
Какова методология глубокого обучения с подкреплением?
Опубликовано: 2024-02-28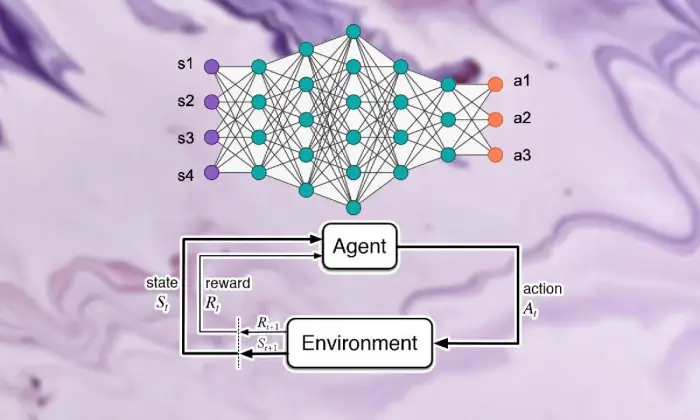
Глубокое обучение с подкреплением остается на переднем крае современных искусственных рассуждений, смешивая области глубокого обучения и помогая выяснить, как дать машинам возможность самостоятельно учиться и просто принимать решения.
Глубокое обучение с подкреплением (DRL) включает в себя подготовку расчетов, связанных с климатом и получением от критики вознаграждений или наказаний. Эта мощная процедура объединяет символическую силу глубоких мозговых сетей с динамическими способностями специалистов по вспомогательному обучению.
Компания DRL привлекла огромное внимание благодаря своим поразительным навыкам выполнения сложных задач в самых разных областях: от игр и механических технологий до спинальных и медицинских услуг. Его гибкость и жизнеспособность делают его основой в области компьютерного анализа и применения интеллекта, обещая исключительные результаты для предприятий и учителей.
По мере того, как мы углубляемся в сложности глубокого обучения с подкреплением, нам следует раскрыть его подход и раскрыть его истинную способность изменять то, как машины видят и взаимодействуют со своим общим окружением.

Основы обучения с подкреплением
Чтобы отправиться в путешествие по глубокому обучению с подкреплением, необходимо хорошо разбираться в основах обучения с подкреплением. По своей сути RL представляет собой мировоззрение ИИ, обеспокоенное тем, как специалисты решают, как сделать последовательный выбор в условиях, способствующих увеличению совокупного вознаграждения.
В области поддерживающего обучения несколько жизненно важных частей и идей играют важную роль в формировании растущего опыта. Нам следует углубиться в эти аспекты, чтобы распутать суть подхода RL:
Основные понятия и терминология
Чтобы понять глубокое обучение с подкреплением, нужно сначала принять основные идеи и формулировки, необходимые для поддержки обучения. Они включают в себя такие мысли, как состояние, деятельность, приз и стратегия, которые структурируют структурные блоки вычислений RL.
Компоненты обучения с подкреплением
В сфере глубокого обучения с подкреплением жизненно важно понимать основные части поддерживающего обучения. Вспомогательное обучение содержит несколько ключевых компонентов, которые определяют, как специалисты взаимодействуют со своими текущими обстоятельствами и через некоторое время изучают идеальные системы.
Эти части, включая специалиста, климат, мероприятия и премии, структурируют структурные блоки структур поддержки обучения. Оценив эти важные компоненты, мы можем получить знания о том, как можно использовать возможности глубокого обучения с подкреплением и как они применяются для решения ошеломляющих динамических проблем.
Агент
Агент в обучении с подкреплением намекает на вещество, отвечающее за простое принятие решений и связь с климатом. Он выясняет, как исследовать климат в свете предыдущих встреч и критики посредством вознаграждений или наказаний.
Среда
Среда типизирует внешнюю структуру, с которой сотрудничает специалист. Он критикует специалиста по мере продвижения со стороны государства и вознаграждает, формируя растущий опыт.
Действия
Действия представляют собой решения, доступные специалисту в каждой точке выбора. Специалист выбирает деятельность исходя из ее нынешнего статуса и идеального результата, что означает повышение совокупных вознаграждений в долгосрочной перспективе.
Награды
Вознаграждения выступают для агента входным инструментом, демонстрируя привлекательность его деятельности. Положительные призы способствуют формированию желаемого поведения, а отрицательные – подавляют неудачные действия.
Марковские процессы принятия решений (MDP)
Марковские процессы принятия решений (MDP) дают традиционную структуру для демонстрации последовательных динамических проблем в обучении с подкреплением. Они включают состояния, действия, вероятности изменений и призы, иллюстрируя элементы климата вероятностным способом.
Понимание глубокого обучения
Экскурсия по глубокому обучению с подкреплением предполагает погружение в область глубокого обучения, базовую часть, которая позволяет вычислениям отделять сложные примеры и изображения от информации. Глубокое обучение лежит в основе многих лучших в своем классе подходов к искусственному рассуждению, давая машинам возможность изучать сложные связи и принимать более совершенные решения.
Основы нейронных сетей
Чтобы понять суть глубокого обучения с подкреплением, нужно сначала разобраться с зачатками организации мозга. Мозговые сети олицетворяют конструкцию и возможности человеческого разума, включающие взаимосвязанные слои нейронов, которые циклически повторяют и изменяют входную информацию. Эти организации умело изучают прогрессивные представления, что позволяет им улавливать многогранные примеры и элементы внутри сложных наборов данных.
Архитектуры глубокого обучения
В области глубокого обучения с подкреплением принципиальным является понимание сложности структур глубокого обучения. Глубокие структуры обучения служат основой для многих вычислений высокого уровня, привлекая специалистов для получения сложных примеров и изображений из информации.
Исследуя эти структуры, мы можем выделить компоненты, которые позволяют специалистам обрабатывать и расшифровывать данные, работая с проницательной динамикой в уникальных условиях.
Сверточные нейронные сети (CNN)
Сверточные нейронные сети (CNN) имеют некоторый опыт обработки сетевой информации, такой как изображения и записи. Они влияют на сверточные слои, постепенно удаляя пространственные элементы, позволяя им выполнять самые современные задачи, такие как порядок изображений, распознавание объектов и деление.
Рекуррентные нейронные сети (RNN)
Рекуррентные нейронные сети (RNN) успешно обрабатывают последовательную информацию с временными условиями, например временными рядами и обычным языком. У них есть прерывистые ассоциации, которые позволяют им не отставать от памяти на протяжении временных интервалов, что делает их подходящими для таких задач, как отображение языка, машинный перевод и подтверждение разговора.
Глубокие Q-сети (DQN)
Deep Q-Networks (DQN) занимается конкретной разработкой для получения поддержки и консолидации глубоких мозговых сетей с расчетами Q-обучения. Эти организации придумывают, как приблизить возможности оценки деятельности, давая им возможность делать правильный выбор в условиях многоуровневого пространства состояний.
Обучение нейронных сетей
Обучение нейронных сетей — это базовая часть глубокого обучения с подкреплением, важная для того, чтобы дать возможность специалистам фактически получать и развивать свои динамические способности. Нейронные сети готовы использовать вычисления, например, обратное распространение ошибки и падение наклона, которые изменяют границы организации, чтобы ограничить ошибки ожиданий.
На протяжении всего цикла подготовки информация обрабатывается в организации, и модель итеративно определяет, как сделать более точные прогнозы. Итеративно обновляя границы организации с учетом замеченных ошибок, мозговые сети стабильно работают над представлением данного задания. Этот итеративный курс улучшения занимает центральное место в глубоком обучении с подкреплением, позволяя специалистам корректировать и оптимизировать свои системы в долгосрочной перспективе.
Обратное распространение ошибки
Обратное распространение ошибки служит основой подготовки мозговых структур, давая им возможность извлекать выгоду из информации путем итеративного изменения своих границ, чтобы ограничить ошибки ожиданий. Этот расчет показывает наклоны способности к несчастью для границ сети, работая с повышением производительности за счет падения наклона.
Градиентный спуск
Градиентный спуск лежит в основе расширения границ мозговой сети, направляя образовательный опыт к минимуму возможностей несчастья. Путем итеративного обновления границ в сторону самого крутого отвеса расчет угла падения дает возможность мозговым организациям присоединиться к идеальным схемам.
Читайте также: Глубокое обучение и машинное обучение: ключевые различия
Интеграция обучения с подкреплением и глубокого обучения
Координация обучения с подкреплением и глубокого обучения обеспечивает существенный прогресс в области искусственного сознания, синергетически используя качества двух идеальных моделей для решения сложных динамических задач с исключительной жизнеспособностью.
Последовательное сочетание стратегий глубокого обучения и обучения с поддержкой, раскрывающее понимание вдохновения, побуждающего их присоединиться, приближающихся трудностей, связанных с традиционным обучением с поддержкой, и новаторских преимуществ, предоставляемых сочетанием методов глубокого обучения.

Мотивация для глубокого обучения с подкреплением
Объединение глубокого обучения с подкреплением обусловлено миссией найти более универсальные, адаптируемые и эффективные способы обучения идеальным конфигурациям в сложных условиях. Традиционные вычисления обучения с подкреплением часто сталкиваются с многоуровневым пространством состояний и скудными призами, что мешает их применимости к реальным проблемам.
Глубокое обучение предлагает ответ, давая специалистам по обучению с подкреплением возможность получать прогрессивные изображения из грубых тактильных источников информации, давая им возможность извлекать замечательные элементы и примеры, имеющие фундаментальное значение для навигации.
Проблемы традиционного обучения с подкреплением
Традиционное обучение с подкреплением сталкивается с кучей трудностей, включая провал теста, непрямые и многоуровневые пространства состояний, а также проблему размерности. Кроме того, некоторые сертифицированные приложения предоставляют скудные и отложенные вознаграждения, что заставляет их пытаться использовать обычные вычисления RL для изучения мощных механизмов. Эти препятствия требуют внедрения глубоких методов обучения, чтобы преодолеть внутренние ограничения традиционного обучения с подкреплением.
Преимущества глубокого обучения в обучении с подкреплением
Консолидация глубокого обучения в обучении с подкреплением дает различные преимущества, реформируя эту область и открывая возможности для рывков вперед в различных областях.
Глубокие нейронные сети позволяют специалистам по обучению с подкреплением эффективно получать сложные сопоставления из грубых материальных вкладов в организацию деятельности, минуя необходимость ручного проектирования элементов.
Кроме того, методы глубокого обучения работают с предположением изученных подходов в различных условиях, повышая адаптивность и силу алгоритмов обучения с подкреплением.
Методология глубокого обучения с подкреплением
Углубление философии глубокого обучения с подкреплением открывает богатую картину систем и процедур, направленных на подготовку специалистов к выбору идеального выбора в сложных условиях.
Понимая эти процедуры, профессионалы приобретают опыт в основных компонентах растущего опыта, привлекая их к планированию более продуктивных и успешных алгоритмов обучения с подкреплением.
A. Обучение без модели и обучение с подкреплением на основе модели
При глубоком обучении с подкреплением выбор между подходами без модели и подходами на основе моделей обычно формирует образовательный опыт. Без модельных стратегий, по сути, можно напрямую получить идеальную стратегию, минуя требование однозначной модели климата.
С другой стороны, методы, основанные на моделях, включают изучение модели элементов климата и ее использование для разработки будущей деятельности. Каждый подход имеет свои преимущества и компромиссы, при этом модельные стратегии не обладают адаптивностью и универсальностью, в то время как методы, основанные на моделях, предлагают лучшие примеры эффективности и спекуляций.
Компромисс между разведкой и эксплуатацией
Двойная игра в расследовании лежит в основе обучения с подкреплением, определяя, как специалисты балансируют между оценкой новых действий для поиска возможно лучших стратегий (расследование) и использованием известной информации для увеличения быстрого вознаграждения (злоупотребление).
Расчеты глубокого обучения с подкреплением должны обеспечить некую гармонию между расследованием и злоупотреблениями, чтобы выучить идеальные стратегии в сложных условиях. Для изучения этого компромисса и управления процессом обучения используются различные процедуры исследования, такие как тестирование эпсилон-алкоголя, softmax и тестирование Томпсона.
Политические градиентные методы
Методы наклона стратегии относятся к классу вычислений обучения с подкреплением, которые напрямую оптимизируют границы соглашения для увеличения ожидаемого вознаграждения. Эти стратегии определяют стратегию как нейронную сеть и используют повышение наклона для обновления нагрузки организации из-за углов ожидаемой компенсации границ подхода.
Методы стратегического угла предлагают несколько преимуществ, в том числе способность работать с пространствами непрерывной деятельности и стохастическими стратегиями, что делает их подходящими для сложных задач в области глубокого обучения с подкреплением.
Методы функции значения
Методы оценки возможностей предназначены для оценки ценности состояний или совпадений состояний и действий, превращая опыт в нормальную прибыль в рамках данной стратегии. В расчетах глубокого обучения с подкреплением часто используются аппроксиматоры возможностей оценки, например, глубокие Q-сети (DQN), чтобы получить идеальную ценность возможностей.
Используя глубокие нейронные сети, методы оценки способностей могут неточно определять сложные ценовые характеристики и работать с профессиональным улучшением подхода и навигацией.
Актерско-критические методы
Методы актер-критик объединяют преимущества как стратегии наклона, так и методов оценки ценности, используя отдельные организации артистов и экспертов для одновременного изучения структуры и возможностей ценности.
Сеть акторов изучает параметры политики, а сеть критиков оценивает функцию ценности, чтобы обеспечить обратную связь о качестве действий.
Эта архитектура позволяет методам «актёр-критик» достигать баланса между стабильностью и эффективностью, что делает их широко используемыми в исследованиях и приложениях глубокого обучения с подкреплением.
Алгоритмы глубокого обучения с подкреплением
Копание в области алгоритмов обучения с подкреплением открывает другую картину систем, направленных на предоставление специалистам возможности самостоятельно учиться и приспосабливаться к сложным условиям. Эти расчеты направлены на то, чтобы глубокая организация мозга наделяла агентов обучения с подкреплением способностью исследовать ошеломляющие пространства выбора и через некоторое время улучшать свои способы поведения.
Глубокие Q-сети (DQN)
Deep Q-Networks (DQN) демонстрирует новый прогресс в области глубокого обучения с подкреплением, представляя сочетание глубоких нейронных сетей с вычислениями Q-обучения. Аппроксимируя возможности оценки активности с использованием структур мозга, DQN позволяют специалистам получать идеальные механизмы из многоуровневых пространств состояний, готовя их к рывку вперед в таких областях, как игры и робототехника.
Глубокий детерминированный политический градиент (DDPG)
Расчеты глубокого детерминированного политического градиента (DDPG) расширяют стандарты методов работы экспертов в сфере развлечений на постоянные пространства для деятельности, давая специалистам возможность изучать детерминистические подходы посредством подъема по склону. Объединив глубокие нейронные сети с расчетом наклона детерминированной стратегии, DDPG работает над изучением ошеломляющих механизмов управления в таких задачах, как механическое управление и независимое вождение.
Оптимизация проксимальной политики (PPO)
Расчеты оптимизации проксимальной политики (PPO) предлагают принципиальный способ оптимизации границ стратегии с помощью императивов доверительного округа, гарантируя стабильное и продуктивное обновление механизмов. Путем итеративного продвижения границ системы с использованием стохастического увеличения угла расчеты PPO обеспечивают передовую производительность в различных тестах поддержки обучения, демонстрируя надежность и универсальность в различных условиях.
Оптимизация политики доверительного региона (TRPO)
Расчеты по оптимизации политики доверительного региона (TRPO) сосредоточены на стабильности и производительности тестирования за счет обязательных обновлений структуры внутри доверительного округа, снижая риск огромных отклонений стратегии.
Используя ограничения доверительной области для управления обновлениями политик, алгоритмы TRPO демонстрируют улучшенные свойства сходимости и устойчивость к изменениям гиперпараметров, что делает их хорошо подходящими для реальных приложений обучения с подкреплением.
Асинхронное преимущество актер-критик (A3C)
В расчетах асинхронного преимущества «Актер-критик» (A3C) используются непараллельные циклы подготовки для ускорения обучения и дальнейшего повышения эффективности тестирования в проектах обучения с подкреплением. Используя различные равные элементы, связанные с климатом одновременно, расчеты A3C работают с более разнообразными исследованиями и позволяют специалистам изучать мощные механизмы в сложных и динамичных условиях.
Заключение
В целом, стратегия глубокого обучения с подкреплением является примером многоуровневого подхода к предоставлению машинам возможности учиться и самостоятельно принимать решения в сложных условиях. В ходе этого исследования мы углубились в основы обучения с подкреплением, координацию процедур глубокого обучения и различные проявления вычислений, способствующие прогрессу в этой области.
Понимая стандарты и стратегии центра, мы получаем знания о важности глубокого обучения с подкреплением при решении поддающихся сертификации проблем в различных областях: от сложной механики и игр до медицинского обслуживания и денег. По нашему плану, потенциальные возможности для дальнейшего развития и улучшения глубокого обучения с подкреплением безграничны.
Благодаря постоянному изучению и прогрессу мы можем ожидать значительно более точных расчетов, улучшенной адаптируемости и более широкого применения в различных условиях. Чтобы оставаться в курсе последних событий и присоединиться к обсуждению, поделитесь своими соображениями и критикой в комментариях ниже.
Не забудьте передать эти важные данные своим товарищам и партнерам, чтобы другие могли исследовать интересную вселенную глубокого обучения с подкреплением. Вместе мы сможем добиться прогресса и раскрыть максимальный потенциал искусственного интеллекта.