
Care este metodologia de învățare prin consolidare profundă?
Publicat: 2024-02-28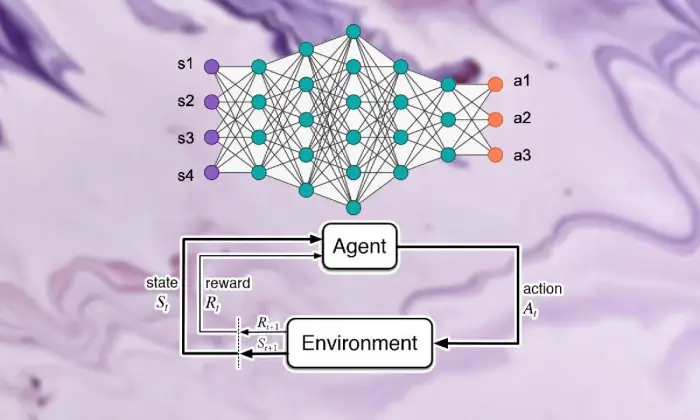
Învățarea prin întărire profundă rămâne chiar în fruntea raționamentului de ultimă generație creat de om, amestecând domeniile învățării profunde și susținând descoperirea modului de a da putere mașinilor să învețe independent și să decidă pur și simplu.
Învățarea prin consolidare profundă (DRL) include pregătirea calculelor pentru a se conecta cu un climat și câștigarea din critici ca remunerații sau pedepse. Această procedură puternică se alătură forței emblematice a rețelelor cerebrale profunde cu capacitățile dinamice ale specialiștilor de sprijin în învățare.
DRL a adunat o considerație enormă datorită abilității sale izbitoare de a gestiona sarcini complexe în diferite spații, de la jocuri și tehnologie mecanică până la servicii medicale și de spate. Flexibilitatea și viabilitatea sa îl fac o bază în domeniul examinării și aplicării informațiilor bazate pe computer, promițând efecte extraordinare în cadrul întreprinderilor și al profesorilor.
Pe măsură ce ne scufundăm mai mult în complexitatea învățării prin consolidare profundă, ar trebui să descoperim abordarea acesteia și să dezlegăm adevărata sa capacitate de a schimba modul în care mașinile văd și colaborează cu mediul lor general.

Fundamentele învățării prin întărire
Pornirea în excursia de a vedea învățarea prin întărire profundă necesită o abordare puternică a elementelor esențiale ale învățării de sprijin. În centrul său, RL este o viziune asupra lumii despre inteligența artificială îngrijorată de modul în care specialiștii își dau seama cum să rezolve alegerile succesive într-un climat care să stimuleze recompensele combinate.
În domeniul învățării de sprijin, câteva părți și idei vitale își asumă părți esențiale în formarea experienței în creștere. Ar trebui să cercetăm aceste unghiuri pentru a dezlega miezul abordării RL:
Concepte de bază și terminologie
Pentru a înțelege învățarea prin consolidare profundă, trebuie să acceptați inițial ideile esențiale și formularea intrinsecă pentru a sprijini învățarea. Acestea încorporează gânduri precum starea, activitatea, premiul și strategia, care structurează blocurile de structură ale calculelor RL.
Componentele învățării prin întărire
În scena învățării prin întărire profundă, înțelegerea părților de bază ale învățării de sprijin este vitală. Învățarea de sprijin conține câteva componente cheie care modelează modul în care specialiștii se conectează cu circumstanțele lor actuale și învață sistemele ideale după ceva timp.
Aceste părți, inclusiv specialistul, climatul, activitățile și premiile, structurează blocurile de structură ale cadrelor de învățare de sprijin. Apreciind aceste componente esențiale, putem dobândi cunoștințe despre capacitatea de calcul de învățare prin întărire profundă și modul în care acestea sunt aplicate pentru a rezolva problemele dinamice uluitoare.
Agent
Agentul din învățarea prin întărire face aluzie la substanța care răspunde pur și simplu de a decide și de a se conecta cu climatul. Își dă seama cum să exploreze climatul în lumina întâlnirilor și criticilor anterioare prin remunerații sau pedepse.
Mediu inconjurator
Mediul caracterizează cadrul exterior cu care colaborează specialistul. Oferă critici specialistului pe măsură ce statul avansează și recompensează, formând experiența în creștere.
Acțiuni
Acțiunile reprezintă deciziile accesibile specialistului în fiecare punct de alegere. Specialistul alege activități din cauza statutului lor actual și a rezultatului ideal, ceea ce înseamnă să sporească premiile combinate pe termen lung.
Recompense
Recompensele acționează ca instrument de intrare pentru agent, demonstrând atractivitatea activităților sale. Premiile pozitive creează moduri dorite de a se comporta, în timp ce premiile negative reduc activitățile nefericite.
Procesele de decizie Markov (MDPs)
Procesele de decizie Markov (MDP) oferă o structură convențională pentru a demonstra problemele dinamice succesive în învățarea prin consolidare. Ele cuprind stări, activități, probabilități de schimbare și premii, exemplificând elementele climatului într-un mod probabilistic.
Înțelegerea învățării profunde
A pleca în excursia de a vedea învățarea prin consolidare profundă implică scufundarea în domeniul învățării profunde, o parte de bază care permite calculelor pentru a separa exemplele complexe și reprezentările de informații. Învățarea profundă se completează ca fundament al multor abordări de cea mai bună calitate în raționamentul creat de om, dând posibilitatea mașinilor de a învăța conexiuni complicate și de a alege alegeri rafinate.
Bazele rețelelor neuronale
Pentru a înțelege substanța învățării prin întărire profundă, trebuie inițial să înțelegeți rudimentele organizării creierului. Rețelele cerebrale uzurpă identitatea construcției și capacității minții umane, implicând straturi interconectate de neuroni care circulă și modifică informațiile de intrare. Aceste organizații sunt pricepute să învețe portrete progresive, dându-le putere să surprindă exemple și elemente cu mai multe părți din seturi de date complexe.
Arhitecturi de învățare profundă
În domeniul învățării prin consolidare profundă, înțelegerea complexității structurilor de învățare profundă este principală. Structurile de învățare profunde acționează ca fundament pentru multe calcule de nivel înalt, angajând specialiști pentru a obține exemple complexe și portrete din informații.
Prin investigarea acestor structuri, putem dezlega componentele care împuternicesc specialiștii să proceseze și să descifreze datele, lucrând cu o dinamică inteligentă în condiții unice.
Rețele neuronale convoluționale (CNN)
Rețelele neuronale convoluționale (CNN) au o anumită experiență în manipularea informațiilor asemănătoare rețelei, cum ar fi imagini și înregistrări. Ele influențează straturile convoluționale pentru a elimina progresiv elementele spațiale, dându-le putere să realizeze sarcini de ultimă oră, cum ar fi ordinea imaginilor, recunoașterea obiectelor și diviziunea.
Rețele neuronale recurente (RNN)
Rețelele neuronale recurente (RNN) reușesc să aibă grijă de informații succesive cu condiții tranzitorii, cum ar fi seriile de timp și limbajul obișnuit. Au asocieri intermitente care le permit să țină pasul cu memoria de-a lungul pașilor de timp, făcându-le adecvate pentru sarcini precum afișarea limbajului, interpretarea automată și recunoașterea discursului.
Deep Q-Networks (DQN)
Deep Q-Networks (DQN) abordează o inginerie specifică pentru preluarea sprijinului și consolidarea rețelelor cerebrale profunde cu calcule Q-learning. Aceste organizații își dau seama cum să dezvolte capacitatea de estimare a activității, dându-le putere să se stabilească la alegeri ideale în condiții cu spații de stat cu straturi înalte.
Antrenamentul rețelelor neuronale
Antrenarea rețelelor neuronale este o parte de bază a învățării prin întărire profundă, importantă în împuternicirea specialiștilor pentru a câștiga, de fapt, și a-și dezvolta în continuare capacitățile dinamice. Rețelele neuronale sunt pregătite să utilizeze calcule, de exemplu, retropropagarea și scăderea pantei, care schimbă limitele organizației pentru a limita gafele așteptărilor.
Pe tot parcursul ciclului de pregătire, informațiile sunt îngrijite în organizație, iar modelul își dă seama iterativ cum să facă prognoze mai precise. Prin reîmprospătarea iterativă a limitelor organizației, având în vedere gafele observate, rețelele cerebrale lucrează constant la prezentarea misiunii date. Acest curs iterativ de îmbunătățire își asumă o parte centrală în învățarea prin consolidare profundă, permițând specialiștilor să își ajusteze și să eficientizeze sistemele pe termen lung.
Propagarea inversă
Propagarea în spate este fundamentul pregătirii organizațiilor creierului, dându-le putere să câștige din informații prin schimbarea iterativă a granițelor pentru a limita greșelile de așteptare. Acest calcul calculează pante ale capacității de nenorocire pentru limitele rețelei, lucrând cu îmbunătățirea productivă prin plonjarea înclinației.
Coborâre în gradient
Coborârea în gradient se află în centrul creșterii limitelor rețelei creierului, direcționând experiența educațională către minimele capacității de nenorocire. Prin reîmprospătarea iterativă a granițelor către cea mai abruptă prăbușire, calculele unghiului de adâncime permit organizațiilor creierului să se alăture la aranjamente ideale.
Citește și: Deep Learning vs Machine Learning: diferențe cheie
Integrarea învățării prin întărire și a învățării profunde
Coordonarea învățării prin întărire cu învățarea profundă abordează o progresie esențială în domeniul conștiinței create de om, utilizând în mod sinergic calitățile celor două modele ideale pentru a gestiona activități dinamice complexe cu o viabilitate excepțională.
Combinație consecventă de învățare profundă și strategii de învățare de sprijin, care dezvăluie o perspectivă asupra inspirațiilor care au determinat aderarea lor, dificultățile prezentate de învățarea de sprijin obișnuită se apropie și avantajele inovatoare oferite de fuziunea metodelor de învățare profundă.

Motivația pentru învățare prin consolidare profundă
Unirea învățării prin consolidare profundă este propulsată de misiunea pentru modalități mai versatile, adaptabile și eficiente de a face față aranjamentelor ideale de învățare în condiții complexe. Calculele convenționale de învățare prin întărire se luptă frecvent cu spații de stat cu straturi înalte și premii slabe, zădărnicindu-le adecvarea la problemele reale.
Învățarea profundă oferă un răspuns prin îmbogățirea specialiștilor în învățare prin consolidare cu capacitatea de a obține portrete progresive din surse de informații tactile brute, dându-i puterea de a extrage elemente și exemple remarcabile fundamentale pentru navigație.
Provocările învățării tradiționale prin întărire
Învățarea tradițională prin întărire se confruntă cu o grămadă de dificultăți, inclusiv eșecul testului, spații de stare nedirecte și stratificate înalte și flagelul dimensionalității. În plus, unele aplicații certificabile prezintă recompense slabe și amânate, ceea ce face ca calculele RL obișnuite să încerce să învețe aranjamente puternice. Aceste impedimente necesită încorporarea unor metode profunde de învățare pentru a cuceri limitările intrinseci ale învățării tradiționale prin întărire se apropie.
Beneficiile învățării profunde în învățarea prin consolidare
Consolidarea învățării profunde în învățarea prin întărire prezintă diverse avantaje, reformând domeniul și împuterind salturi înainte în diferite domenii.
Rețelele neuronale profunde permit specialiștilor de învățare prin consolidare să obțină în mod eficient mapări complexe din contribuțiile brute tangibile la aranjamentele de activitate, ocolind cerințele pentru proiectarea manuală a elementelor.
În plus, metodele de învățare profundă funcționează cu specularea abordărilor învățate în condiții asortate, îmbunătățind adaptabilitatea și puterea algoritmilor de învățare prin întărire.
Metodologia învățării prin întărire profundă
Explorarea filozofiei învățării prin întărire profundă descoperă o scenă bogată de sisteme și proceduri orientate spre pregătirea specialiștilor pentru a decide alegerile ideale în condiții complexe.
Înțelegând aceste proceduri, profesioniștii câștigă experiență în componentele de bază ale experienței în creștere, angajându-i să planifice algoritmi de învățare de întărire mai productivi și de succes.
A. Învățare fără modele vs. învățare bazată pe modele
În învățarea prin consolidare profundă, decizia între abordările sans model și modelul modelează în general experiența educațională. Fără modele de strategii se câștigă direct strategia ideală, de fapt, ocolind cerința unui model fără echivoc al climatului.
Pe de altă parte, tehnicile bazate pe modele includ învățarea unui model al elementelor climatice și utilizarea acestuia pentru a proiecta activități viitoare. Fiecare abordare se bucură de beneficiile și compromisurile sale, fără ca strategiile modelului să reușească în adaptabilitate și versatilitate, în timp ce tehnicile bazate pe model oferă exemple mai bune de eficacitate și speculație.
Comerț între explorare și exploatare
Compromisul de dublare a investigației se află în centrul învățării prin consolidare, direcționând modul în care specialiștii echilibrează între evaluarea noilor activități pentru a găsi strategii posibil mai bune (investigație) și profitarea de informații cunoscute pentru a crește recompensele rapide (abuz).
Calculele de învățare prin consolidare profundă ar trebui să creeze un fel de armonie între investigație și abuz pentru a învăța strategiile ideale în condiții complexe. Diferite proceduri de investigare, cum ar fi testarea epsilon-avaricious, softmax și Thompson, sunt utilizate pentru a explora acest compromis și a ghida procesul de învățare.
Metode de gradient de politică
Tehnicile de panta strategică se adresează unei clase de calcule de învățare prin întărire care simplifică direct limitele aranjamentului pentru a extinde recompensele anticipate. Aceste strategii definesc strategia ca o rețea neuronală și utilizează creșterea pantei pentru a reîmprospăta sarcinile organizației din cauza unghiurilor de compensare anticipate pentru granițele de apropiere.
Tehnicile de unghi strategic oferă câteva beneficii, inclusiv capacitatea de a face față spațiilor de activitate non-stop și strategii stocastice, făcându-le adecvate pentru activități complexe în învățarea prin consolidare profundă.
Metode de funcție de valoare
Tehnicile capacității de stima intenționează să evalueze valoarea stărilor sau a potrivirilor stat-activitate, oferind experiențe în rentabilitatea normală într-o anumită strategie. Calculele de învățare prin consolidare profundă utilizează frecvent aproximatorii capacității de stima, de exemplu, rețelele Q profunde (DQN), pentru a obține capacitatea de valoare ideală.
Prin utilizarea rețelelor neuronale profunde, tehnicile de capacitate de stima pot inexacte capacități de valoare complexă și pot lucra cu îmbunătățirea abordării și a navigației competente.
Metode actor-critice
Metodele critice pentru actor consolidează beneficiile atât ale tehnicilor de înclinare a strategiei, cât și ale tehnicilor de capacitate de valoare, utilizând organizații separate de divertisment și experti pentru a se familiariza cu aranjamentul și capacitatea de valoare simultan.
Actorul-rețeaua învață parametrii politicii, în timp ce rețeaua critică estimează funcția de valoare pentru a oferi feedback asupra calității acțiunilor.
Această arhitectură permite metodelor critice pentru actori să atingă un echilibru între stabilitate și eficiență, făcându-le utilizate pe scară largă în cercetarea și aplicațiile de învățare prin consolidare profundă.
Algoritmi de învățare cu întărire profundă
Explorarea în domeniul algoritmilor de învățare prin întărire descoperă o scenă diferită a sistemelor orientate spre împuternicirea specialiștilor să învețe în mod independent și să se adapteze la condiții complexe. Aceste calcule abordează forța organizațiilor profunde ale creierului de a insufla agenților de învățare de întărire cu capacitatea de a explora spații de alegere uluitoare și de a-și îmbunătăți modurile de a se comporta după ceva timp.
Deep Q-Networks (DQN)
Deep Q-Networks (DQN) abordează un progres original în învățarea prin consolidare profundă, prezentând un amestec de rețele neuronale profunde cu calcule Q-learning. Prin aproximarea capacității de estimare a activității folosind organizațiile creierului, DQN-urile împuternicesc specialiștii să obțină aranjamente ideale din spații de stat cu straturi înalte, făcându-i pregătiți pentru un salt înainte în domenii precum jocurile și robotica.
Gradient de politică deterministă profundă (DDPG)
Calculele DDPG (Deep Deterministic Policy Gradient) extind standardele tehnicilor expertilor de divertisment la spații de activitate constantă, dând putere specialiștilor să învețe abordări deterministe prin urcarea în pantă. Prin consolidarea rețelelor cerebrale profunde cu calculul pantei strategiei deterministe, DDPG lucrează cu învățarea aranjamentelor de control uluitoare în activități precum controlul mecanic și conducerea independentă.
Optimizarea proximală a politicii (PPO)
Calculele de optimizare a politicilor proximale (PPO) oferă o modalitate bazată pe principii de a gestiona eficientizarea limitelor strategiei prin imperativele districtului de încredere, garantând reîmprospătări stabile și productive ale aranjamentelor. Prin avansarea iterativă a limitelor aranjamentului utilizând creșterea unghiului stocastic, calculele PPO realizează o execuție de ultimă oră în diferite standarde de învățare de sprijin, dând dovadă de sinceritate și versatilitate în diferite condiții.
Optimizarea politicii regionale de încredere (TRPO)
Calculele de optimizare a politicii în regiune de încredere (TRPO) se concentrează pe stabilitatea și productivitatea testării prin reîmprospătarea aranjamentelor obligatorii în interiorul unui district de încredere, moderând pariul abaterilor uriașe ale strategiei.
Folosind constrângerile regiunii de încredere pentru a ghida actualizările politicilor, algoritmii TRPO prezintă proprietăți de convergență îmbunătățite și robustețe la variațiile hiperparametrilor, făcându-i foarte potriviti pentru aplicațiile de învățare prin consolidare din lumea reală.
Avantaj asincron actor-critic (A3C)
Calculele Asincrone Avantaj Actor-Critic (A3C) utilizează cicluri de pregătire neconcurente pentru a accelera învățarea și pentru a dezvolta în continuare eficacitatea testelor în întreprinderile de învățare prin consolidare. Folosind diferiți animatori egali care se conectează cu climatul în mod non-concomitent, calculele A3C funcționează cu investigații mai asortate și permit specialiștilor să învețe aranjamente puternice în condiții complicate și dinamice.
Concluzie
Una peste alta, strategia de învățare prin consolidare profundă exemplifica o modalitate pe mai multe straturi de a face față mașinilor care împuternicesc să învețe și să urmeze alegeri în mod independent în condiții complexe. Pe parcursul acestei investigații, ne-am cufundat în elementele esențiale ale învățării prin întărire, coordonarea procedurilor de învățare profundă și diferitele exponate de calcule care conduc progrese în domeniu.
Înțelegând standardele și strategiile centrului, dobândim cunoștințe despre importanța învățării prin consolidare profundă în gestionarea dificultăților certificabile în diferite spații, de la mecanică avansată și jocuri până la îngrijiri medicale și bani. Așa cum ne-am planificat, potențialele uși deschise pentru avansarea suplimentară și îmbunătățirea învățării prin consolidare profundă sunt nelimitate.
Cu o examinare și progresii continue, ne putem aștepta la calcule considerabil mai rafinate, o adaptabilitate îmbunătățită și o pertinență mai extinsă în diferite setări. Pentru a rămâne la curent cu cele mai recente evoluții ale evenimentelor și pentru a vă alătura discuției, continuați și împărtășiți considerentele și criticile dvs. în observațiile de mai jos.
Nu uitați să transmiteți aceste date semnificative însoțitorilor și partenerilor dvs., permițând altora să investigheze universul interesant al învățării prin consolidare profundă. Împreună, putem conduce progresul și deschide capacitatea maximă a inteligenței artificiale.