
데이터 마스킹에 대한 완전한 가이드
게시 됨: 2020-03-04데이터 마스킹이란 무엇입니까?
데이터 마스킹은 원본 데이터를 변경된 데이터로 가장하거나 숨기는 과정입니다. 이때 형식은 그대로 유지되고 값만 변경됩니다. 이는 구조적으로 동일하지만 사용자 교육 또는 소프트웨어 테스트에 잘못된 버전의 데이터가 사용됩니다. 또한, 주요 원인은 필요하지 않은 경우 실제 데이터를 안전하게 보관하는 것입니다.
조직은 생산 데이터를 안전하게 보호하기 위해 엄격한 규칙과 규정을 가지고 있지만 데이터를 아웃소싱하는 경우 문제가 발생할 수 있습니다. 그렇기 때문에 대부분의 회사는 자신의 데이터를 공개적으로 보여주는 것을 꺼립니다.
- 정의
- 누가 데이터 마스킹을 사용합니까?
- 유형
- 수행 도구
- 알아야 할 기술
- 데이터 마스킹의 예
누가 데이터 마스킹을 사용합니까?
일반 데이터 보호 요구 사항(GDPR)을 준수하기 위해 기업은 생산 데이터의 보안을 보장하기 위해 데이터 마스킹을 적용하는 데 관심을 보였습니다. GDPR의 규칙 및 규정에 따라 EU 시민으로부터 데이터를 받는 모든 비즈니스는 문제의 민감성을 매우 잘 인식하고 불편을 피하기 위해 몇 가지 조치를 취해야 합니다.
따라서 주류 기업이 민감한 데이터를 안전하게 유지하는 것은 불가피합니다. 한편 사용할 수 있는 데이터의 종류는 다양하지만 비즈니스 분야에서 가장 많이 사용되는 데이터는 다음과 같습니다.
- 보호되는 건강 정보(PHI)
- 지적 재산(ITAR)
- 지불 카드 정보 PCI-DSS
위의 모든 예는 반드시 따라야 하는 의무 사항에 속합니다.
데이터 마스킹 유형
데이터 마스킹은 비프로덕션 사용자가 데이터에 액세스할 수 없도록 하기 위해 적용되는 특수 기술입니다. 조직들 사이에서 대중화되고 있으며 그 이면에는 사이버 보안 위협이 증가하고 있습니다. 따라서 이러한 데이터 위협에 대처하기 위해 마스킹 기술이 적용됩니다. 동일한 원인을 제공하는 다른 유형이 있지만 진행 방식은 여전히 다릅니다. 이제 두 가지 주요 유형이 있습니다. 하나는 정적이고 두 번째는 동적입니다.
정적 데이터 마스킹
정적 데이터 마스킹의 경우 데이터베이스의 복제본을 준비하며, 위조 또는 마스킹되는 필드를 제외하고는 실제 데이터베이스와 동일합니다. 이 더미 콘텐츠는 실제 테스트 시 데이터베이스의 작동에 영향을 미치지 않습니다.
동적 데이터 마스킹
동적 데이터 마스킹에서 중요한 정보는 실시간으로만 변경됩니다. 따라서 원본 데이터는 사용자만 볼 수 있고 권한이 없는 사용자는 더미 데이터만 볼 수 있습니다.
위는 데이터 마스킹의 주요 유형이지만 다음 유형도 사용됩니다.
통계 데이터 난독화
회사의 생산 데이터에는 통계라고 하는 다양한 수치가 있습니다. 이러한 통계를 가장하는 것을 통계 데이터 난독화라고 합니다. 비프로덕션 사용자는 이러한 유형의 데이터 마스킹에서 실제 통계를 추정할 수 없습니다.
즉석 데이터 마스킹
즉석 데이터 마스킹은 환경 간 데이터 전송이 수행되는 곳에 적용됩니다. 이 유형은 고도로 통합된 응용 프로그램에 대한 지속적인 배포를 수행하는 환경에 명시적으로 적합합니다.
데이터 마스킹 도구
기술은 나날이 발전하고 있고 다양한 문제에 대한 솔루션이 수정되고 있다는 사실을 우리 모두 알고 있습니다. 따라서 사용 가능한 도구는 훨씬 더 나은 효율성과 작업 품질로 새로운 로트를 추가했습니다. 따라서 여기에 수행하는 데 사용되는 최신 데이터 마스킹 솔루션 또는 도구가 있습니다.
- DATPROF 데이터 마스킹 도구
- IRI Field Shield(구조화된 데이터 마스킹)
- Oracle 데이터 마스킹 및 서브세팅.
- IBM INFO SPHERE Optim 데이터 개인정보 보호
- 델픽스
- Microsoft SQL Server 데이터 마스킹
- 정보 영구 데이터 마스킹
도구에 대한 자세한 내용은 다음 표에 나와 있습니다.
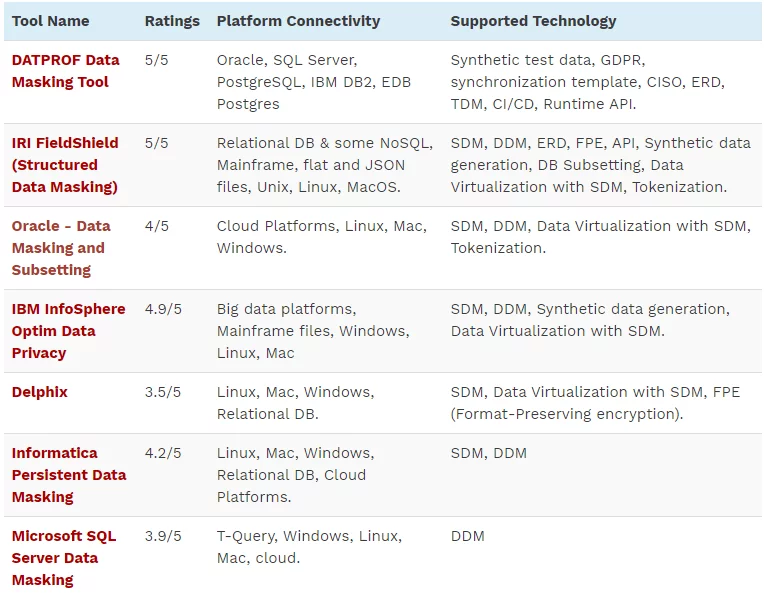
출처: https://www.softwaretestinghelp.com/data-masking-tools/

따라서 이들은 데이터 마스킹 솔루션 또는 데이터 마스킹 전략이라고도 하는 잘 알려진 도구입니다.
데이터 마스킹 기법
기회를 이용하기 위해 적용되는 수많은 기술이 있습니다. 시간이 지남에 따라 과제는 커지고 솔루션도 다양해지고 있습니다.
이전에는 적용되는 기술이 거의 없었지만 지금은 구현할 수 있는 기술이 많이 있습니다. 더욱이, 사용자의 목적은 주어진 모든 기술을 사용하여 잘 수행되지만 다른 기술의 경우 기능이 다를 수 있습니다. 따라서 가장 유명한 데이터 마스킹 기술 중 일부는 다음과 같습니다.
셔플
이것은 가장 자주 사용되는 기술 중 하나입니다. 이 기술에서 데이터는 열 내에서 섞입니다. 그러나 이것은 셔플링 코드를 해독하여 셔플링을 되돌릴 수 있기 때문에 높은 프로필 데이터에는 사용되지 않습니다.
암호화
이것은 가장 복잡한 기술입니다. 일반적으로 암호화에서 사용자는 원본 데이터를 보기 위한 키를 생성해야 합니다. 그러나 원본 데이터를 볼 수 있는 권한이 없는 사람에게 키를 양도하면 심각한 문제가 발생할 수 있습니다.
숫자 및 날짜 차이
숫자 변경 전략은 돈 관련 및 날짜 기반 필드에 적용하는 데 유용합니다.
마스킹 아웃
이 기술에서는 전체 데이터가 마스킹되지 않습니다. 원래 값을 파악할 수 없도록 마스킹된 특정 통계가 있습니다.
Nulling 또는 삭제
이 기술은 다른 데이터 요소의 가시성을 피하기 위해서만 사용됩니다. 이것은 데이터 마스킹을 적용하는 데 사용할 수 있는 가장 간단한 기술입니다. 그러나 가시적인 데이터를 찾기 위해서는 역공학적 방법을 적용할 수 있다. 따라서 민감한 데이터에는 그다지 적합하지 않습니다.
추가 복잡한 규칙
추가적인 복잡한 규칙은 기술이라고 할 수 없습니다. 그러나 이것은 승인되지 않은 사용자의 침입에 대해 더 무적을 만들기 위해 모든 종류의 마스킹에 적용할 수 있는 규칙입니다. 이러한 규칙에는 행 내부 동기화 규칙, 열 내부 동기화 규칙 등이 포함됩니다.
치환
이것은 가장 적합한 마스킹 기술입니다. 이 기술에서는 원본 데이터를 가장하기 위해 모든 확실한 통계 값을 추가합니다. 이러한 방식으로 인증되지 않은 사용자는 해당 값을 의심하지 않으며 데이터도 보존됩니다. 이 기술은 민감한 정보를 숨겨야 하는 대부분의 경우에 적용됩니다.
데이터 마스킹 예제
다양한 도구와 소프트웨어가 있으며 사용하는 도구나 소프트웨어에 따라 예제도 달라집니다. 또한 위에서 언급한 모든 도구를 사용하여 데이터 마스킹을 정적으로 또는 동적으로 수행할 수 있습니다. 결과는 각각의 경우에 동일합니다.
이전에는 대부분의 회사가 이 시스템에서 벗어났지만 현재로서는 미국에만 114개의 큰 조직이 있어 비프로덕션 사용자로부터 정보를 안전하게 보호하기 위해 오라클 데이터 마스킹을 사용하고 있습니다. 더욱이, 보안이 손상될 수 없기 때문에 이제 이 기술을 채택하려는 회사의 수가 지속적으로 폭발할 것입니다.
마지막 생각들
전체 기사를 살펴보면 민감도와 중요성을 이해했습니다. 따라서 더 개선하기 위해 여기에서 최고의 데이터 마스킹 방법에 대해 마지막으로 말씀드리겠습니다.
데이터 찾기
이것은 민감한 것으로 보이며 마스킹되어야 하는 데이터를 찾아야 하는 첫 번째 단계입니다.
적합한 기술 찾기
데이터의 특성을 확인한 후에는 기사에서 위에 제공된 기술 중 하나를 선택할 수 있습니다. 상황을 고려하여 적절한 마스킹 기술을 쉽게 찾을 수 있습니다.
마스킹 구현
이것은 단일 마스킹 도구를 사용하는 거대한 조직에서 작동하지 않을 것입니다. 그러나 적절한 계획과 다양한 도구를 사용하여 수행해야 합니다. 따라서 데이터 마스킹에서 최상의 솔루션을 얻으려면 미래 기업의 요구 사항을 살펴봐야 합니다.
데이터 마스킹 테스트 결과
이것이 마지막 단계입니다. 원하는 결과를 얻을 수 있도록 은폐 장치를 보장하려면 QA 및 테스트가 필요합니다.
기타 유용한 리소스:
고려해야 할 3가지 유형의 데이터 익명화 기술 및 도구
구체적인 사이버 보안 위험 관리 전략의 5가지 이점
보호 및 데이터 프라이버시를 보장하기 위해 해야 할 4가지 질문