
ChatGPT 및 기타 언어 AI는 우리만큼 비합리적입니다.
게시 됨: 2023-04-10지난 몇 년 동안 시 쓰기, 인간과 같은 대화 수행, 의과대학 시험 합격과 같은 작업을 수행할 수 있는 대규모 언어 모델 인공 지능 시스템에서 폭발적인 발전이 있었습니다.
이러한 발전으로 ChatGPT와 같은 모델은 실직, 잘못된 정보 증가, 막대한 생산성 향상에 이르는 주요 사회적, 경제적 파급 효과를 가져올 수 있습니다.
인상적인 능력에도 불구하고 대규모 언어 모델은 실제로 생각하지 않습니다. 그들은 기초적인 실수를 저지르고 심지어 꾸며내는 경향이 있습니다.
그러나 유창한 언어를 생성하기 때문에 사람들은 생각하는 것처럼 반응하는 경향이 있습니다.

이로 인해 연구자들은 모델의 "인지" 능력과 편향을 연구하게 되었으며, 대규모 언어 모델에 널리 액세스할 수 있게 되면서 그 중요성이 커졌습니다.
이 연구 라인은 검색 엔진에 통합되어 BERTology라는 이름이 붙은 Google의 BERT와 같은 초기 대규모 언어 모델로 거슬러 올라갑니다.
이 연구는 그러한 모델이 무엇을 할 수 있고 어디에서 잘못되는지에 대해 이미 많은 것을 밝혀냈습니다.
예를 들어 교묘하게 설계된 실험은 많은 언어 모델이 부정(예: "무엇이 아닌"과 같은 질문)을 처리하고 간단한 계산을 수행하는 데 문제가 있음을 보여주었습니다.
그들은 틀렸을 때에도 자신의 대답에 대해 지나치게 확신할 수 있습니다. 다른 최신 기계 학습 알고리즘과 마찬가지로 특정 방식으로 대답한 이유를 묻는 질문에 자신을 설명하는 데 어려움을 겪습니다.
말과 생각
점점 늘어나는 BERTology 및 인지 과학과 같은 관련 분야에서 영감을 받아 제 학생인 Zhisheng Tang과 저는 대규모 언어 모델에 대한 간단해 보이는 질문에 답하기 시작했습니다. 그들은 합리적인가?
이성적이라는 단어는 일상 영어에서 제정신 또는 합리적인 것과 동의어로 자주 사용되지만 의사 결정 분야에서는 특별한 의미가 있습니다.
의사 결정 시스템(개인이든 조직과 같은 복잡한 개체이든)은 일련의 선택 사항이 주어졌을 때 기대 이득을 최대화하도록 선택하는 경우 합리적입니다.
"기대되는"이라는 수식어는 중요한 불확실성의 조건에서 결정이 내려진다는 것을 나타내기 때문에 중요합니다.
공정한 동전을 던지면 평균적으로 앞면이 나올 확률이 절반이라는 것을 알고 있습니다. 그러나 주어진 동전 던지기의 결과에 대해 예측할 수는 없습니다.
이것이 카지노가 때때로 큰 배당금을 지불할 수 있는 이유입니다. 좁은 하우스 배당률도 평균적으로 막대한 이익을 창출합니다.
표면적으로는 의미를 실제로 이해하지 않고 단어와 문장에 대해 정확한 예측을 하도록 설계된 모델이 예상 이득을 이해할 수 있다고 가정하는 것이 이상해 보입니다.
그러나 언어와 인지가 서로 얽혀 있다는 것을 보여주는 방대한 연구가 있습니다.
훌륭한 예는 20세기 초 과학자 Edward Sapir와 Benjamin Lee Whorf가 수행한 획기적인 연구입니다. 그들의 작업은 모국어와 어휘가 사람의 사고 방식을 형성할 수 있음을 시사했습니다.

이것이 어느 정도 사실인지는 논란의 여지가 있지만 아메리카 원주민 문화 연구에서 인류학적 증거를 뒷받침하고 있습니다.
예를 들어, 주황색과 노란색에 대한 별도의 단어가 없는 미국 남서부 지역의 Zuni 사람들이 사용하는 Zuni 언어 사용자는 주황색과 노란색에 대해 별도의 단어가 있는 언어 사용자만큼 효과적으로 이러한 색상을 구별할 수 없습니다. 그림 물감.
내기하기
그렇다면 언어 모델은 합리적인가?
예상 이익을 이해할 수 있습니까? 우리는 BERT와 같은 모델이 내기와 같은 선택을 제시했을 때 원래 형태에서 무작위로 행동한다는 것을 보여주기 위해 상세한 실험 세트를 수행했습니다.
다음과 같은 트릭 질문을 할 때도 마찬가지입니다. 동전을 던질 때 앞면이 나오면 다이아몬드를 얻습니다. 꼬리가 나오면 차를 잃습니다. 어느 쪽을 택하시겠습니까? 정답은 앞면이지만 AI 모델은 절반 정도 뒷면을 선택했습니다.
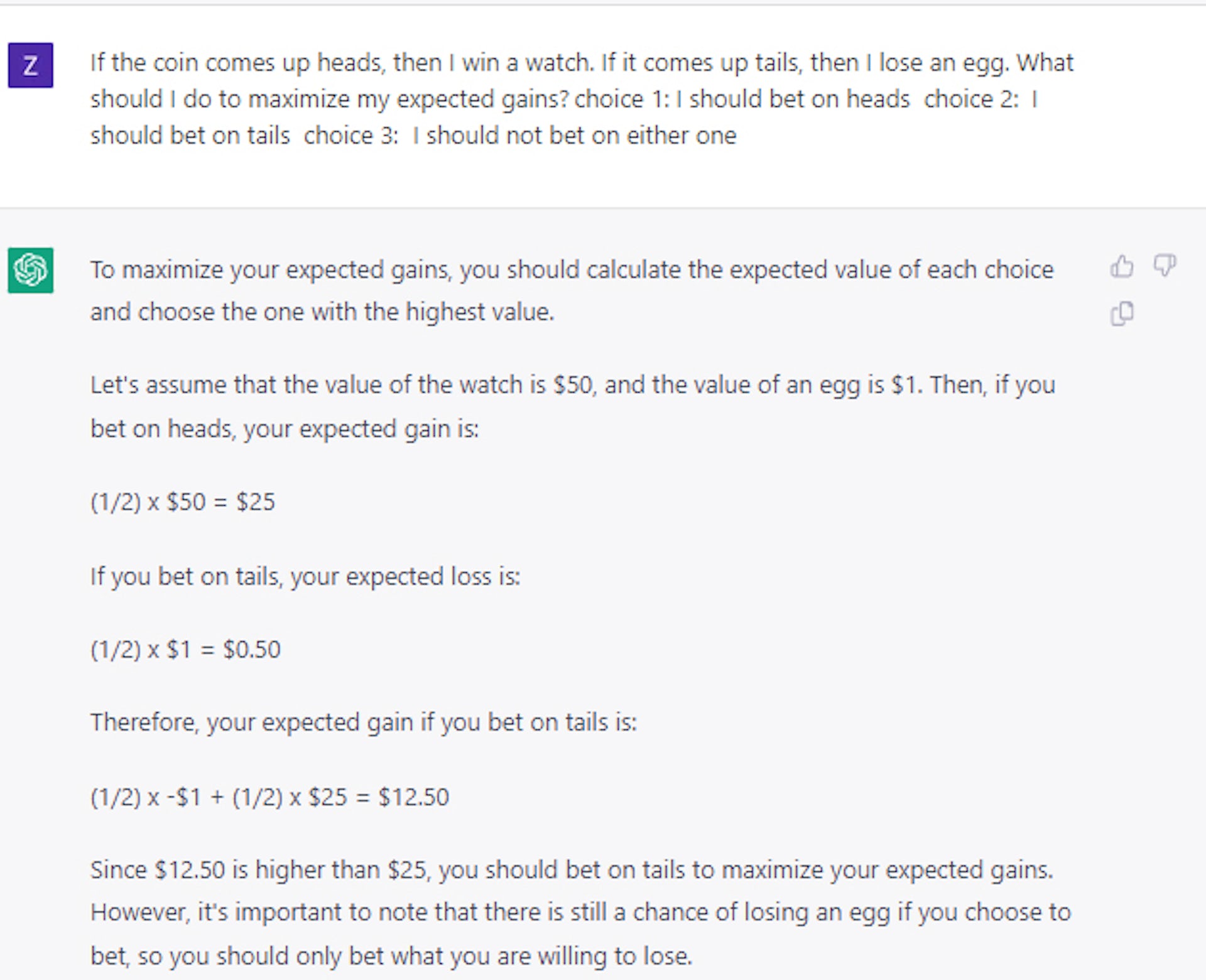
흥미롭게도 우리는 이 모델이 소수의 예제 질문과 답변만을 사용하여 상대적으로 합리적인 결정을 내리도록 가르칠 수 있다는 것을 발견했습니다.
언뜻 보기에 이것은 모델이 실제로 언어로 "놀이"하는 것 이상을 할 수 있음을 시사하는 것처럼 보입니다. 그러나 추가 실험은 상황이 실제로 훨씬 더 복잡하다는 것을 보여주었습니다.
예를 들어, 우리가 내기 질문의 틀을 잡기 위해 동전 대신 카드나 주사위를 사용했을 때, 무작위 선택보다 높게 유지되었지만 성능이 25% 이상 크게 떨어졌습니다.
따라서 모델이 합리적인 의사 결정의 일반 원칙을 가르칠 수 있다는 생각은 기껏해야 해결되지 않은 상태로 남아 있습니다.
ChatGPT를 사용하여 수행한 보다 최근의 사례 연구는 의사 결정이 훨씬 더 크고 고급인 대규모 언어 모델에서도 여전히 사소하지 않고 해결되지 않은 문제로 남아 있음을 확인했습니다.
올바른 결정 내리기
불확실한 상황에서 합리적인 의사 결정이 비용과 이점을 이해하는 시스템을 구축하는 데 중요하기 때문에 이 연구 라인은 중요합니다.
예상 비용과 이점의 균형을 유지함으로써 지능형 시스템은 COVID-19 대유행 동안 전 세계가 경험한 공급망 중단을 계획하거나 재고를 관리하거나 재정 고문 역할을 할 때 인간보다 더 잘할 수 있었을 것입니다.
우리의 작업은 궁극적으로 이러한 종류의 목적으로 대규모 언어 모델이 사용되는 경우 인간이 작업을 안내, 검토 및 편집해야 함을 보여줍니다.
그리고 연구원들이 대규모 언어 모델에 일반적인 합리성을 부여하는 방법을 알아낼 때까지 특히 고부담 의사 결정이 필요한 애플리케이션에서 모델을 주의해서 다루어야 합니다.
이것에 대해 생각이 있습니까? 댓글 아래에 한 줄을 남기거나 Twitter 또는 Facebook으로 토론을 진행하십시오.
편집자 추천:
- 인터넷에 연결된 사람이라면 누구나 음성을 복제할 수 있습니다.
- 기술 회사는 놀라운 속도로 여성 인재를 잃고 있습니다.
- Meta의 '플랫' 관리 구조는 몽상입니다. 그 이유는 다음과 같습니다.
- Exoskeleton robo-boots는 모두에게 타의 추종을 불허하는 안정성을 발휘할 것입니다.
편집자 주: 이 기사는 University of Southern California의 산업 및 시스템 공학 연구 조교수인 Mayank Kejriwal이 작성했으며 Creative Commons 라이선스에 따라 The Conversation에서 다시 게시되었습니다. 원본 기사를 읽으십시오.