
ระเบียบวิธีของการเรียนรู้แบบเสริมกำลังเชิงลึกคืออะไร?
เผยแพร่แล้ว: 2024-02-28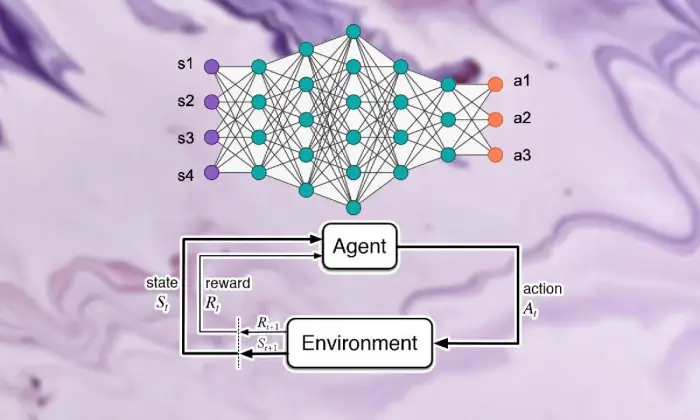
การเรียนรู้แบบเสริมกำลังเชิงลึกยังคงเป็นแนวหน้าของการให้เหตุผลโดยฝีมือมนุษย์ที่ล้ำสมัย โดยผสมผสานขอบเขตของการเรียนรู้อย่างลึกซึ้งและการสนับสนุนในการหาวิธีเพิ่มขีดความสามารถของเครื่องจักรในการเรียนรู้อย่างอิสระและตัดสินใจได้อย่างง่ายดาย
การเรียนรู้การเสริมกำลังเชิงลึก (DRL) รวมถึงการเตรียมการคำนวณเพื่อเชื่อมโยงกับสภาพอากาศและรับจากการวิพากษ์วิจารณ์ว่าเป็นค่าตอบแทนหรือการลงโทษ กระบวนการอันแข็งแกร่งนี้ผสานพลังสัญลักษณ์ของเครือข่ายสมองอันล้ำลึกเข้ากับความสามารถแบบไดนามิกของผู้เชี่ยวชาญด้านการเรียนรู้ที่สนับสนุน
DRL ได้รับการพิจารณาอย่างล้นหลามเนื่องจากทักษะที่โดดเด่นในการจัดการงานที่ซับซ้อนในพื้นที่ต่างๆ ตั้งแต่การเล่นเกมและเทคโนโลยีเครื่องจักรกลไปจนถึงการสนับสนุนและบริการทางการแพทย์ ความยืดหยุ่นและความอยู่รอดของโครงการทำให้เป็นรากฐานในขอบเขตของการตรวจสอบและการประยุกต์ใช้สติปัญญาทางคอมพิวเตอร์ ซึ่งมีแนวโน้มว่าจะมีผลกระทบพิเศษต่อกิจการและครูผู้สอน
ในขณะที่เราดำดิ่งลงลึกถึงความซับซ้อนของการเรียนรู้แบบเสริมกำลังเชิงลึก เราควรเปิดเผยแนวทางและคลี่คลายความสามารถที่แท้จริงของมันในการเปลี่ยนแปลงวิธีที่เครื่องจักรมองเห็นและทำงานร่วมกับสภาพแวดล้อมโดยทั่วไป

พื้นฐานของการเรียนรู้แบบเสริมกำลัง
การออกเดินทางเพื่อชมการเรียนรู้แบบเสริมกำลังเชิงลึกนั้นจำเป็นต้องอาศัยการจัดการที่สำคัญอย่างยิ่งในการเรียนรู้แบบสนับสนุน ศูนย์กลางของ RL คือโลกทัศน์ของ AI ที่เป็นกังวลว่าผู้เชี่ยวชาญจะทราบวิธีจัดการกับตัวเลือกที่ต่อเนื่องกันในบรรยากาศเพื่อเพิ่มรางวัลรวมได้อย่างไร
ภายในขอบเขตของการสนับสนุนการเรียนรู้ ส่วนสำคัญและแนวคิดบางส่วนถือเป็นส่วนสำคัญในการสร้างประสบการณ์ที่กำลังเติบโต เราควรเจาะเข้าไปในมุมเหล่านี้เพื่อคลี่คลายแก่นของวิธี RL:
แนวคิดพื้นฐานและคำศัพท์เฉพาะทาง
เพื่อทำความเข้าใจการเรียนรู้แบบเสริมกำลังเชิงลึก ในตอนแรกเราต้องยอมรับแนวคิดที่สำคัญและถ้อยคำที่แท้จริงเพื่อสนับสนุนการเรียนรู้ สิ่งเหล่านี้รวมเอาความคิดต่างๆ เช่น รัฐ กิจกรรม รางวัล และกลยุทธ์ ซึ่งเป็นโครงสร้างบล็อกโครงสร้างของการคำนวณ RL
องค์ประกอบของการเรียนรู้แบบเสริมกำลัง
ในฉากของการเรียนรู้แบบเสริมกำลังเชิงลึก การทำความเข้าใจส่วนพื้นฐานของการเรียนรู้แบบสนับสนุนเป็นสิ่งสำคัญ การเรียนรู้แบบสนับสนุนมีองค์ประกอบสำคัญบางประการที่กำหนดวิธีที่ผู้เชี่ยวชาญเชื่อมโยงกับสถานการณ์ปัจจุบันและเรียนรู้ระบบในอุดมคติหลังจากผ่านไประยะหนึ่ง
ส่วนเหล่านี้ รวมถึงผู้เชี่ยวชาญ ภูมิอากาศ กิจกรรม และรางวัล จะวางโครงสร้างบล็อคโครงสร้างของกรอบการเรียนรู้สนับสนุน การชื่นชมองค์ประกอบที่สำคัญเหล่านี้ทำให้เราได้รับความรู้เกี่ยวกับความสามารถในการคำนวณการเรียนรู้แบบเสริมกำลังเชิงลึกและวิธีการนำไปใช้เพื่อดูแลปัญหาไดนามิกที่น่าเหลือเชื่อ
ตัวแทน
ตัวแทนในการเรียนรู้แบบเสริมกำลังพาดพิงถึงเนื้อหาที่ตอบได้ง่ายในการตัดสินใจและเชื่อมโยงกับสภาพอากาศ โดยจะค้นพบวิธีสำรวจสภาพอากาศโดยคำนึงถึงการเผชิญหน้าและการวิพากษ์วิจารณ์ครั้งก่อนๆ ผ่านการให้ค่าตอบแทนหรือการลงโทษ
สิ่งแวดล้อม
สภาพแวดล้อมเป็นแบบอย่างของกรอบงานภายนอกที่ผู้เชี่ยวชาญร่วมมือ เป็นการวิจารณ์ผู้เชี่ยวชาญในขณะที่รัฐมีความก้าวหน้าและผลตอบแทน ก่อให้เกิดประสบการณ์ที่เพิ่มมากขึ้น
การดำเนินการ
การดำเนินการแสดงถึงการตัดสินใจที่ผู้เชี่ยวชาญสามารถเข้าถึงได้ในทุกจุดตัวเลือก ผู้เชี่ยวชาญเลือกกิจกรรมเนื่องจากสถานะปัจจุบันและผลลัพธ์ในอุดมคติ ซึ่งหมายถึงการเพิ่มรางวัลรวมในระยะยาว
รางวัล
รางวัลทำหน้าที่เป็นเครื่องมือป้อนข้อมูลสำหรับตัวแทน ซึ่งแสดงให้เห็นถึงความน่าดึงดูดใจของกิจกรรมต่างๆ รางวัลเชิงบวกก่อให้เกิดพฤติกรรมที่เป็นที่ต้องการ ในขณะที่รางวัลเชิงลบจะทำให้กิจกรรมที่โชคร้ายลดลง
กระบวนการตัดสินใจของมาร์คอฟ (MDP)
กระบวนการตัดสินใจของมาร์คอฟ (MDP) ให้โครงสร้างแบบเดิมเพื่อแสดงให้เห็นถึงปัญหาแบบไดนามิกที่ต่อเนื่องกันในการเรียนรู้แบบเสริมกำลัง ประกอบด้วยสถานะ กิจกรรม ความน่าจะเป็นในการเปลี่ยนแปลง และรางวัล ซึ่งเป็นตัวอย่างองค์ประกอบของสภาพอากาศในลักษณะความน่าจะเป็น
ทำความเข้าใจการเรียนรู้เชิงลึก
การละทิ้งการเดินทางไปชมการเรียนรู้แบบเสริมกำลังเชิงลึกเกี่ยวข้องกับการดำดิ่งลงสู่ขอบเขตของการเรียนรู้อย่างลึกซึ้ง ซึ่งเป็นส่วนพื้นฐานที่ช่วยให้การคำนวณสามารถแยกตัวอย่างที่ซับซ้อนและการแสดงภาพออกจากข้อมูลได้ การเรียนรู้เชิงลึกเติมเต็มเป็นรากฐานของวิธีการที่ดีที่สุดในระดับเดียวกันในการให้เหตุผลที่มนุษย์สร้างขึ้น ทำให้เครื่องจักรสามารถเรียนรู้การเชื่อมต่อที่ซับซ้อนและเลือกใช้ตัวเลือกที่ประณีต
พื้นฐานของโครงข่ายประสาทเทียม
เพื่อทำความเข้าใจแก่นสารของการเรียนรู้แบบเสริมกำลังเชิงลึก อันดับแรกเราต้องจัดการกับพื้นฐานของการจัดระเบียบของสมองก่อน เครือข่ายสมองเลียนแบบโครงสร้างและความสามารถของจิตใจมนุษย์ ซึ่งเกี่ยวข้องกับชั้นของเซลล์ประสาทที่เชื่อมต่อถึงกัน ซึ่งจะหมุนเวียนและเปลี่ยนแปลงข้อมูลอินพุต องค์กรเหล่านี้มีความชำนาญในการเรียนรู้การแสดงภาพแบบก้าวหน้า ช่วยให้พวกเขาสามารถจับตัวอย่างและองค์ประกอบจากหลายด้านภายในชุดข้อมูลที่ซับซ้อน
สถาปัตยกรรมการเรียนรู้เชิงลึก
ในขอบเขตของการเรียนรู้แบบเสริมกำลังเชิงลึก การทำความเข้าใจความซับซ้อนของโครงสร้างการเรียนรู้เชิงลึกเป็นสิ่งสำคัญ โครงสร้างการเรียนรู้ที่ลึกซึ้งทำหน้าที่เป็นรากฐานของการคำนวณระดับสูง ดึงดูดผู้เชี่ยวชาญเพื่อรับตัวอย่างที่ซับซ้อนและการพรรณนาจากข้อมูล
ด้วยการตรวจสอบโครงสร้างเหล่านี้ เราสามารถแยกองค์ประกอบที่ช่วยให้ผู้เชี่ยวชาญสามารถประมวลผลและถอดรหัสข้อมูลได้ โดยทำงานอย่างมีพลวัตในสภาวะที่ไม่ซ้ำใคร
โครงข่ายประสาทเทียมแบบหมุนวน (CNN)
Convolutional Neural Networks (CNN) มีความเชี่ยวชาญในการจัดการข้อมูลคล้ายเครือข่าย เช่น รูปภาพและการบันทึก พวกมันมีอิทธิพลต่อเลเยอร์แบบหมุนวนเพื่อลบองค์ประกอบเชิงพื้นที่ออกอย่างต่อเนื่อง ทำให้พวกเขาทำงานที่ได้รับมอบหมายที่ล้ำสมัย เช่น ลำดับรูปภาพ การจดจำวัตถุ และการแบ่งส่วน
โครงข่ายประสาทเทียมที่เกิดซ้ำ (RNN)
เครือข่ายประสาทที่เกิดซ้ำ (RNN) ประสบความสำเร็จในการดูแลข้อมูลที่ต่อเนื่องโดยมีเงื่อนไขชั่วคราว เช่น อนุกรมเวลาและภาษาปกติ มีการเชื่อมโยงเป็นระยะๆ ซึ่งช่วยให้สามารถตามทันหน่วยความจำตามขั้นตอนของเวลา ทำให้เหมาะสำหรับงานต่างๆ เช่น การแสดงภาษา การตีความด้วยเครื่อง และการรับทราบวาทกรรม
Deep Q-Networks (DQN)
Deep Q-Networks (DQN) กล่าวถึงวิศวกรรมเฉพาะสำหรับการสนับสนุนและรวบรวมเครือข่ายสมองส่วนลึกด้วยการคำนวณ Q-learning องค์กรเหล่านี้คิดหาวิธีคร่าวๆ เกี่ยวกับความสามารถในการประเมินคุณค่าของกิจกรรม โดยเสริมศักยภาพให้พวกเขาตัดสินใจเลือกทางเลือกที่เหมาะสมที่สุดในสภาพแวดล้อมที่มีพื้นที่รัฐที่มีชั้นสูง
การฝึกอบรมโครงข่ายประสาทเทียม
การฝึกอบรมโครงข่ายประสาทเทียมเป็นส่วนพื้นฐานของการเรียนรู้แบบเสริมกำลังเชิงลึก ซึ่งมีความสำคัญในการเสริมศักยภาพให้ผู้เชี่ยวชาญได้รับตามความเป็นจริง และพัฒนาขีดความสามารถแบบไดนามิกต่อไป โครงข่ายประสาทเทียมได้รับการจัดเตรียมเพื่อใช้การคำนวณ เช่น การแพร่กระจายกลับและความลาดชัน ซึ่งเปลี่ยนขอบเขตขององค์กรเพื่อจำกัดความผิดพลาดที่คาดหวัง
ตลอดวงจรการเตรียมการ ข้อมูลจะได้รับการดูแลในองค์กร และแบบจำลองจะระบุวิธีคาดการณ์ที่แม่นยำยิ่งขึ้นซ้ำๆ โดยการรีเฟรชขอบเขตขององค์กรซ้ำแล้วซ้ำเล่าเมื่อเกิดข้อผิดพลาดที่สังเกตเห็น เครือข่ายสมองจึงทำงานอย่างต่อเนื่องในการนำเสนอภารกิจที่ได้รับ หลักสูตรการปรับปรุงซ้ำนี้ถือเป็นส่วนสำคัญในการเรียนรู้แบบเสริมกำลังเชิงลึก ซึ่งช่วยให้ผู้เชี่ยวชาญสามารถปรับและปรับปรุงระบบของตนได้ในระยะยาว
การขยายพันธุ์กลับ
Backpropagation เติมเต็มเป็นรากฐานในการเตรียมองค์กรของสมอง ช่วยให้พวกเขาได้รับข้อมูลจากข้อมูลโดยการเปลี่ยนขอบเขตซ้ำๆ เพื่อจำกัดความผิดพลาดจากการคาดหวัง การคำนวณนี้แสดงถึงความลาดชันของขีดความสามารถที่โชคร้ายสำหรับขอบเขตของเครือข่าย โดยทำงานร่วมกับการเพิ่มประสิทธิภาพการผลิตผ่านการโน้มเอียง
การไล่ระดับโคตร
การไล่ระดับสีเป็นหัวใจสำคัญของการเพิ่มขอบเขตเครือข่ายสมอง โดยนำประสบการณ์การศึกษาไปสู่ขีดความสามารถที่โชคร้ายน้อยที่สุด ด้วยการปรับปรุงขอบเขตซ้ำ ๆ ไปสู่การดิ่งลงที่ชันที่สุด การคำนวณการดิ่งลงของมุมช่วยให้องค์กรสมองสามารถเข้าร่วมการจัดเตรียมในอุดมคติ
อ่านเพิ่มเติม: การเรียนรู้เชิงลึกกับการเรียนรู้ของเครื่อง: ความแตกต่างที่สำคัญ
การบูรณาการการเรียนรู้แบบเสริมแรงและการเรียนรู้เชิงลึก
การประสานการเรียนรู้แบบเสริมกำลังกับการเรียนรู้เชิงลึกกล่าวถึงความก้าวหน้าที่สำคัญในขอบเขตของจิตสำนึกที่มนุษย์สร้างขึ้น โดยใช้คุณสมบัติของแบบจำลองในอุดมคติทั้งสองแบบทำงานร่วมกันเพื่อจัดการกับการดำเนินการแบบไดนามิกที่ซับซ้อนและมีชีวิตที่ยอดเยี่ยม

การผสมผสานที่ลงตัวของการเรียนรู้เชิงลึกและกลยุทธ์การเรียนรู้แบบสนับสนุน เผยให้เห็นข้อมูลเชิงลึกเกี่ยวกับแรงบันดาลใจที่ผลักดันให้เกิดการเข้าร่วม ความยากลำบากที่นำเสนอโดยการเรียนรู้แบบสนับสนุนตามธรรมเนียมกำลังใกล้เข้ามา และข้อได้เปรียบที่ก้าวล้ำที่ได้รับจากการผสมผสานของวิธีการเรียนรู้ที่ลึกซึ้ง
แรงจูงใจในการเรียนรู้แบบเสริมกำลังเชิงลึก
การเข้าร่วมการเรียนรู้แบบเสริมกำลังเชิงลึกได้รับแรงผลักดันจากภารกิจเพื่อให้มีวิธีที่หลากหลาย ปรับเปลี่ยนได้ และมีประสิทธิภาพมากขึ้นในการจัดการกับการจัดการการเรียนรู้ในอุดมคติในสภาวะที่ซับซ้อน การคำนวณการเรียนรู้แบบเสริมกำลังแบบเดิมๆ มักจะต่อสู้กับพื้นที่ของรัฐที่มีชั้นสูงและรางวัลน้อย ซึ่งขัดขวางความเหมาะสมกับปัญหาที่แท้จริง
การเรียนรู้เชิงลึกเสนอคำตอบโดยการเพิ่มคุณค่าให้ผู้เชี่ยวชาญด้านการเรียนรู้แบบเสริมกำลังด้วยความสามารถในการรับภาพแบบก้าวหน้าจากแหล่งข้อมูลที่สัมผัสได้อย่างหยาบๆ ช่วยให้พวกเขาสามารถดึงองค์ประกอบที่น่าทึ่งและตัวอย่างที่เป็นพื้นฐานในการนำทางออกมาได้
ความท้าทายของการเรียนรู้การเสริมกำลังแบบดั้งเดิม
การเรียนรู้การเสริมกำลังแบบเดิมๆ เผชิญกับความยากลำบากมากมาย รวมถึงความล้มเหลวในการทดสอบ พื้นที่รัฐที่ไม่โดยตรงและเป็นชั้นสูง และหายนะของมิติ นอกจากนี้ ใบสมัครที่ได้รับการรับรองบางรายการยังให้รางวัลน้อยและถูกเลื่อนออกไป ทำให้พยายามใช้การคำนวณ RL ตามปกติเพื่อเรียนรู้การเตรียมการที่มีประสิทธิภาพ อุปสรรคเหล่านี้จำเป็นต้องอาศัยวิธีการเรียนรู้ที่ลึกซึ้งเพื่อเอาชนะข้อจำกัดที่แท้จริงของการเรียนรู้แบบเสริมกำลังแบบดั้งเดิมที่ใกล้เข้ามา
ประโยชน์ของการเรียนรู้เชิงลึกในการเรียนรู้แบบเสริมกำลัง
การรวมการเรียนรู้เชิงลึกเข้าด้วยกันในการเรียนรู้แบบเสริมกำลังทำให้เกิดข้อได้เปรียบหลายประการ การปฏิรูปภาคสนามและเพิ่มศักยภาพในการก้าวกระโดดในด้านต่างๆ
โครงข่ายประสาทเทียมระดับลึกช่วยให้ผู้เชี่ยวชาญด้านการเรียนรู้แบบเสริมแรงสามารถรับการแมปที่ซับซ้อนได้อย่างมีประสิทธิภาพ ตั้งแต่การมีส่วนร่วมที่จับต้องได้ไปจนถึงการจัดกิจกรรม โดยข้ามข้อกำหนดสำหรับการออกแบบองค์ประกอบด้วยตนเอง
นอกจากนี้ วิธีการเรียนรู้อย่างลึกซึ้งยังทำงานร่วมกับการคาดเดาแนวทางการเรียนรู้ในสภาวะต่างๆ เป็นการยกระดับความสามารถในการปรับตัวและความแข็งแกร่งของอัลกอริธึมการเรียนรู้แบบเสริมกำลัง
ระเบียบวิธีการเรียนรู้แบบเสริมกำลังเชิงลึก
การเจาะลึกปรัชญาของการเรียนรู้แบบเสริมกำลังเชิงลึกเผยให้เห็นฉากอันหลากหลายของระบบและขั้นตอนที่มุ่งไปสู่การเตรียมผู้เชี่ยวชาญเพื่อตัดสินใจเลือกทางเลือกในอุดมคติในสภาวะที่ซับซ้อน
โดยการทำความเข้าใจขั้นตอนเหล่านี้ ผู้เชี่ยวชาญจะได้รับประสบการณ์ในองค์ประกอบพื้นฐานของประสบการณ์ที่เพิ่มขึ้น โดยชักจูงให้พวกเขาวางแผนอัลกอริธึมการเรียนรู้แบบเสริมกำลังที่มีประสิทธิผลและประสบความสำเร็จมากขึ้น
ก. การเรียนรู้แบบเสริมแรงแบบไร้โมเดลกับแบบเสริมตามโมเดล
ในการเรียนรู้แบบเสริมกำลังเชิงลึก การตัดสินใจระหว่างโมเดล sans และแนวทางที่ใช้โมเดลโดยทั่วไปจะกำหนดประสบการณ์ทางการศึกษา หากไม่มีกลยุทธ์แบบจำลอง ก็จะได้กลยุทธ์ในอุดมคติโดยแท้จริงแล้ว โดยข้ามข้อกำหนดสำหรับแบบจำลองสภาพภูมิอากาศที่ชัดเจน
ในทางกลับกัน เทคนิคตามแบบจำลอง ได้แก่ การเรียนรู้แบบจำลององค์ประกอบสภาพภูมิอากาศ และนำไปใช้ในการออกแบบกิจกรรมในอนาคต แต่ละแนวทางได้รับประโยชน์และการประนีประนอม หากไม่มีกลยุทธ์แบบจำลองที่ประสบความสำเร็จในการปรับตัวและความคล่องตัว ในขณะที่เทคนิคตามแบบจำลองเสนอตัวอย่างที่ดีกว่าของประสิทธิผลและการเก็งกำไร
การสำรวจกับการแลกเปลี่ยนผลประโยชน์
การแลกเปลี่ยนการซื้อขายสองครั้งของการสืบสวนอยู่ที่แกนหลักของการเรียนรู้แบบเสริมกำลัง โดยกำหนดวิธีที่ผู้เชี่ยวชาญสร้างสมดุลระหว่างการประเมินกิจกรรมใหม่ ๆ เพื่อค้นหากลยุทธ์ที่ดีกว่า (การสอบสวน) และการใช้ประโยชน์จากข้อมูลที่ทราบเพื่อเพิ่มรางวัลอย่างรวดเร็ว (การละเมิด)
การคำนวณการเรียนรู้แบบเสริมกำลังเชิงลึกควรทำให้เกิดความสอดคล้องกันระหว่างการสืบสวนและการละเมิด เพื่อเรียนรู้กลยุทธ์ในอุดมคติในสภาวะที่ซับซ้อน ขั้นตอนการตรวจสอบที่แตกต่างกัน เช่น การทดสอบ epsilon-avaricious, softmax และ Thompson ถูกนำมาใช้เพื่อสำรวจข้อดีนี้และเป็นแนวทางในกระบวนการเรียนรู้
วิธีการไล่ระดับนโยบาย
เทคนิคความลาดชันของกลยุทธ์เน้นถึงคลาสของการคำนวณการเรียนรู้แบบเสริมกำลังที่ปรับปรุงขอบเขตการจัดการอย่างตรงไปตรงมาเพื่อขยายรางวัลที่คาดหวัง กลยุทธ์เหล่านี้กำหนดกลยุทธ์ว่าเป็นโครงข่ายประสาทเทียม และใช้ความลาดชันที่เพิ่มขึ้นเพื่อรีเฟรชภาระงานขององค์กร เนื่องจากมุมของการชดเชยที่คาดการณ์ไว้สำหรับขอบเขตแนวทาง
เทคนิคมุมกลยุทธ์ให้ประโยชน์บางประการ รวมถึงความสามารถในการจัดการกับพื้นที่กิจกรรมที่ไม่หยุดยั้งและกลยุทธ์สุ่ม ทำให้เหมาะสำหรับการดำเนินการที่ซับซ้อนในการเรียนรู้แบบเสริมกำลังเชิงลึก
วิธีการฟังก์ชันค่า
เทคนิคความสามารถในการเห็นคุณค่ามีจุดมุ่งหมายเพื่อวัดมูลค่าของรัฐหรือกิจกรรมของรัฐที่ตรงกัน โดยให้ประสบการณ์ในผลตอบแทนปกติภายใต้กลยุทธ์ที่กำหนด การคำนวณการเรียนรู้แบบเสริมกำลังเชิงลึกมักใช้ตัวประมาณความสามารถในการประเมิน เช่น เครือข่าย Q เชิงลึก (DQN) เพื่อให้ได้ความสามารถที่คุ้มค่าในอุดมคติ
ด้วยการใช้โครงข่ายประสาทเทียมระดับลึก เทคนิคการยกย่องความสามารถอาจทำให้ความสามารถที่คุ้มค่าซับซ้อนไม่แน่นอน และทำงานด้วยการปรับปรุงแนวทางและการนำทางอย่างเชี่ยวชาญ
วิธีการนักแสดง-นักวิจารณ์
วิธีการวิจารณ์นักแสดงจะรวมข้อดีของทั้งความลาดชันของกลยุทธ์และเทคนิคความสามารถที่คุ้มค่า โดยใช้องค์กรบันเทิงและผู้เชี่ยวชาญที่แยกจากกันเพื่อทำความคุ้นเคยกับการจัดการและความสามารถที่คุ้มค่าไปพร้อมๆ กัน
เครือข่ายนักแสดงเรียนรู้พารามิเตอร์นโยบาย ในขณะที่เครือข่ายนักวิจารณ์ประเมินฟังก์ชันค่าเพื่อให้ข้อเสนอแนะเกี่ยวกับคุณภาพของการดำเนินการ
สถาปัตยกรรมนี้ช่วยให้วิธีการที่นักแสดงและนักวิจารณ์บรรลุความสมดุลระหว่างความเสถียรและประสิทธิภาพ ทำให้มีการใช้กันอย่างแพร่หลายในการวิจัยและการประยุกต์ใช้การเรียนรู้แบบเสริมกำลังเชิงลึก
อัลกอริทึมการเรียนรู้การเสริมกำลังเชิงลึก
การเจาะลึกเข้าไปในขอบเขตของอัลกอริธึมการเรียนรู้แบบเสริมกำลังจะเผยให้เห็นฉากต่างๆ ของระบบที่มุ่งสู่การเสริมศักยภาพผู้เชี่ยวชาญในการเรียนรู้อย่างอิสระและปรับตัวให้เข้ากับเงื่อนไขที่ซับซ้อน การคำนวณเหล่านี้จัดการกับพลังขององค์กรสมองส่วนลึกเพื่อปลูกฝังตัวแทนการเรียนรู้ที่เสริมกำลังด้วยความสามารถในการสำรวจทางเลือกที่เหลือเชื่อ และปรับปรุงวิธีปฏิบัติตนหลังจากผ่านไประยะหนึ่ง
Deep Q-เครือข่าย (DQN)
Deep Q-Networks (DQN) กล่าวถึงความก้าวหน้าดั้งเดิมในการเรียนรู้แบบเสริมกำลังเชิงลึก โดยนำเสนอการผสมผสานของโครงข่ายประสาทเชิงลึกเข้ากับการคำนวณ Q-learning ด้วยการประมาณความสามารถในการประเมินคุณค่าของกิจกรรมโดยใช้องค์กรทางสมอง DQN ช่วยให้ผู้เชี่ยวชาญได้รับการจัดเตรียมที่เหมาะสมจากพื้นที่ของรัฐที่มีชั้นสูง ทำให้พวกเขาพร้อมสำหรับการก้าวกระโดดไปข้างหน้าในด้านต่างๆ เช่น เกมและหุ่นยนต์
การไล่ระดับนโยบายกำหนดเชิงลึก (DDPG)
การคำนวณการไล่ระดับนโยบายกำหนดเชิงลึก (DDPG) ขยายมาตรฐานของเทคนิคผู้รอบรู้ด้านความบันเทิงให้ครอบคลุมพื้นที่กิจกรรมคงที่ ช่วยให้ผู้เชี่ยวชาญเรียนรู้แนวทางที่กำหนดผ่านการปีนทางลาด ด้วยการรวมเครือข่ายสมองที่ลึกซึ้งเข้ากับการคำนวณความชันของกลยุทธ์ที่กำหนด DDPG ทำงานร่วมกับการเรียนรู้การจัดการการควบคุมที่เหลือเชื่อในการดำเนินการต่างๆ เช่น การควบคุมด้วยกลไกและการขับขี่แบบอิสระ
การเพิ่มประสิทธิภาพนโยบายใกล้เคียง (PPO)
การคำนวณ Proximal Policy Optimization (PPO) เสนอวิธีการที่มีหลักการในการจัดการกับขอบเขตกลยุทธ์ที่เพรียวบางผ่านความจำเป็นของเขตความไว้วางใจ รับประกันการรีเฟรชการจัดการที่มั่นคงและมีประสิทธิผล ด้วยการพัฒนาขอบเขตการจัดการซ้ำๆ โดยใช้มุมสุ่มที่เพิ่มขึ้น การคำนวณ PPO จึงบรรลุการดำเนินการที่ล้ำสมัยในเกณฑ์มาตรฐานการเรียนรู้การสนับสนุนที่แตกต่างกัน แสดงให้เห็นถึงความเอาใจใส่และความคล่องตัวในเงื่อนไขต่างๆ
การเพิ่มประสิทธิภาพนโยบายภูมิภาคที่เชื่อถือได้ (TRPO)
การคำนวณการเพิ่มประสิทธิภาพนโยบายภูมิภาคที่เชื่อถือได้ (TRPO) มุ่งเน้นไปที่ความมั่นคงและทดสอบประสิทธิภาพการทำงานโดยกำหนดให้ต้องมีการรีเฟรชภายในเขตความน่าเชื่อถือ และควบคุมการเดิมพันของการเบี่ยงเบนทางกลยุทธ์ครั้งใหญ่
ด้วยการใช้ประโยชน์จากข้อจำกัดของภูมิภาคที่เชื่อถือได้เพื่อเป็นแนวทางในการอัปเดตนโยบาย อัลกอริธึม TRPO จะแสดงคุณสมบัติการลู่เข้าที่ได้รับการปรับปรุงและความคงทนต่อการเปลี่ยนแปลงของไฮเปอร์พารามิเตอร์ ทำให้เหมาะสำหรับแอปพลิเคชันการเรียนรู้แบบเสริมกำลังในโลกแห่งความเป็นจริง
นักแสดง-นักวิจารณ์ที่ได้เปรียบแบบอะซิงโครนัส (A3C)
การคำนวณแบบอะซิงโครนัส Advantage Actor-Critic (A3C) ใช้วงจรการเตรียมการที่ไม่พร้อมกันเพื่อเร่งการเรียนรู้และพัฒนาประสิทธิภาพการทดสอบในการเรียนรู้แบบเสริมกำลัง ด้วยการใช้ผู้ให้ความบันเทิงที่เท่าเทียมกันที่แตกต่างกันโดยเชื่อมโยงกับสภาพอากาศแบบไม่พร้อมกัน การคำนวณ A3C จะทำงานร่วมกับการตรวจสอบที่หลากหลายยิ่งขึ้น และช่วยให้ผู้เชี่ยวชาญสามารถเรียนรู้การจัดการที่ทรงพลังในสภาวะที่ซับซ้อนและไดนามิก
บทสรุป
โดยรวมแล้ว กลยุทธ์ของการเรียนรู้แบบเสริมกำลังเชิงลึกเป็นตัวอย่างของวิธีการหลายชั้นในการจัดการกับการเพิ่มขีดความสามารถให้กับเครื่องจักรในการเรียนรู้และดำเนินการเลือกอย่างอิสระในสภาวะที่ซับซ้อน จากการตรวจสอบนี้ เราได้เจาะลึกถึงสิ่งสำคัญของการเรียนรู้แบบเสริมกำลัง การประสานงานของขั้นตอนการเรียนรู้อย่างลึกซึ้ง และการจัดแสดงการคำนวณต่างๆ ที่ขับเคลื่อนความก้าวหน้าในสาขานี้
ด้วยการทำความเข้าใจมาตรฐานและกลยุทธ์ของศูนย์ เราจึงได้รับความรู้เกี่ยวกับความสำคัญของการเรียนรู้แบบเสริมกำลังเชิงลึกในการจัดการกับปัญหาที่ได้รับการรับรองในพื้นที่ต่างๆ ตั้งแต่กลไกขั้นสูงและการเล่นเกมไปจนถึงการรักษาพยาบาลและเงิน ตามที่เราวางแผนไว้ ศักยภาพในการเปิดประตูสู่ความก้าวหน้าและการปรับปรุงเพิ่มเติมในการเรียนรู้แบบเสริมกำลังเชิงลึกนั้นมีไม่จำกัด
ด้วยการตรวจสอบและความก้าวหน้าอย่างต่อเนื่อง เราคาดหวังได้ว่าจะมีการคำนวณที่ละเอียดยิ่งขึ้น ความสามารถในการปรับตัวที่ดีขึ้น และความเกี่ยวข้องที่ครอบคลุมมากขึ้นในสภาพแวดล้อมที่แตกต่างกัน หากต้องการติดตามความเคลื่อนไหวล่าสุดและเข้าร่วมการสนทนา โปรดแชร์ข้อควรพิจารณาและคำวิจารณ์ของคุณในหมายเหตุด้านล่าง
อย่าลืมให้ข้อมูลที่สำคัญนี้แก่เพื่อนและคู่ของคุณ เพื่อให้ผู้อื่นสามารถตรวจสอบจักรวาลที่น่าสนใจของการเรียนรู้แบบเสริมกำลังเชิงลึก เมื่อร่วมมือกัน เราจะขับเคลื่อนความก้าวหน้าและเปิดศักยภาพสูงสุดของปัญญาประดิษฐ์ได้