
Jaka jest metodologia uczenia się przez głębokie wzmacnianie?
Opublikowany: 2024-02-28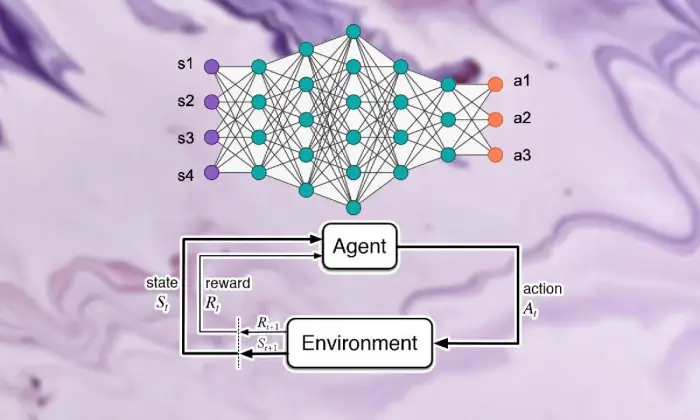
Uczenie się przez głębokie wzmacnianie pozostaje liderem najnowocześniejszego rozumowania stworzonego przez człowieka, łącząc dziedziny głębokiego uczenia się i wspierając odkrywanie, w jaki sposób umożliwić maszynom samodzielne uczenie się i proste podejmowanie decyzji.
Uczenie się przez głębokie wzmacnianie (DRL) obejmuje przygotowywanie obliczeń w celu połączenia z klimatem i czerpanie korzyści z krytyki w formie wynagrodzenia lub kary. Ta silna procedura łączy symboliczną siłę głębokich sieci mózgowych z dynamicznymi możliwościami specjalistów w zakresie uczenia się wspomagającego.
Firma DRL zyskała ogromne uznanie ze względu na swoje uderzające umiejętności w zakresie wykonywania złożonych zadań w różnych przestrzeniach, od gier i technologii mechanicznej po usługi pleców i opieki medycznej. Jego elastyczność i wykonalność sprawiają, że jest to podstawa w dziedzinie komputerowego badania i stosowania inteligencji, obiecując niezwykłe efekty dla przedsięwzięć i nauczycieli.
W miarę zagłębiania się w złożoność głębokiego uczenia się przez wzmacnianie, powinniśmy odkryć jego podejście i rozwikłać jego prawdziwą zdolność do zmiany sposobu, w jaki maszyny postrzegają swoje ogólne otoczenie i współpracują z nim.

Podstawy uczenia się przez wzmacnianie
Wyruszenie na wycieczkę w celu poznania głębokiego uczenia się przez wzmacnianie wymaga silnego opanowania podstawowych zasad uczenia się wspomaganego. W centrum RL leży pogląd na sztuczną inteligencję, zaniepokojony tym, w jaki sposób specjaliści ustalają, w jaki sposób podejmować kolejne wybory w klimacie, aby zwiększyć łączne nagrody.
W dziedzinie uczenia się wspierającego kilka istotnych części i pomysłów odgrywa zasadniczą rolę w kształtowaniu rosnącego doświadczenia. Powinniśmy zagłębić się w te kąty, aby rozwikłać sedno podejścia RL:
Podstawowe pojęcia i terminologia
Aby zrozumieć głębokie uczenie się przez wzmacnianie, należy najpierw zaakceptować podstawowe idee i sformułowania właściwe dla wspierania uczenia się. Obejmują one takie myśli, jak stan, aktywność, nagroda i strategia, które tworzą bloki strukturalne obliczeń RL.
Składniki uczenia się przez wzmacnianie
W przypadku głębokiego uczenia się przez wzmacnianie zrozumienie podstawowych elementów uczenia się wspomaganego jest niezbędne. Uczenie się wspierające obejmuje kilka kluczowych elementów, które kształtują sposób, w jaki specjaliści łączą się z obecną sytuacją i po pewnym czasie uczą się idealnych systemów.
Te części, w tym specjalista, klimat, działania i nagrody, tworzą bloki strukturalne ram uczenia się wspierającego. Doceniając te istotne elementy, możemy zdobyć wiedzę na temat możliwości obliczeń w ramach uczenia się przez głębokie wzmacnianie i w jaki sposób można je zastosować do rozwiązywania zadziwiających problemów dynamicznych.
Agent
Czynnik uczenia się przez wzmacnianie nawiązuje do substancji odpowiedzialnej za proste podejmowanie decyzji i łączenie się z klimatem. Podpowiada, jak badać klimat w świetle poprzednich spotkań i krytyki za pomocą wynagrodzeń lub kar.
Środowisko
Środowisko stanowi zewnętrzną strukturę, z którą specjalista współpracuje. Krytykuje specjalistę w miarę postępu państwa i nagradza, tworząc rosnące doświadczenie.
działania
Działania reprezentują decyzje dostępne dla specjalisty w każdym momencie wyboru. Specjalista wybiera działania ze względu na ich obecny status i idealny wynik, co oznacza, że w dłuższej perspektywie zwiększy łączne nagrody.
Nagrody
Nagrody pełnią dla agenta rolę instrumentu wejściowego, ukazując atrakcyjność jego działań. Nagrody pozytywne budują pożądane sposoby zachowania, podczas gdy nagrody negatywne powstrzymują niefortunne działania.
Procesy decyzyjne Markowa (MDP)
Procesy decyzyjne Markowa (MDP) nadają konwencjonalną strukturę demonstrowaniu kolejnych dynamicznych problemów w uczeniu się przez wzmacnianie. Obejmują stany, działania, prawdopodobieństwa zmian i nagrody, ilustrując elementy klimatu w sposób probabilistyczny.
Zrozumienie głębokiego uczenia się
Wyruszenie w podróż w kierunku głębokiego uczenia się przez wzmacnianie wiąże się z zanurzeniem się w dziedzinę głębokiego uczenia się, podstawową część, która umożliwia obliczenia w celu oddzielenia złożonych przykładów i przedstawień od informacji. Głębokie uczenie się stanowi podstawę wielu najlepszych w swojej klasie podejść do rozumowania stworzonego przez człowieka, dając maszynom zdolność uczenia się skomplikowanych połączeń i dokonywania wyrafinowanych wyborów.
Podstawy sieci neuronowych
Aby pojąć istotę uczenia się przez głębokie wzmacnianie, należy najpierw poznać podstawy organizacji mózgu. Sieci mózgowe podszywają się pod budowę i możliwości ludzkiego umysłu, obejmując połączone ze sobą warstwy neuronów, które cyklicznie zmieniają informacje wejściowe. Organizacje te zręcznie uczą się progresywnych przedstawień, co pozwala im uchwycić wielostronne przykłady i elementy w złożonych zbiorach danych.
Architektury głębokiego uczenia się
W dziedzinie głębokiego uczenia się przez wzmacnianie najważniejsze jest zrozumienie złożoności struktur głębokiego uczenia się. Głębokie struktury uczenia się stanowią podstawę wielu obliczeń wysokiego poziomu, angażując specjalistów w celu uzyskania złożonych przykładów i przedstawień na podstawie informacji.
Badając te struktury, możemy rozwikłać komponenty, które umożliwiają specjalistom przetwarzanie i odszyfrowywanie danych, pracując z niezwykłą dynamiką w wyjątkowych warunkach.
Konwolucyjne sieci neuronowe (CNN)
Konwolucyjne sieci neuronowe (CNN) mają pewne doświadczenie w przetwarzaniu informacji podobnych do sieci, takich jak zdjęcia i nagrania. Wpływają na warstwy splotowe, aby stopniowo usuwać elementy przestrzenne, umożliwiając im wykonywanie nowatorskich zadań, takich jak porządkowanie obrazów, rozpoznawanie obiektów i dzielenie.
Rekurencyjne sieci neuronowe (RNN)
Rekurencyjne sieci neuronowe (RNN) z powodzeniem radzą sobie z kolejnymi informacjami w warunkach przejściowych, takich jak szeregi czasowe i język regularny. Mają sporadyczne skojarzenia, które pozwalają im nadążać za pamięcią w różnych etapach czasowych, dzięki czemu nadają się do takich zadań, jak wyświetlanie języka, interpretacja maszynowa i potwierdzanie dyskursu.
Głębokie sieci Q (DQN)
Głębokie sieci Q-Networks (DQN) zajmują się specyficzną inżynierią służącą do wychwytywania wsparcia i konsolidowania głębokich sieci mózgowych za pomocą obliczeń Q-learning. Organizacje te wymyślają, jak zgrubnie oszacować zdolność do oceny aktywności, umożliwiając im dokonanie idealnych wyborów w warunkach z wielowarstwowymi przestrzeniami stanów.
Trening sieci neuronowych
Szkolenie sieci neuronowych jest podstawową częścią głębokiego uczenia się przez wzmacnianie, istotną dla umożliwienia specjalistom osiągania zysków i dalszego rozwijania ich dynamicznych zdolności. Sieci neuronowe są przygotowane do wykorzystania obliczeń, na przykład propagacji wstecznej i spadku nachylenia, które zmieniają granice organizacji, aby ograniczyć błędy w oczekiwaniach.
Przez cały cykl przygotowawczy organizacja zajmuje się informacjami, a model iteracyjnie ustala, w jaki sposób sporządzić bardziej precyzyjne prognozy. Dzięki iteracyjnemu odświeżaniu granic organizacji w przypadku zauważonych błędów sieci mózgowe stale pracują nad prezentacją danego zadania. Ten iteracyjny kurs doskonalenia odgrywa kluczową rolę w głębokim uczeniu się przez wzmacnianie, umożliwiając specjalistom dostosowywanie i usprawnianie systemów w dłuższej perspektywie.
Propagacja wsteczna
Propagacja wsteczna stanowi podstawę przygotowania organizacji mózgowych, umożliwiając im czerpanie korzyści z informacji poprzez iteracyjną zmianę granic w celu ograniczenia błędów w oczekiwaniach. Obliczenia te przedstawiają nachylenie nieszczęsnych możliwości granic sieci, współpracując ze zwiększeniem produktywności poprzez spadek nachylenia.
Zejście gradientowe
Zejście gradientowe leży u podstaw wzmacniania granic sieci mózgowej, kierując doświadczenie edukacyjne w stronę minimów możliwości nieszczęścia. Dzięki iteracyjnemu odświeżaniu granic w kierunku najbardziej stromego spadku, obliczenia zanurzenia kątowego umożliwiają organizacjom mózgowym łączenie się w idealne układy.
Przeczytaj także: Uczenie głębokie a uczenie maszynowe: kluczowe różnice
Integracja uczenia się przez wzmacnianie i uczenia głębokiego
Koordynacja uczenia się przez wzmacnianie z uczeniem głębokim stanowi istotny postęp w dziedzinie świadomości stworzonej przez człowieka, synergistycznie wykorzystując cechy dwóch idealnych modeli do radzenia sobie ze złożonymi, dynamicznymi przedsięwzięciami z wyjątkową wykonalnością.
Spójne połączenie strategii głębokiego uczenia się i uczenia się wspierającego, ujawniające wgląd w inspiracje stojące za ich połączeniem, zbliżające się trudności, jakie stwarza zwyczajowe uczenie się wspierające, oraz przełomowe korzyści, jakie daje połączenie metod głębokiego uczenia się.

Motywacja do uczenia się poprzez głębokie wzmacnianie
Połączenie głębokiego uczenia się przez wzmacnianie napędzane jest misją opracowania bardziej wszechstronnych, dających się dostosować i skutecznych sposobów radzenia sobie z idealnymi aranżacjami uczenia się w złożonych warunkach. Konwencjonalne obliczenia uczenia się przez wzmacnianie często walczą z wielowarstwowymi przestrzeniami stanów i skromnymi nagrodami, udaremniając ich przydatność do rzeczywistych problemów.
Głębokie uczenie oferuje odpowiedź, wzbogacając specjalistów zajmujących się uczeniem przez wzmacnianie możliwością uzyskiwania progresywnych obrazów z prymitywnych źródeł informacji dotykowych, umożliwiając im wydobycie niezwykłych elementów i przykładów kluczowych dla nawigacji.
Wyzwania tradycyjnego uczenia się ze wzmocnieniem
Tradycyjne uczenie się przez wzmacnianie napotyka mnóstwo trudności, w tym niepowodzenie testów, niebezpośrednie i wielowarstwowe przestrzenie stanów oraz plagę wymiarowości. Ponadto niektóre certyfikowane aplikacje oferują skromne i opóźnione nagrody, co sprawia, że zwyczajowe obliczenia RL wymagają nauczenia się potężnych rozwiązań. Przeszkody te wymagają włączenia głębokich metod uczenia się, aby pokonać wewnętrzne ograniczenia, które zbliżają się do tradycyjnego uczenia się przez wzmacnianie.
Korzyści z głębokiego uczenia się w uczeniu się ze wzmocnieniem
Konsolidacja uczenia głębokiego w uczeniu się przez wzmacnianie ma różne zalety, reformując dziedzinę i umożliwiając postęp w różnych obszarach.
Głębokie sieci neuronowe umożliwiają specjalistom zajmującym się uczeniem przez wzmacnianie skutecznym uzyskiwaniem złożonych mapowań na podstawie surowych, namacalnych wkładów w układy działań, z pominięciem wymogu ręcznego projektowania elementów.
Poza tym metody głębokiego uczenia się opierają się na spekulacji na temat wyuczonych podejść w różnych warunkach, poprawiając zdolność adaptacji i siłę algorytmów uczenia się przez wzmacnianie.
Metodologia uczenia się przez głębokie wzmacnianie
Zagłębianie się w filozofię głębokiego uczenia się przez wzmacnianie odkrywa bogatą scenę systemów i procedur mających na celu przygotowanie specjalistów do podejmowania idealnych wyborów w złożonych warunkach.
Rozumiejąc te procedury, profesjonaliści zdobywają doświadczenie w zakresie podstawowych komponentów rosnącego doświadczenia, angażując ich w planowanie bardziej produktywnych i skutecznych algorytmów uczenia się przez wzmacnianie.
A. Uczenie się ze wzmocnieniem bez modelu a uczenie się ze wzmocnieniem w oparciu o model
W przypadku uczenia się przez głębokie wzmacnianie decyzja między podejściem bez modelu a podejściem opartym na modelu generalnie kształtuje doświadczenie edukacyjne. Bez strategii modelowych w prosty sposób uzyskuje się strategię idealną w istocie, z pominięciem wymogu jednoznacznego modelu klimatu.
Z drugiej strony techniki oparte na modelach obejmują poznanie modelu elementów klimatu i wykorzystanie go do projektowania przyszłych działań. Każde podejście ma swoje zalety i kompromisy, bez strategii modelowych charakteryzujących się zdolnością adaptacji i wszechstronnością, podczas gdy techniki oparte na modelach oferują lepsze przykłady skuteczności i spekulacji.
Kompromis w zakresie eksploracji i eksploatacji
Badanie kompromisu w zakresie podwójnego działania leży u podstaw uczenia się przez wzmacnianie, wyznaczając sposób, w jaki specjaliści zachowują równowagę pomiędzy oceną nowych działań w celu znalezienia potencjalnie lepszych strategii (dochodzenie) a wykorzystaniem znanych informacji w celu zwiększenia szybkich nagród (nadużycie).
Obliczenia uczenia się metodą głębokiego wzmacniania powinny wypracować pewien rodzaj harmonii pomiędzy badaniem a molestowaniem, aby nauczyć się idealnych strategii w złożonych warunkach. Do zbadania tego kompromisu i kierowania procesem uczenia się wykorzystywane są różne procedury badawcze, takie jak testy epsilon-avaricious, softmax i Thompson.
Metody gradientu polityki
Techniki nachylenia strategii dotyczą klasy obliczeń uczenia się przez wzmacnianie, które w prosty sposób usprawniają granice układu, aby zwiększyć oczekiwane nagrody. Strategie te definiują strategię jako sieć neuronową i wykorzystują narastanie zboczy w celu odświeżenia obciążeń organizacji ze względu na kąty przewidywanych kompensacji granic podejścia.
Techniki kąta strategicznego oferują kilka korzyści, w tym możliwość radzenia sobie z nieprzerwanymi przestrzeniami aktywności i strategiami stochastycznymi, dzięki czemu są odpowiednie dla złożonych przedsięwzięć w zakresie głębokiego uczenia się przez wzmacnianie.
Metody funkcji wartości
Techniki zdolności szacunku mają na celu ocenę wartości stanów lub dopasowań stanu do aktywności, dostarczając doświadczeń na temat normalnego zwrotu w ramach danej strategii. W obliczeniach uczenia się metodą głębokiego wzmacniania często wykorzystuje się przybliżenia zdolności wartościowania, na przykład głębokie sieci Q (DQN), w celu uzyskania idealnej wartości.
Wykorzystując głębokie sieci neuronowe, techniki oceny zdolności mogą niedokładnie oceniać złożone możliwości i pracować z efektywnym podejściem, doskonaleniem i nawigacją.
Metody aktora-krytyka
Metody oparte na aktorach-krytykach konsolidują korzyści płynące zarówno z technik nachylenia strategii, jak i technik wartości, wykorzystując oddzielne organizacje artystów i ekspertów, aby jednocześnie zapoznać się z aranżacją i możliwościami wartości.
Sieć aktorów uczy się parametrów polityki, natomiast sieć krytyków szacuje funkcję wartości, aby zapewnić informację zwrotną na temat jakości działań.
Architektura ta umożliwia metodom krytycznym dla aktorów osiągnięcie równowagi między stabilnością a wydajnością, dzięki czemu są one szeroko stosowane w badaniach i zastosowaniach związanych z głębokim uczeniem się przez wzmacnianie.
Algorytmy uczenia się poprzez głębokie wzmocnienie
Zagłębianie się w dziedzinę algorytmów uczenia się przez wzmacnianie odkrywa inną scenę systemów ukierunkowanych na umożliwienie specjalistom niezależnego uczenia się i dostosowywania się do złożonych warunków. Obliczenia te uwzględniają siłę głębokich organizacji mózgu w zaszczepianiu agentom uczenia się przez wzmacnianie zdolności do eksplorowania zadziwiających przestrzeni wyborów i po pewnym czasie ulepszania swoich sposobów zachowania.
Głębokie sieci Q (DQN)
Deep Q-Networks (DQN) stanowią odpowiedź na oryginalny postęp w głębokim uczeniu się przez wzmacnianie, prezentując połączenie głębokich sieci neuronowych z obliczeniami Q-learning. Przybliżając zdolność oceny aktywności z wykorzystaniem organizacji mózgowych, DQN umożliwiają specjalistom uzyskanie idealnych aranżacji z wielowarstwowych przestrzeni stanów, czyniąc ich gotowymi na skok naprzód w obszarach takich jak gry i robotyka.
Głęboko deterministyczny gradient polityki (DDPG)
Obliczenia Deep Deterministic Policy Gradient (DDPG) poszerzają standardy technik ekspertów w dziedzinie rozrywki na przestrzenie stałej aktywności, umożliwiając specjalistom naukę podejść deterministycznych poprzez wspinanie się po zboczach. Konsolidując głębokie sieci mózgowe za pomocą deterministycznego obliczania nachylenia strategii, DDPG pracuje nad nauką zadziwiających rozwiązań kontrolnych w przedsięwzięciach takich jak sterowanie mechaniczne i niezależna jazda.
Bliższa optymalizacja polityki (PPO)
Obliczenia Proximal Policy Optimization (PPO) oferują oparty na zasadach sposób radzenia sobie z usprawnianiem granic strategii poprzez imperatywy dzielnic zaufania, gwarantując stałe i produktywne odświeżanie ustaleń. Dzięki iteracyjnemu przesuwaniu granic aranżacji z wykorzystaniem stochastycznego wzrostu kąta obliczenia PPO zapewniają najnowocześniejsze wykonanie w różnych wzorcach uczenia się wsparcia, wykazując się solidnością i wszechstronnością w różnych warunkach.
Optymalizacja polityki regionu zaufania (TRPO)
Obliczenia optymalizacji polityki regionu zaufania (TRPO) koncentrują się na stabilności i produktywności testów, wymuszając odświeżenie ustaleń w okręgu zaufania, łagodząc ryzyko ogromnych odstępstw od strategii.
Wykorzystując ograniczenia regionu zaufania do kierowania aktualizacjami zasad, algorytmy TRPO wykazują ulepszone właściwości zbieżności i odporność na zmiany hiperparametrów, dzięki czemu dobrze nadają się do rzeczywistych zastosowań uczenia się przez wzmacnianie.
Asynchroniczny aktor-krytyk przewagi (A3C)
Obliczenia Asynchronous Advantage Actor-Critic (A3C) wykorzystują nierównoczesne cykle przygotowawcze, aby przyspieszyć naukę i dalej rozwijać skuteczność testów w przedsięwzięciach związanych z uczeniem się przez wzmacnianie. Wykorzystując różnych, równych sobie artystów łączących się z klimatem nierównocześnie, obliczenia A3C współpracują z bardziej zróżnicowanymi badaniami i umożliwiają specjalistom naukę potężnych aranżacji w skomplikowanych i dynamicznych warunkach.
Wniosek
Podsumowując, strategia uczenia się przez głębokie wzmacnianie stanowi przykład wielowarstwowego sposobu radzenia sobie z wzmacnianiem maszyn do samodzielnego uczenia się i dokonywania wyborów w złożonych warunkach. Przez cały czas trwania tego badania zagłębiliśmy się w podstawy uczenia się przez wzmacnianie, koordynację procedur głębokiego uczenia się i różne elementy obliczeń, które przyczyniły się do postępu w tej dziedzinie.
Rozumiejąc standardy i strategie ośrodka, zdobywamy wiedzę na temat znaczenia głębokiego uczenia się przez wzmacnianie w radzeniu sobie z certyfikowanymi trudnościami w różnych obszarach, od zaawansowanej mechaniki i gier po opiekę medyczną i pieniądze. Zgodnie z planem potencjalne otwarte drzwi do dodatkowego rozwoju i doskonalenia uczenia się metodą głębokiego wzmacniania są nieograniczone.
Dzięki ciągłym badaniom i postępom możemy spodziewać się znacznie bardziej wyrafinowanych obliczeń, lepszych możliwości adaptacji i szerszej trafności w różnych ustawieniach. Aby być na bieżąco z najnowszymi wydarzeniami i dołączyć do dyskusji, śmiało podziel się swoimi przemyśleniami i krytyką w uwagach poniżej.
Pamiętaj, aby przekazać te istotne dane swoim towarzyszom i partnerom, umożliwiając innym zbadanie interesującego świata głębokiego uczenia się przez wzmacnianie. Razem możemy napędzać postęp i otwierać maksymalne możliwości sztucznej inteligencji.