di rinforzo profondo richiede una forte conoscenza degli elementi essenziali dell’apprendimento di supporto. Al centro, RL è una visione del mondo dell’intelligenza artificiale preoccupata di come gli specialisti riescono a decidere come decidere le scelte successive in un clima per aumentare le ricompense combinate.
All'interno del dominio dell'apprendimento di supporto, alcune parti e idee vitali assumono parti essenziali nella formazione dell'esperienza di crescita. Dovremmo approfondire questi aspetti per districare il nocciolo dell’approccio RL:
Concetti di base e terminologia
Per comprendere l’apprendimento per rinforzo profondo, è necessario inizialmente accettare le idee essenziali e le parole intrinseche al supporto dell’apprendimento. Questi incorporano pensieri come stato, attività, premio e strategia, che strutturano i blocchi strutturali dei calcoli RL.
Componenti dell'apprendimento per rinforzo
Nel contesto dell’apprendimento per rinforzo profondo, comprendere le parti fondamentali dell’apprendimento di supporto è vitale. L'apprendimento di supporto contiene alcuni componenti chiave che modellano il modo in cui gli specialisti si collegano alle loro circostanze attuali e apprendono i sistemi ideali dopo un po' di tempo.
Queste parti, inclusi lo specialista, il clima, le attività e i premi, strutturano i blocchi strutturali dei quadri di supporto dell’apprendimento. Apprezzando questi componenti essenziali, possiamo acquisire conoscenze su come la capacità di calcolo dell'apprendimento per rinforzo profondo e su come vengono applicati per risolvere problemi dinamici sbalorditivi.
Agente
L'agente nell'apprendimento per rinforzo si riferisce alla sostanza responsabile semplicemente della decisione e della connessione con il clima. Capisce come esplorare il clima alla luce degli incontri e delle critiche precedenti attraverso ricompense o punizioni.
Ambiente
L'ambiente caratterizza la struttura esterna con cui lo specialista collabora. Critica lo specialista man mano che lo Stato avanza e premia, formando l'esperienza in crescita.
Azioni
Le azioni rappresentano le decisioni accessibili allo specialista in ogni punto di scelta. Lo specialista sceglie le attività in base al loro stato attuale e al risultato ideale, il che significa aumentare i premi combinati nel lungo periodo.
Premi
I premi fungono da strumento di input per l'agente, dimostrando l'attrattiva delle sue attività. I premi positivi creano modi di comportarsi desiderati, mentre i premi negativi reprimono le attività sfortunate.
Processi decisionali di Markov (MDP)
I processi decisionali di Markov (MDP) forniscono una struttura convenzionale per dimostrare i successivi problemi dinamici nell'apprendimento per rinforzo. Comprendono stati, attività, probabilità di cambiamento e premi, esemplificando gli elementi del clima in modo probabilistico.
Comprendere l'apprendimento profondo
Partire per l'escursione dell'apprendimento profondo con rinforzo implica immergersi nel dominio dell'apprendimento profondo, una parte fondamentale che consente ai calcoli di separare esempi e rappresentazioni complesse dalle informazioni. L’apprendimento profondo funge da base per molti dei migliori approcci al ragionamento creato dall’uomo, dando la capacità alle macchine di apprendere connessioni complicate e di compiere scelte raffinate.
Nozioni di base sulle reti neurali
Per comprendere la sostanza dell’apprendimento per rinforzo profondo, è necessario inizialmente padroneggiare i rudimenti dell’organizzazione cerebrale. Le reti cerebrali impersonano la costruzione e le capacità della mente umana, coinvolgendo strati interconnessi di neuroni che ciclano e modificano le informazioni di input. Queste organizzazioni sono abili nell’apprendere rappresentazioni progressive, consentendo loro di cogliere esempi ed elementi multiformi all’interno di set di dati complessi.
Architetture di apprendimento profondo
Nel campo dell’apprendimento per rinforzo profondo, comprendere le complessità delle strutture di apprendimento profondo è fondamentale. Strutture di apprendimento profonde fungono da fondamento di molti calcoli di alto livello, coinvolgendo gli specialisti per ottenere esempi e rappresentazioni complessi dalle informazioni.
Investigando queste strutture, possiamo districare i componenti che consentono agli specialisti di elaborare e decifrare i dati, lavorando con dinamiche astute in condizioni uniche.
Reti neurali convoluzionali (CNN)
Le reti neurali convoluzionali (CNN) hanno una certa esperienza nella gestione di informazioni di tipo rete, come immagini e registrazioni. Influenzano i livelli convoluzionali per rimuovere progressivamente gli elementi spaziali, consentendo loro di eseguire compiti all'avanguardia come l'ordine delle immagini, il riconoscimento degli oggetti e la divisione.
Reti neurali ricorrenti (RNN)
Le reti neurali ricorrenti (RNN) riescono a prendersi cura di informazioni successive con condizioni transitorie, come serie temporali e linguaggio regolare. Hanno associazioni intermittenti che consentono loro di tenere il passo con la memoria attraverso passaggi temporali, rendendoli adatti per compiti come la visualizzazione del linguaggio, l'interpretazione automatica e il riconoscimento del discorso.
Reti Q profonde (DQN)
Le Deep Q-Networks (DQN) affrontano un'ingegneria specifica per la raccolta di supporto e il consolidamento delle reti cerebrali profonde con calcoli di Q-learning. Queste organizzazioni capiscono come sviluppare la capacità di stima delle attività, consentendo loro di scegliere scelte ideali in condizioni con spazi statali ad alto livello.
Addestramento delle reti neurali
L'addestramento delle reti neurali è una parte fondamentale dell'apprendimento per rinforzo profondo, significativo nel consentire agli specialisti di acquisire di fatto e sviluppare ulteriormente le proprie capacità dinamiche. Le reti neurali sono in grado di utilizzare calcoli come la backpropagation e il gradiente di pendenza, che modificano i confini dell'organizzazione per limitare gli errori di previsione.
Durante tutto il ciclo di preparazione, le informazioni vengono gestite all'interno dell'organizzazione e il modello capisce in modo iterativo come effettuare previsioni più precise. Aggiornando iterativamente i confini dell'organizzazione in caso di errori notati, le reti cerebrali lavorano costantemente sulla presentazione del compito assegnato. Questo corso iterativo di miglioramento assume un ruolo centrale nell’apprendimento per rinforzo profondo, consentendo agli specialisti di adattare e ottimizzare i propri sistemi a lungo termine.
Propagazione all'indietro
La backpropagation costituisce il fondamento della preparazione delle organizzazioni cerebrali, consentendo loro di trarre vantaggio dalle informazioni modificando iterativamente i propri confini per limitare gli errori di aspettativa. Questo calcolo calcola le pendenze della capacità di sfortuna per i confini della rete, lavorando con il miglioramento produttivo attraverso il calo di inclinazione.
Discesa gradiente
La discesa del gradiente è alla base del potenziamento dei confini della rete cerebrale, indirizzando l’esperienza educativa verso i minimi della capacità di sfortuna. Aggiornando ripetutamente i confini verso il crollo più ripido, i calcoli dell'inclinazione angolare consentono alle organizzazioni cerebrali di unirsi a soluzioni ideali.
Leggi anche: Deep Learning e Machine Learning: differenze chiave
Integrazione di apprendimento per rinforzo e apprendimento profondo
Il coordinamento dell’apprendimento per rinforzo con l’apprendimento profondo affronta una progressione essenziale nel dominio della coscienza creata dall’uomo, utilizzando sinergicamente le qualità dei due modelli ideali per gestire imprese dinamiche complesse con una fattibilità eccezionale.

Combinazione coerente di strategie di deep learning e apprendimento di supporto, che rivela informazioni sulle ispirazioni che guidano la loro adesione, sulle difficoltà presentate dall’avvicinarsi dell’apprendimento di supporto consueto e sui vantaggi innovativi dati dalla fusione di metodi di apprendimento profondo.
Motivazione per l'apprendimento profondo per rinforzo
L’unione dell’apprendimento per rinforzo profondo è spinta dalla missione di trovare modi più versatili, adattabili ed efficaci per affrontare le modalità ideali di apprendimento in condizioni complesse. I calcoli convenzionali dell’apprendimento per rinforzo spesso combattono con spazi di stati ad alto livello e premi magri, vanificando la loro adeguatezza a problemi autentici.
L’apprendimento profondo offre una risposta arricchendo gli specialisti dell’apprendimento per rinforzo con la capacità di ottenere rappresentazioni progressive da fonti di informazioni tattili grezze, consentendo loro di districare elementi notevoli ed esempi fondamentali per la navigazione.
Sfide dell'apprendimento per rinforzo tradizionale
L’apprendimento per rinforzo tradizionale deve affrontare un sacco di difficoltà, tra cui il fallimento dei test, spazi di stati non diretti e ad alti livelli e il flagello della dimensionalità. Inoltre, alcune applicazioni certificabili offrono ricompense magre e ritardate, costringendo a dover eseguire calcoli RL consueti per apprendere soluzioni efficaci. Questi ostacoli richiedono l’incorporazione di metodi di apprendimento profondo per superare i limiti intrinseci dell’avvicinarsi dell’apprendimento per rinforzo tradizionale.
Vantaggi del Deep Learning nell'apprendimento per rinforzo
Il consolidamento dell’apprendimento profondo nell’apprendimento per rinforzo presenta vari vantaggi, riformando il campo e consentendo progressi in diverse aree.
Le reti neurali profonde consentono agli specialisti dell'apprendimento per rinforzo di ottenere in modo efficace mappature complesse da semplici contributi tangibili all'organizzazione delle attività, aggirando la necessità di progettazione manuale degli elementi.
Inoltre, i metodi di apprendimento profondo funzionano con la speculazione di approcci appresi in condizioni assortite, migliorando l’adattabilità e la forza degli algoritmi di apprendimento per rinforzo.
Metodologia dell'apprendimento per rinforzo profondo
Scavando nella filosofia dell’apprendimento per rinforzo profondo si scopre una ricca scena di sistemi e procedure volti a preparare gli specialisti a stabilire scelte ideali in condizioni complesse.
Comprendendo queste procedure, i professionisti acquisiscono esperienza nei componenti fondamentali dell'esperienza in crescita, coinvolgendoli nella pianificazione di algoritmi di apprendimento per rinforzo più produttivi e di successo.
A. Apprendimento per rinforzo senza modelli e apprendimento per rinforzo basato su modelli
Nell’apprendimento per rinforzo profondo, la decisione tra approcci senza modello e basati su modelli generalmente modella l’esperienza educativa. Senza strategie modello, si ottiene direttamente la strategia ideale come dato di fatto, aggirando la necessità di un modello inequivocabile del clima.
D'altro canto, le tecniche basate su modelli includono l'apprendimento di un modello degli elementi del clima e il suo utilizzo per progettare attività future. Ciascun approccio gode dei suoi vantaggi e dei suoi compromessi, senza che le strategie modello riescano ad adattarsi e a essere versatili, mentre le tecniche basate su modelli offrono migliori esempi di efficacia e speculazione.
Il compromesso tra esplorazione e sfruttamento
Il compromesso del doppio gioco dell’indagine è al centro dell’apprendimento per rinforzo, indirizzando il modo in cui gli specialisti si bilanciano tra la valutazione di nuove attività per trovare strategie possibilmente migliori (indagine) e l’utilizzo di informazioni note per aumentare ricompense rapide (abuso).
I calcoli dell’apprendimento per rinforzo profondo dovrebbero trovare una sorta di armonia tra indagine e abuso per apprendere strategie ideali in condizioni complesse. Diverse procedure di indagine, come i test epsilon-avaricious, softmax e Thompson, vengono utilizzate per esplorare questo compromesso e guidare il processo di apprendimento.
Metodi del gradiente politico
Le tecniche di pendenza strategica riguardano una classe di calcoli di apprendimento di rinforzo che semplificano facilmente i confini della disposizione per espandere i premi attesi. Questi metodi definiscono il piano come una rete neurale e utilizzano l'aumento della pendenza per aggiornare i carichi aziendali a causa degli angoli di compensazione previsti per i confini di approccio.
Le tecniche dell’angolo strategico offrono alcuni vantaggi, inclusa la capacità di gestire spazi di attività non-stop e strategie stocastiche, rendendole adatte per imprese complesse nell’apprendimento per rinforzo profondo.
Metodi della funzione valore
Le tecniche di stima della capacità mirano a valutare il valore degli stati o gli abbinamenti tra attività statali, inserendo esperienze nel rendimento normale nell'ambito di un determinato approccio. I calcoli dell'apprendimento per rinforzo profondo utilizzano spesso approssimatori della capacità di stima, ad esempio reti Q profonde (DQN), per ottenere la capacità di valore ideale.
Utilizzando reti neurali profonde, le tecniche di capacità di stima possono inesatta capacità di valore complesse e funzionano con un miglioramento dell'approccio e della navigazione abili.
Metodi attore-critico
I metodi attore-critico consolidano i vantaggi sia della pendenza strategica che delle tecniche di capacità di valore, utilizzando organizzazioni separate di intrattenitori ed esperti per acquisire familiarità con la disposizione e la capacità di valore contemporaneamente.
La rete di attori apprende i parametri politici, mentre la rete di critici stima la funzione valore per fornire feedback sulla qualità delle azioni.
Questa architettura consente ai metodi attore-critici di raggiungere un equilibrio tra stabilità ed efficienza, rendendoli ampiamente utilizzati nella ricerca e nelle applicazioni di apprendimento per rinforzo profondo.
Algoritmi di apprendimento per rinforzo profondo
Scavando nel dominio degli algoritmi di apprendimento per rinforzo si scopre una scena diversa di sistemi mirati a consentire agli specialisti di apprendere e adattarsi in modo indipendente a condizioni complesse. Questi calcoli affrontano la forza delle organizzazioni cerebrali profonde per instillare negli agenti dell’apprendimento per rinforzo la capacità di esplorare spazi di scelta sbalorditivi e migliorare i loro modi di comportarsi dopo un po’ di tempo.
Reti Q profonde (DQN)
Le Deep Q-Networks (DQN) rappresentano un progresso originale nell'apprendimento per rinforzo profondo, presentando un mix di reti neurali profonde con calcoli di Q-learning. Approssimando la capacità di stima dell'attività utilizzando le organizzazioni cerebrali, i DQN consentono agli specialisti di ottenere disposizioni ideali da spazi statali ad alto livello, rendendoli pronti per il balzo in avanti in aree come i giochi e la robotica.
Gradiente politico deterministico profondo (DDPG)
I calcoli del Deep Deterministic Policy Gradient (DDPG) ampliano gli standard delle tecniche degli esperti di intrattenimento a spazi di attività costanti, consentendo agli specialisti di apprendere approcci deterministici attraverso la salita in pendenza. Consolidando profonde reti cerebrali con il calcolo deterministico della pendenza della strategia, DDPG lavora con l'apprendimento di modalità di controllo sbalorditive in attività come il controllo meccanico e la guida autonoma.
Ottimizzazione della politica prossimale (PPO)
I calcoli di ottimizzazione della politica prossimale (PPO) offrono un modo basato su principi per gestire la razionalizzazione dei confini della strategia attraverso gli imperativi del distretto fiduciario, garantendo aggiornamenti costanti e produttivi delle disposizioni. Avanzando in modo iterativo i limiti della disposizione utilizzando l'aumento dell'angolo stocastico, i calcoli PPO realizzano un'esecuzione all'avanguardia in diversi benchmark di apprendimento di supporto, mostrando cordialità e versatilità in condizioni diverse.
Ottimizzazione delle politiche della regione fiduciaria (TRPO)
I calcoli TRPO (Trust Region Policy Optimization) si concentrano sulla stabilità e sulla produttività dei test obbligando gli aggiornamenti delle disposizioni all'interno di un distretto fiduciario, moderando il rischio di enormi deviazioni strategiche.
Sfruttando i vincoli della regione di fiducia per guidare gli aggiornamenti delle politiche, gli algoritmi TRPO mostrano proprietà di convergenza e robustezza migliorate rispetto alle variazioni degli iperparametri, rendendoli adatti per applicazioni di apprendimento per rinforzo nel mondo reale.
Vantaggio asincrono attore-critico (A3C)
I calcoli Asynchronous Advantage Actor-Critic (A3C) utilizzano cicli di preparazione non simultanei per accelerare l'apprendimento e sviluppare ulteriormente l'efficacia dei test nelle attività di apprendimento di rinforzo. Utilizzando diversi attori uguali che interagiscono con il clima in modo non simultaneo, i calcoli A3C funzionano con indagini più assortite e consentono agli esperti di apprendere soluzioni efficaci in condizioni complesse e dinamiche.
Conclusione
Nel complesso, la strategia dell’apprendimento per rinforzo profondo esemplifica un modo a più livelli di gestire il potenziamento delle macchine affinché apprendano e perseguano scelte in modo indipendente in condizioni complesse. Nel corso di questa indagine, ci siamo immersi negli elementi essenziali dell'apprendimento per rinforzo, nel coordinamento dei processi di apprendimento profondo e nelle diverse tipologie di calcoli che guidano i progressi nel campo.
Comprendendo gli standard e le strategie del centro, acquisiamo conoscenza dell'importanza dell'apprendimento per rinforzo profondo nella gestione di difficoltà certificabili in diversi spazi, dalla meccanica avanzata e dai giochi alle cure mediche e al denaro. Come pianifichiamo, le potenziali porte aperte per ulteriori avanzamenti e miglioramenti nell’apprendimento per rinforzo profondo sono illimitate.
Con un esame e una progressione continui, possiamo aspettarci calcoli notevolmente più raffinati, una migliore adattabilità e una pertinenza più ampia in contesti diversi. Per rimanere aggiornato sugli sviluppi più recenti degli eventi e partecipare alla discussione, vai avanti e condividi le tue considerazioni e critiche nei commenti seguenti.
Ricorda di condividere questi dati significativi con i tuoi compagni e partner, consentendo ad altri di indagare sull'interessante universo dell'apprendimento per rinforzo profondo. Insieme possiamo guidare il progresso e sfruttare al massimo le capacità dell’intelligenza artificiale.