
深層強化学習の方法論とは何ですか?
公開: 2024-02-28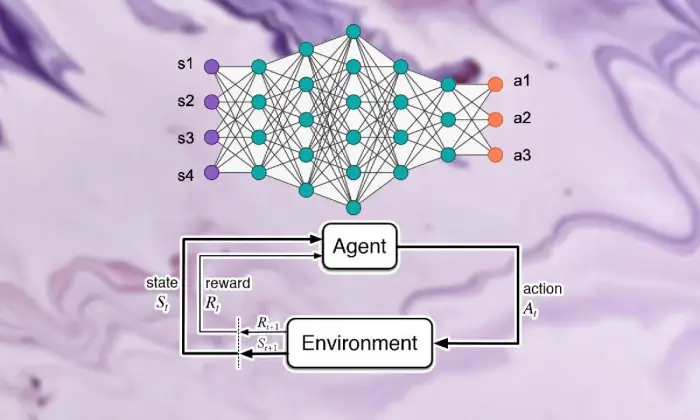
深層強化学習は依然として最先端の人工推論の最前線にあり、深層学習の領域を混合し、機械が独自に学習して簡単に決定できるようにする方法の発見をサポートします。
深層強化学習 (DRL) には、気候と関連付けるための計算の準備と、報酬または罰として批判から得ることが含まれます。 この強力な手順は、深層脳ネットワークの象徴的な力と学習支援専門家のダイナミックな能力を結合します。
DRL は、ゲームや機械技術から後方支援や医療サービスに至るまで、さまざまな分野にわたる複雑な任務を処理する際立ったスキルにより、多大な注目を集めています。 その柔軟性と実行可能性により、コンピューターベースの知能検査と応用分野の基盤となり、ベンチャー企業や教師全体に驚異的な効果が期待できます。
深層強化学習の複雑さをさらに深く掘り下げていくと、そのアプローチを明らかにし、マシンが周囲の一般的な環境を認識し、連携する方法を変える真の能力を解きほぐす必要があります。

強化学習の基礎
深層強化学習を観察する旅に出発するには、サポート学習の本質をしっかりと理解する必要があります。 RL の中心となるのは、総合報酬を高めるために、専門家が状況の中で連続する選択をどのように決定するかを心配する AI の世界観です。
サポート学習の領域内では、成長するエクスペリエンスを形成する上で、いくつかの重要な部分とアイデアが重要な部分を占めます。 RL アプローチの核心を解くには、次の角度を掘り下げる必要があります。
基本概念と用語
深層強化学習を理解するには、まず、学習をサポートするために固有の重要なアイデアと文言を受け入れる必要があります。 これらには、RL 計算の構造ブロックを構成する、状態、アクティビティ、賞金、戦略などの考えが組み込まれています。
強化学習のコンポーネント
深層強化学習の場面では、サポート学習の基本的な部分を理解することが重要です。 サポート学習には、専門家が現在の状況とどのようにつながり、しばらくして理想的なシステムを学習するかを形作るいくつかの重要なコンポーネントが含まれています。
専門家、気候、活動、賞品を含むこれらの部分は、サポート学習フレームワークの構造ブロックを構造化します。 これらの重要なコンポーネントを理解することで、深層強化学習の計算機能と、それが気が遠くなるような動的な問題に対処するためにどのように適用されるかについての知識を得ることができます。
エージェント
強化学習におけるエージェントは、単に気候を決定し、気候と結び付けることに責任を持つ物質を暗示します。 過去の遭遇や批判を踏まえて、報酬や罰を通じて状況を探る方法を見つけ出す。
環境
環境は、専門家が協力する外側の枠組みを表します。 国家が進歩するにつれて専門家に批判が与えられ、報酬が与えられ、成長する経験が形成されます。
行動
アクションは、専門家があらゆる選択ポイントでアクセスできる決定を表します。 スペシャリストは、現在のステータスと理想的な結果を考慮してアクティビティを選択します。これは、長期にわたって総合的な賞を増やすことを意味します。
報酬
報酬はエージェントへの入力手段として機能し、エージェントの活動の魅力を示します。 肯定的な賞は望ましい行動を蓄積し、否定的な賞は不幸な活動を抑制します。
マルコフ意思決定プロセス (MDP)
マルコフ決定プロセス (MDP) は、強化学習における連続した動的問題を実証するための従来の構造を提供します。 それらは、状態、活動、変化の確率、賞品で構成され、確率論的な方法で気候の要素を例示します。
ディープラーニングを理解する
深層強化学習を見学する旅の出発には、深層学習の領域に飛び込むことが含まれます。これは、情報から複雑な例や描写を分離する計算を可能にする基本的な部分です。 深層学習は、人工推論における多くのクラス最高のアプローチの基礎として機能し、機械が複雑な接続を学習し、洗練された選択を行う能力を与えます。
ニューラル ネットワークの基礎
深層強化学習の本質を理解するには、まず脳の組織化の基礎を理解する必要があります。 脳ネットワークは人間の心の構造と能力を模倣しており、入力情報を循環させて変更するニューロンの相互接続層が関与しています。 これらの組織は、進歩的な描写を巧みに学習し、複雑なデータセット内の多面的な例や要素を捉えることができるようにしています。
深層学習アーキテクチャ
深層強化学習の領域では、深層学習構造の複雑さを理解することが重要です。 奥深い学習構造は多くの高度な計算の基礎として機能し、専門家が情報から複雑な例や描写を得ることができます。
これらの構造を調査することで、専門家がデータを処理および解読できるようにするコンポーネントを解きほぐし、独自の条件下で鋭いダイナミクスを扱うことができます。
畳み込みニューラル ネットワーク (CNN)
畳み込みニューラル ネットワーク (CNN) は、写真や録音などのネットワークのような情報を処理する専門知識を備えています。 これらは畳み込み層に影響を与えて空間要素を段階的に削除し、画像の順序、オブジェクト認識、分割などの最先端の割り当てを実行できるようにします。
リカレント ニューラル ネットワーク (RNN)
リカレント ニューラル ネットワーク (RNN) は、時系列や通常の言語など、一時的な条件を持つ連続した情報を処理することに成功します。 これらは、時間ステップを超えて記憶を維持することを可能にする断続的な関連付けを備えており、言語の表示、機械による解釈、談話の承認などの用事に適しています。
ディープ Q ネットワーク (DQN)
Deep Q-Networks (DQN) は、サポートを取得し、Q 学習計算を使用して深層脳ネットワークを統合するための特定のエンジニアリングに取り組みます。 これらの組織は、活動評価能力を大まかに調整し、高層の状態空間を持つ状況で理想的な選択を決定できるようにする方法を見つけ出します。
ニューラルネットワークのトレーニング
ニューラル ネットワークのトレーニングは深層強化学習の基本的な部分であり、スペシャリストが実際に知識を得て動的能力をさらに開発できるようにする上で重要です。 ニューラル ネットワークは、バックプロパゲーションやスロープ プラメットなどの計算を利用するように準備されており、組織の境界を変更して期待の失敗を制限します。
準備サイクル全体を通して、情報は組織内で処理され、モデルはより正確な予測を行う方法を繰り返し見つけ出します。 失敗に気づいたときに組織の境界を繰り返し更新することで、脳のネットワークは与えられた用事のプレゼンテーションに着実に取り組んでいきます。 この反復的な改善コースは深層強化学習の中心的な部分を占めており、専門家が長期的にシステムを調整して合理化できるようになります。
誤差逆伝播法
バックプロパゲーションは、脳の組織を準備する基礎として機能し、境界を繰り返し変更して期待の間違いを制限することで、情報から情報を得ることができるようにします。 この計算は、傾斜急落による生産性の向上と連動して、ネットワーク境界の不幸能力の傾きを計算します。

勾配降下法
勾配降下法は脳ネットワークの境界を強化する核心であり、教育経験を不幸能力の最小値に向けます。 最も急な急降下に向けて境界を繰り返し更新することにより、急降下角度の計算により、脳組織が理想的な配置に参加できるようになります。
関連記事: ディープラーニングと機械学習: 主な違い
強化学習と深層学習の統合
強化学習と深層学習を連携させることで、人工意識の領域における本質的な進歩に取り組み、2 つの理想的なモデルの特性を相乗的に利用して、複雑で動的な取り組みを優れた実行可能性で処理します。
ディープ ラーニングとサポート ラーニング戦略の一貫した組み合わせにより、その結合を推進するインスピレーション、慣例的なサポート ラーニングによってもたらされる困難が近づいていること、およびディープ ラーニング手法の融合によってもたらされる画期的な利点についての洞察が明らかになります。
深層強化学習の動機
深層強化学習の結合は、複雑な条件下での理想的な配置の学習に対処するための、より汎用性があり、適応性があり、効果的な方法を求めるという使命によって推進されています。 従来の強化学習の計算は、高層の状態空間やわずかな利益と頻繁に競合し、真の問題への適切性を妨げています。
深層学習は、強化学習のスペシャリストに粗雑な触覚情報ソースから漸進的な描写を取得する能力を強化することで答えを提供し、ナビゲーションの基礎となる注目すべき要素や例を抽出できるようにします。
従来の強化学習の課題
従来の強化学習は、テストの失敗、非直接的かつ高層の状態空間、次元性の脅威など、山積する困難に直面しています。 さらに、一部の認定可能なアプリケーションでは、報酬が乏しく延期されているため、強力な取り決めを学習するために慣例的な RL 計算が試みられます。 これらの障害には、従来の強化学習の本質的な限界を克服するために、深遠な学習手法を組み込むことが必要となります。
強化学習におけるディープラーニングの利点
強化学習におけるディープラーニングの統合はさまざまな利点をもたらし、この分野を改革し、さまざまな分野での前進を可能にします。
ディープ ニューラル ネットワークにより、強化学習のスペシャリストは、手動の要素設計の要件を回避して、アクティビティの配置に対する粗雑な具体的な貢献から複雑なマッピングを効果的に取得できるようになります。
さらに、深層学習手法は、さまざまな条件にわたって学習されたアプローチの推測を使用して機能し、強化学習アルゴリズムの適応性と強度を向上させます。
深層強化学習の方法論
深層強化学習の哲学を深く掘り下げると、複雑な状況で理想的な選択を決定するために専門家を準備することを目的としたシステムと手順の豊富なシーンが明らかになります。
これらの手順を理解することで、専門家は成長する経験の基本となるコンポーネントの経験を積み、より生産的で成功する強化学習アルゴリズムの計画に従事することができます。
A. モデルフリーの強化学習とモデルベースの強化学習
深層強化学習では、一般に、モデルなしのアプローチとモデルベースのアプローチのどちらを選択するかによって、教育体験が決まります。 モデル戦略がなければ、実際のところ、気候の明確なモデルの要件を回避して、理想的な戦略を直接得ることができます。
一方、モデルベースの手法には、気候要素のモデルを学習し、それを将来の活動の設計に利用することが含まれます。 モデルベースの手法が有効性と推測のより良い例を提供する一方で、モデル戦略が適応性と汎用性に成功することなく、それぞれのアプローチは利点と妥協点を享受しています。
探索と活用のトレードオフ
調査の二重取引のトレードオフは強化学習の中核にあり、専門家が新しいアクティビティを評価してより良い戦略を見つける (調査) ことと、既知の情報を利用して手っ取り早い報酬を増やす (悪用) の間でバランスを取る方法を指示します。
深層強化学習の計算では、複雑な状況における理想的な戦略を学習するために、調査と虐待の間にある種の調和を図る必要があります。 このトレードオフを調査し、学習プロセスを導くために、イプシロン強欲テスト、ソフトマックス、トンプソン テストなどのさまざまな調査手順が利用されます。
ポリシー勾配法
戦略スロープ手法は、配置境界を直接合理化して予想される報酬を拡大する強化学習計算のクラスに対処します。 これらの戦略は、戦略をニューラル ネットワークとして定義し、アプローチ境界に対して予想される補償の角度により、組織の負荷をリフレッシュするためにスロープ上昇を利用します。
ストラテジー アングル手法には、ノンストップ アクティビティ スペースや確率的戦略を処理する能力など、いくつかの利点があり、深層強化学習における複雑な取り組みに適しています。
値関数メソッド
評価能力テクニックは、状態または状態とアクティビティの一致の価値を測定し、特定の戦略の下で通常のリターンに経験を与えることを目的としています。 深層強化学習の計算では、ディープ Q ネットワーク (DQN) などの評価能力近似器を頻繁に利用して、理想的な価値能力を取得します。
ディープ ニューラル ネットワークを利用することで、評価能力テクニックは、複雑な価値のある能力を不正確に処理し、熟練したアプローチの改善とナビゲーションを行うことができます。
俳優と批評家の手法
俳優批評手法は、戦略スロープと価値能力テクニックの両方の利点を統合し、別々のエンターテイナーと評論家の組織を利用して、取り決めと価値能力を同時に理解します。
アクターネットワークはポリシーパラメータを学習し、クリティカルネットワークは価値関数を推定してアクションの品質に関するフィードバックを提供します。
このアーキテクチャにより、アクター クリティカル手法で安定性と効率性のバランスを実現できるため、深層強化学習の研究やアプリケーションで広く使用されています。
深層強化学習アルゴリズム
強化学習アルゴリズムの領域を掘り下げると、専門家が独自に学習して複雑な状況に適応できるようにすることを目的としたシステムの別の場面が明らかになります。 これらの計算は、強化学習エージェントに、気が遠くなるような選択空間を探索し、しばらくしてからの行動方法を改善する能力を植え付ける深遠な脳組織の力に取り組みます。
ディープ Q ネットワーク (DQN)
Deep Q-Networks (DQN) は、深層強化学習における独自の進歩に取り組み、ディープ ニューラル ネットワークと Q 学習計算の組み合わせを提供します。 DQN は、脳組織を利用して活動評価能力を近似することで、専門家が高層の状態空間から理想的な配置を獲得できるようにし、ゲームやロボット工学などの分野で飛躍する準備を整えます。
深い決定論的ポリシー勾配 (DDPG)
Deep Deterministic Policy Gradient (DDPG) 計算は、芸能人の評論家テクニックの基準を一定の活動領域に広げ、専門家がスロープクライムを通じて決定論的アプローチを学習できるようにします。 DDPG は、決定論的な戦略傾斜計算を使用して深層脳ネットワークを統合することにより、機械制御や独立運転などの事業における驚異的な制御配置の学習を行います。
近接ポリシーの最適化 (PPO)
Proximal Policy Optimization (PPO) の計算は、信託地区の命令を通じて戦略境界の合理化に対処する原則的な方法を提供し、安定的で生産的な取り決めの更新を保証します。 確率的角度上昇を利用して配置境界を反復的に進めることにより、PPO 計算はさまざまなサポート学習ベンチマークで最先端の実行を達成し、さまざまな条件にわたってボリュームと汎用性を示します。
トラスト リージョン ポリシーの最適化 (TRPO)
トラスト リージョン ポリシー最適化 (TRPO) の計算では、トラスト ディストリクト内での配置の更新を義務付けることで、安定性とテストの生産性に重点を置き、戦略の大きな逸脱によるギャンブルを緩和します。
信頼領域の制約を利用してポリシーの更新をガイドすることにより、TRPO アルゴリズムは強化された収束特性とハイパーパラメーターの変動に対する堅牢性を示し、現実世界の強化学習アプリケーションに最適になります。
非同期アドバンテージ アクター-クリティック (A3C)
Asynchronous Advantage Actor-Critic (A3C) 計算では、非同時準備サイクルを利用して学習を高速化し、強化学習の取り組みにおけるテストの有効性をさらに高めます。 A3C 計算は、気候に非同時的に接続するさまざまな同等のエンターテイナーを利用することで、より多様な調査と連携し、専門家が複雑で動的な条件における強力な配置を学習できるようにします。
結論
全体として、深層強化学習の戦略は、複雑な状況において機械が独自に学習して選択を追求できるようにするための多層的な方法を例示しています。 この調査を通じて、私たちは強化学習の本質、深層学習手順の調整、この分野を前進させるさまざまな計算の展示について詳しく調べてきました。
センターの基準と戦略を理解することで、高度な力学やゲームから医療やお金に至るまで、さまざまな分野にわたる認定可能な困難に対処する際の深層強化学習の重要性についての知識が得られます。 私たちが計画しているように、深層強化学習のさらなる進歩と改善への潜在的な扉は無限に開かれています。
継続的な調査と進歩により、計算がより洗練され、適応性が向上し、さまざまな設定でのより広範な適合性が期待できます。 最新の出来事を常に新鮮に感じてディスカッションに参加するには、以下のコメントであなたの考察や批判を共有してください。
この重要なデータを同僚やパートナーに忘れずに伝えて、他の人が深層強化学習の興味深い世界を調査できるようにしてください。 私たちは力を合わせて進歩を推進し、人工知能の能力を最大限に引き出すことができます。