
Qual é a metodologia de aprendizagem por reforço profundo?
Publicados: 2024-02-28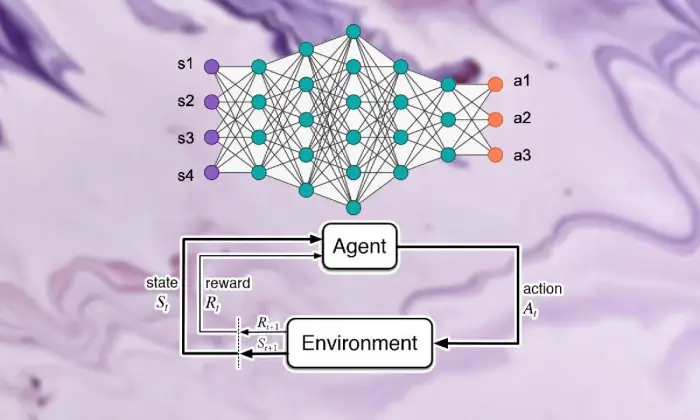
A aprendizagem por reforço profundo permanece na vanguarda do raciocínio artificial de última geração, misturando os domínios da aprendizagem profunda e apoiando a descoberta de como capacitar as máquinas para aprender de forma independente e simplesmente decidir.
A aprendizagem por reforço profundo (DRL) inclui a preparação de cálculos para se conectar com um clima e obter ganhos com críticas como remunerações ou punições. Este forte procedimento une a força emblemática das redes cerebrais profundas com as capacidades dinâmicas dos especialistas de apoio à aprendizagem.
A DRL conquistou enorme consideração devido à sua notável habilidade em lidar com tarefas complexas em diferentes espaços, desde jogos e tecnologia mecânica até serviços médicos e de apoio. A sua flexibilidade e viabilidade fazem dele uma base no domínio do exame e aplicação de inteligência baseada em computador, prometendo efeitos extraordinários em empreendimentos e professores.
À medida que nos aprofundamos nas complexidades da aprendizagem por reforço profundo, devemos descobrir a sua abordagem e desvendar a sua verdadeira capacidade de mudar a forma como as máquinas veem e colaboram com o seu ambiente geral.

Fundamentos da aprendizagem por reforço
Iniciar a excursão para ver a aprendizagem por reforço profundo requer um forte domínio dos fundamentos da aprendizagem de apoio. Em sua essência, RL é uma visão de mundo da IA preocupada em como os especialistas descobrem como tomar decisões sucessivas em um clima para aumentar as recompensas combinadas.
Dentro do domínio da aprendizagem de apoio, algumas partes e ideias vitais assumem partes essenciais na formação da experiência crescente. Deveríamos nos aprofundar nesses ângulos para desembaraçar a essência da abordagem RL:
Conceitos Básicos e Terminologia
Para compreender a aprendizagem por reforço profundo, deve-se inicialmente aceitar as ideias essenciais e as palavras intrínsecas para apoiar a aprendizagem. Eles incorporam pensamentos como estado, atividade, prêmio e estratégia, que estruturam os blocos estruturais dos cálculos de RL.
Componentes da aprendizagem por reforço
No cenário da aprendizagem por reforço profundo, compreender as partes básicas da aprendizagem de apoio é vital. A aprendizagem de suporte contém alguns componentes-chave que moldam a forma como os especialistas se conectam com suas circunstâncias atuais e aprendem sistemas ideais depois de algum tempo.
Essas partes, incluindo especialista, clima, atividades e prêmios, estruturam os blocos estruturais das estruturas de apoio à aprendizagem. Ao apreciar esses componentes essenciais, podemos adquirir conhecimento de como os cálculos de aprendizagem por reforço profundo podem ser aplicados e como eles são aplicados para cuidar de questões dinâmicas incompreensíveis.
Agente
O agente na aprendizagem por reforço alude à substância responsável por simplesmente decidir e conectar-se com o clima. Descobre como explorar o clima à luz de encontros e críticas anteriores através de remunerações ou punições.
Ambiente
O ambiente tipifica a estrutura externa com a qual o especialista colabora. Faz críticas ao especialista à medida que o Estado avança e recompensa, formando a experiência crescente.
Ações
As ações representam as decisões acessíveis ao especialista em cada ponto de escolha. O especialista escolhe as atividades pelo seu status atual e pelo resultado ideal, ou seja, potencializar os prêmios combinados no longo prazo.
Recompensas
As recompensas funcionam como instrumento de entrada para o agente, demonstrando a atratividade de suas atividades. Os prêmios positivos criam formas desejadas de comportamento, enquanto os prêmios negativos diminuem as atividades infelizes.
Processos de decisão de Markov (MDPs)
Os Processos de Decisão de Markov (MDPs) fornecem uma estrutura convencional para demonstrar questões dinâmicas sucessivas na aprendizagem por reforço. São compostos por estados, atividades, probabilidades de mudança e prêmios, exemplificando os elementos do clima de forma probabilística.
Compreendendo o aprendizado profundo
Partir na excursão para ver a aprendizagem por reforço profundo envolve mergulhar no domínio da aprendizagem profunda, uma parte básica que permite cálculos para separar exemplos e representações complexas das informações. O aprendizado profundo é a base de muitas das melhores abordagens de raciocínio criado pelo homem, dando às máquinas a capacidade de aprender conexões complicadas e fazer escolhas refinadas.
Noções básicas de redes neurais
Para compreender a substância da aprendizagem por reforço profundo, é necessário inicialmente compreender os rudimentos da organização cerebral. As redes cerebrais personificam a construção e a capacidade da mente humana, envolvendo camadas interconectadas de neurônios que circulam e alteram as informações de entrada. Estas organizações são hábeis na aprendizagem de representações progressivas, capacitando-as para captar exemplos e elementos multifacetados dentro de conjuntos de dados complexos.
Arquiteturas de aprendizagem profunda
No domínio da aprendizagem por reforço profundo, a compreensão das complexidades das estruturas de aprendizagem profunda é fundamental. Estruturas de aprendizagem profundas atuam como base de muitos cálculos de alto nível, envolvendo especialistas para obter exemplos e representações complexas a partir de informações.
Ao investigar essas estruturas, podemos desembaraçar os componentes que capacitam os especialistas a processar e decifrar dados, trabalhando com dinâmicas astutas em condições únicas.
Redes Neurais Convolucionais (CNNs)
As Redes Neurais Convolucionais (CNNs) têm alguma experiência no tratamento de informações semelhantes às de rede, como imagens e gravações. Eles influenciam as camadas convolucionais para remover elementos espaciais progressivamente, capacitando-os a realizar tarefas de ponta, como ordem de imagens, reconhecimento de objetos e divisão.
Redes Neurais Recorrentes (RNNs)
Redes Neurais Recorrentes (RNNs) conseguem cuidar de informações sucessivas com condições transitórias, como séries temporais e linguagem regular. Eles têm associações intermitentes que lhes permitem acompanhar a memória ao longo dos intervalos de tempo, tornando-os apropriados para tarefas como exibição de linguagem, interpretação automática e reconhecimento de discurso.
Redes Q profundas (DQNs)
Deep Q-Networks (DQNs) abordam uma engenharia específica para apoiar a captação e consolidação de redes cerebrais profundas com cálculos de Q-learning. Essas organizações descobrem como aprimorar a capacidade de estima da atividade, capacitando-as a tomar decisões ideais em condições com espaços de estado de alto nível.
Treinamento de Redes Neurais
O treinamento de redes neurais é uma parte básica do aprendizado por reforço profundo, importante para capacitar os especialistas para ganhar, de fato, e desenvolver ainda mais suas capacidades dinâmicas. As redes neurais estão preparadas para utilizar cálculos, por exemplo, retropropagação e queda de inclinação, que alteram os limites da organização para limitar erros de expectativas.
Durante todo o ciclo de preparação, as informações são cuidadas na organização e o modelo descobre iterativamente como fazer previsões mais precisas. Ao atualizar iterativamente os limites da organização diante dos erros percebidos, as redes cerebrais trabalham continuamente na apresentação da tarefa em questão. Este curso iterativo de melhoria assume um papel central na aprendizagem por reforço profundo, permitindo que os especialistas ajustem e simplifiquem seus sistemas a longo prazo.
Retropropagação
A retropropagação serve como base para a preparação de organizações cerebrais, capacitando-as a obter ganhos com informações, alterando iterativamente seus limites para limitar erros de expectativa. Este cálculo calcula as inclinações da capacidade de infortúnio para os limites da rede, trabalhando com o aumento produtivo através da queda de inclinação.
Gradiente descendente
A descida gradiente está no centro do aprimoramento dos limites da rede cerebral, direcionando a experiência educacional para os mínimos da capacidade de infortúnio. Ao atualizar iterativamente os limites em direção à queda mais acentuada, os cálculos de mergulho angular capacitam as organizações cerebrais a se unirem a arranjos ideais.
Leia também: Deep Learning vs Machine Learning: Principais diferenças
Integração de Aprendizado por Reforço e Aprendizado Profundo
A coordenação da aprendizagem por reforço com a aprendizagem profunda aborda uma progressão essencial no domínio da consciência criada pelo homem, utilizando sinergicamente as qualidades dos dois modelos ideais para lidar com empreendimentos dinâmicos complexos com viabilidade excepcional.
Combinação consistente de aprendizagem profunda e estratégias de aprendizagem de apoio, revelando insights sobre as inspirações que impulsionam sua adesão, as dificuldades apresentadas pela aproximação da aprendizagem de apoio habitual e as vantagens inovadoras proporcionadas pela fusão de métodos de aprendizagem profunda.

Motivação para aprendizagem por reforço profundo
A adesão à aprendizagem por reforço profundo é impulsionada pela missão de formas mais versáteis, adaptáveis e eficazes de lidar com arranjos ideais de aprendizagem em condições complexas. Os cálculos convencionais de aprendizagem por reforço frequentemente enfrentam espaços de estado de camadas altas e prêmios escassos, frustrando sua adequação a questões genuínas.
A aprendizagem profunda oferece uma resposta ao enriquecer os especialistas em aprendizagem por reforço com a capacidade de obter representações progressivas de fontes de informação tácteis brutas, capacitando-os a extrair elementos notáveis e exemplos fundamentais para a navegação.
Desafios da aprendizagem por reforço tradicional
A aprendizagem por reforço tradicional enfrenta uma série de dificuldades, incluindo falhas em testes, espaços de estado não diretos e de altas camadas e o flagelo da dimensionalidade. Além disso, alguns aplicativos certificáveis oferecem recompensas escassas e adiadas, fazendo com que seja necessário fazer cálculos regulares de RL para aprender arranjos poderosos. Esses impedimentos exigem a incorporação de métodos de aprendizagem profundos para superar as limitações intrínsecas da aprendizagem por reforço tradicional.
Benefícios do aprendizado profundo no aprendizado por reforço
A consolidação da aprendizagem profunda na aprendizagem por reforço apresenta diversas vantagens, reformando o campo e possibilitando avanços em diversas áreas.
As redes neurais profundas capacitam os especialistas em aprendizagem por reforço para obter efetivamente mapeamentos complexos a partir de contribuições tangíveis brutas para arranjos de atividades, ignorando a necessidade de projeto manual de elementos.
Além disso, os métodos de aprendizagem profunda funcionam com a especulação de abordagens aprendidas em diversas condições, melhorando a adaptabilidade e a força dos algoritmos de aprendizagem por reforço.
Metodologia de Aprendizagem por Reforço Profundo
Aprofundar-se na filosofia da aprendizagem por reforço profundo revela um cenário rico de sistemas e procedimentos voltados para a preparação de especialistas para fazerem escolhas ideais em condições complexas.
Ao compreender esses procedimentos, os profissionais ganham experiência nos componentes básicos da experiência crescente, engajando-os no planejamento de algoritmos de aprendizagem por reforço mais produtivos e bem-sucedidos.
A. Aprendizagem por reforço sem modelo versus aprendizagem por reforço baseada em modelo
Na aprendizagem por reforço profundo, a decisão entre abordagens sem modelo e abordagens baseadas em modelo geralmente molda a experiência educacional. Sem estratégias modelo, obtém-se directamente a estratégia ideal, ignorando a necessidade de um modelo inequívoco do clima.
Por outro lado, as técnicas baseadas em modelos incluem a aprendizagem de um modelo dos elementos do clima e a sua utilização para conceber actividades futuras. Cada abordagem desfruta dos seus benefícios e compromissos, sem que as estratégias de modelo tenham sucesso em termos de adaptabilidade e versatilidade, enquanto as técnicas baseadas em modelos oferecem melhores exemplos de eficácia e especulação.
Compensação entre exploração e exploração
A compensação dupla da investigação está no cerne da aprendizagem por reforço, orientando como os especialistas se equilibram entre a avaliação de novas atividades para encontrar estratégias possivelmente melhores (investigação) e o aproveitamento de informações conhecidas para aumentar recompensas rápidas (abuso).
Os cálculos de aprendizagem por reforço profundo devem estabelecer algum tipo de harmonia entre investigação e abuso para aprender estratégias ideais em condições complexas. Diferentes procedimentos de investigação, como testes épsilon-avareosos, softmax e Thompson, são utilizados para explorar essa compensação e orientar o processo de aprendizagem.
Métodos de gradiente de política
As técnicas de inclinação estratégica abordam uma classe de cálculos de aprendizagem por reforço que simplificam diretamente os limites do arranjo para expandir as recompensas previstas. Essas estratégias definem a estratégia como uma rede neural e utilizam o aumento da inclinação para atualizar as cargas da organização devido aos ângulos de compensações previstas para os limites de abordagem.
As técnicas de ângulo estratégico oferecem alguns benefícios, incluindo a capacidade de lidar com espaços de atividades ininterruptas e estratégias estocásticas, tornando-as apropriadas para empreendimentos complexos em aprendizagem por reforço profundo.
Métodos de função de valor
As técnicas de capacidade de estimativa pretendem avaliar o valor dos estados ou das correspondências entre atividades estaduais, fornecendo experiências sobre o retorno normal sob uma determinada estratégia. Os cálculos de aprendizagem por reforço profundo frequentemente utilizam aproximadores de capacidade de estimativa, por exemplo, redes Q profundas (DQNs), para obter a capacidade de valor ideal.
Ao utilizar redes neurais profundas, as técnicas de capacidade de estimativa podem inexatar capacidades de valor complexas e trabalhar com desenvolvimento de abordagem e navegação proficientes.
Métodos Ator-Crítico
Os métodos ator-crítico consolidam os benefícios da inclinação da estratégia e das técnicas de capacidade de valor, utilizando organizações separadas de artistas e especialistas para se familiarizarem com o arranjo e a capacidade de valor simultaneamente.
A rede ator-rede aprende os parâmetros políticos, enquanto a rede crítica estima a função de valor para fornecer feedback sobre a qualidade das ações.
Essa arquitetura permite que os métodos ator-crítico alcancem um equilíbrio entre estabilidade e eficiência, tornando-os amplamente utilizados em pesquisas e aplicações de aprendizagem por reforço profundo.
Algoritmos de aprendizagem por reforço profundo
A investigação no domínio dos algoritmos de aprendizagem por reforço revela um cenário diferente de sistemas apontados para capacitar especialistas para aprender de forma independente e se ajustar a condições complexas. Esses cálculos abordam a força das organizações cerebrais profundas para incutir nos agentes de aprendizagem por reforço a capacidade de explorar espaços de escolha incompreensíveis e melhorar suas formas de comportamento depois de algum tempo.
Redes Q profundas (DQN)
Deep Q-Networks (DQN) abordam um avanço original na aprendizagem por reforço profundo, apresentando uma mistura de redes neurais profundas com cálculos de Q-learning. Ao aproximar a capacidade de estimativa de atividade utilizando organizações cerebrais, os DQNs capacitam os especialistas a obter arranjos ideais em espaços de estado de altas camadas, preparando-os para saltos em áreas como jogos e robótica.
Gradiente de Política Determinística Profunda (DDPG)
Os cálculos do Deep Deterministic Policy Gradient (DDPG) ampliam os padrões das técnicas de especialistas em entretenimento para espaços de atividades constantes, capacitando os especialistas a aprender abordagens determinísticas por meio da subida de encostas. Ao consolidar redes cerebrais profundas com o cálculo determinístico da inclinação da estratégia, o DDPG trabalha com o aprendizado de arranjos de controle incompreensíveis em tarefas como controle mecânico e direção independente.
Otimização de Política Proximal (PPO)
Os cálculos de Otimização de Política Proximal (PPO) oferecem uma forma baseada em princípios para lidar com a racionalização dos limites da estratégia através de imperativos distritais de confiança, garantindo atualizações de arranjos estáveis e produtivas. Ao avançar iterativamente os limites do arranjo utilizando o aumento estocástico dos ângulos, os cálculos PPO alcançam uma execução de ponta em diferentes benchmarks de aprendizagem de suporte, exibindo robustez e versatilidade em diversas condições.
Otimização de Política de Região de Confiança (TRPO)
Os cálculos de Otimização de Política de Região de Confiança (TRPO) concentram-se na estabilidade e testam a produtividade, obrigando atualizações de arranjos dentro de um distrito de confiança, moderando a aposta de grandes desvios de estratégia.
Ao aproveitar as restrições da região de confiança para orientar as atualizações de políticas, os algoritmos TRPO exibem propriedades de convergência aprimoradas e robustez às variações de hiperparâmetros, tornando-os adequados para aplicações de aprendizagem por reforço do mundo real.
Ator-Crítico de Vantagem Assíncrona (A3C)
Os cálculos Assíncronos Advantage Actor-Critic (A3C) utilizam ciclos de preparação não simultâneos para acelerar o aprendizado e desenvolver ainda mais a eficácia dos testes em empreendimentos de aprendizado por reforço. Ao utilizar diferentes atores iguais conectando-se ao clima de forma não simultânea, os cálculos A3C funcionam com investigações mais variadas e capacitam os especialistas a aprender arranjos poderosos em condições complicadas e dinâmicas.
Conclusão
Em suma, a estratégia de aprendizagem por reforço profundo exemplifica uma forma multifacetada de lidar com a capacitação de máquinas para aprender e prosseguir escolhas de forma independente em condições complexas. Ao longo desta investigação, mergulhamos nos fundamentos da aprendizagem por reforço, na coordenação de procedimentos de aprendizagem profunda e nas diferentes exposições de cálculos que impulsionam avanços no campo.
Ao compreender os padrões e estratégias do centro, adquirimos conhecimento da importância da aprendizagem por reforço profundo no tratamento de dificuldades certificáveis em diferentes espaços, desde mecânica avançada e jogos até cuidados médicos e dinheiro. Conforme planejamos, as portas potenciais abertas para avanços e melhorias adicionais no aprendizado por reforço profundo são ilimitadas.
Com exames e progressões contínuas, podemos esperar cálculos consideravelmente mais refinados, melhor adaptabilidade e pertinência mais extensa em diferentes ambientes. Para se manter atualizado sobre os acontecimentos mais recentes e participar da discussão, vá em frente e compartilhe suas considerações e críticas nos comentários abaixo.
Lembre-se de transmitir esses dados significativos aos seus companheiros e parceiros, permitindo que outros investiguem o interessante universo da aprendizagem por reforço profundo. Juntos, podemos impulsionar o progresso e abrir a capacidade máxima da inteligência artificial.