
データマスキングに関する完全ガイド
公開: 2020-03-04データマスキングとは何ですか?
データマスキングは、元のデータを変更されたデータでマスカレードまたは非表示にするプロセスです。 この場合、形式は同じままで、値のみが変更されます。 これは構造的には同じですが、ユーザートレーニングまたはソフトウェアテストに間違ったバージョンのデータが使用されています。 さらに、主な原因は、実際のデータが不要な場合に安全に保つことです。
組織は本番データを安全に保つための厳しい規則や規制を持っていますが、データのアウトソーシングの場合、トラブルが発生する可能性があります。 そのため、ほとんどの企業はデータを公開することに抵抗を感じています。
- 意味
- データマスキングを使用するのは誰ですか?
- タイプ
- 実行するツール
- 知っておくべきテクニック
- データマスキングの例
データマスキングを使用するのは誰ですか?
一般データ保護要件(GDPR)に準拠するために、企業は、本番データのセキュリティを確保するためにデータマスキングを適用することに関心を示しています。 GDPRの規則と規制によれば、EU市民からデータを受け取るすべての企業は、問題の機密性を十分に認識し、不便を避けるためにいくつかの措置を講じる必要があります。
したがって、企業が機密データを安全に保つことが主流になることは避けられません。 一方、使用できるデータにはさまざまな種類がありますが、ビジネス分野で最も頻繁に使用されるのは次のとおりです。
- 保護された健康情報(PHI)
- 知的財産(ITAR)
- ペイメントカード情報PCI-DSS
上記の例はすべて、従わなければならない義務の下にあります。
データマスキングの種類
データマスキングは、本番以外のユーザーがデータにアクセスできないようにするために適用される特別な手法です。 組織の間で人気が高まっており、その背後にある理由は、サイバーセキュリティの脅威が増大していることです。 したがって、このデータの脅威に対処するために、マスキング手法が適用されます。 同じ原因で機能するタイプは異なりますが、進行方法は異なります。 現在、2つの主要なタイプがあります。1つは静的で、もう1つは動的です。
静的データマスキング
静的データマスキングの場合、データベースの複製が作成され、偽造またはマスクされるフィールドを除いて、実際のデータベースと同じです。 このダミーコンテンツは、実際のテスト時のデータベースの動作には影響しません。
動的データマスキング
動的データマスキングでは、重要な情報はリアルタイムでのみ変更されます。 したがって、元のデータはユーザーにのみ表示され、非特権ユーザーにはダミーデータのみが表示されます。
上記はデータマスキングの主なタイプですが、以下のタイプも使用されます。
統計データの難読化
会社の生産データは、統計と呼ばれるさまざまな数値を持っています。 これらの統計のマスカレードは、統計データの難読化と呼ばれます。 非本番ユーザーは、このタイプのデータマスキングで実際の統計を推定することはできません。
オンザフライのデータマスキング
オンザフライのデータマスキングは、環境から環境へのデータ転送が行われる場所に適用されます。 このタイプは、高度に統合されたアプリケーションの継続的デプロイを実行する環境に明確に適しています。
データマスキングツール
テクノロジーは日々継続的に開発されており、さまざまな問題の解決策が変更されていることは誰もが知っています。 そのため、利用可能なツールによって、効率と作業品質がさらに向上した新しいロットが追加されました。 したがって、ここでは、実行に使用される最新のデータマスキングソリューションまたはツールをいくつか紹介します。
- DATPROFデータマスキングツール
- IRIフィールドシールド(構造化データマスキング)
- Oracleデータのマスキングとサブセット化。
- IBM INFO SPHERE OptimDataのプライバシー
- Delphix
- Microsoft SQLServerデータマスキング
- 情報永続データマスキング
ツールの詳細を次の表に示します。
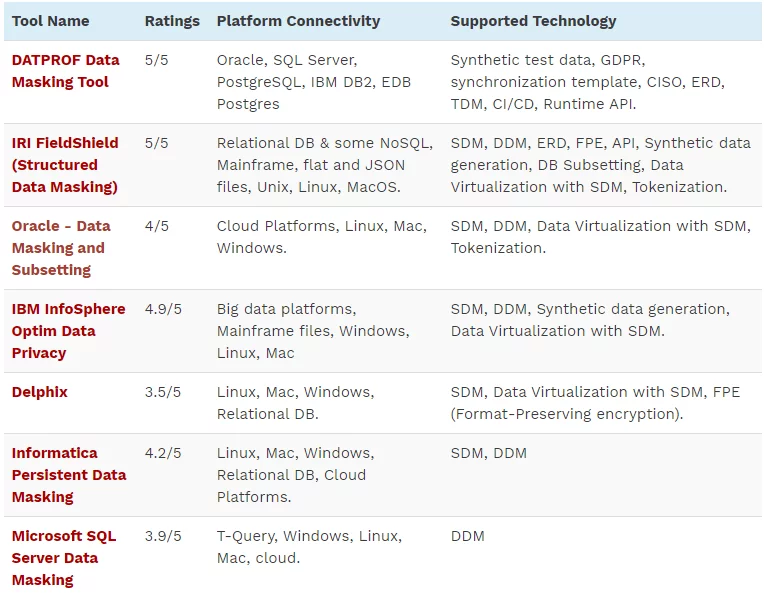
ソース:https://www.softwaretestinghelp.com/data-masking-tools/

したがって、これらは有名なツールであり、データマスキングソリューションまたはデータマスキング戦略とも呼ばれます。
データマスキング技術
機会を利用するために適用される多くの技術があります。 時間の経過とともに、課題は大きくなり、ソリューションも多様化しています。
以前は、適用された手法はほとんどありませんでしたが、現在は実装できる手法がいくつかあります。 さらに、ユーザーの目的は、与えられたすべての手法を使用して十分に機能しますが、手法が異なると機能が異なる場合があります。 したがって、最も有名なデータマスキング手法のいくつかを以下に示します。
シャッフリング
これは最も頻繁に使用される手法の1つです。 この手法では、データは列内でシャッフルされます。 ただし、シャッフルコードを解読することでシャッフルを元に戻すことができるため、これはハイプロファイルデータには使用されません。
暗号化
これは最も複雑な手法です。 通常、暗号化では、ユーザーは元のデータを表示するためのキーを作成する必要があります。 ただし、元のデータを閲覧する権限のない人に鍵を渡すと、深刻な問題が発生する可能性があります。
数と日付の差異
数値変更戦略は、金銭関連および日付駆動型のフィールドに適用するのに役立ちます。
マスキングアウト
この手法では、データ全体がマスクされません。 マスクされている特定の統計があるため、元の値を把握できません。
無効化または削除
この手法は、さまざまなデータ要素の可視性を回避するためにのみ使用されます。 これは、データマスキングを適用するために使用できる最も簡単な手法です。 ただし、可視データを見つけるために、リバースエンジニアリング手法を適用できます。 したがって、機密データにはあまり適していません。
追加の複雑なルール
追加の複雑なルールをテクニックと呼ぶことはできません。 ただし、これらは、許可されていないユーザーからの侵入に対して無敵にするために、あらゆる種類のマスキングに適用できるルールです。 これらのルールには、行の内部同期ルール、列の内部同期ルールなどが含まれます。
置換
これは、最適なマスキング手法です。 この手法では、元のデータを偽装するために、本物の統計値のいずれかが追加されます。 このようにして、本物ではないユーザーはその値を疑わしく感じることはなく、データも保持されたままになります。 この手法は、機密情報を隠す必要があるほとんどの場合に適用されます。
データマスキングの例
さまざまなツールやソフトウェアがあり、使用するツールやソフトウェアによって例も異なります。 さらに、データのマスキングは、上記のすべてのツールを使用して静的または動的に実行できます。 結果はどちらの場合も同じになります。
以前は、ほとんどの企業がこのシステムを使用していませんでしたが、当面の間、オラクルのデータマスキングを使用して非本番ユーザーから情報を保護している114の大規模な組織が米国にあります。 さらに、セキュリティを危険にさらすことはできないため、このテクノロジーを採用する傾向のある企業の数は今後も増え続けるでしょう。
最終的な考え
記事全体を読んだことで、感度と重要性を理解できました。 したがって、さらに改善するために、ここでは、最後の言葉として、データマスキングの最良の方法について説明します。
データの検索
これは、機密性が高く、マスクする必要があると思われるデータを見つける必要がある最初のステップです。
適切なテクニックを見つける
データの性質を確認した後、上記の記事で示した手法のいずれかを選択できます。 状況を考慮して、適切なマスキング手法を見つけるのは簡単です。
マスキングの実装
これは、巨大な組織が単一のマスキングツールを使用する場合には機能しません。 しかし、それは適切な計画と多様なツールを使って行う必要があります。 したがって、データマスキングから最適なソリューションを得るには、将来の企業のニーズを調査する必要があります。
データマスキングのテスト結果
これが最後のステップです。 望ましい結果を生み出すための隠蔽の取り決めを確実にするために、QAとテストが必要です。
その他の有用なリソース:
考慮すべき3種類のデータ匿名化手法とツール
具体的なサイバーセキュリティリスク管理戦略の5つのメリット
保護とデータプライバシーを確保するために尋ねる4つの質問