
Derin Güçlendirmeli Öğrenmenin Metodolojisi Nedir?
Yayınlanan: 2024-02-28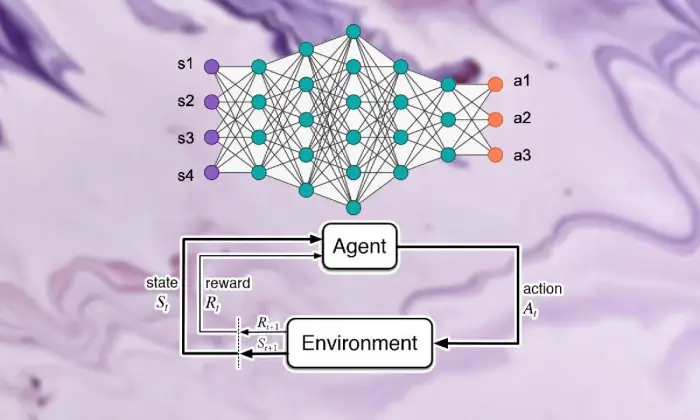
Derin takviyeli öğrenme, son teknoloji ürünü insan yapımı akıl yürütmenin en ön saflarında yer almayı sürdürüyor; derin öğrenmenin alanlarını karıştırıyor ve makinelerin bağımsız olarak öğrenmesi ve basit bir şekilde karar vermesi için nasıl güçlendirileceğini bulmayı destekliyor.
Derin takviyeli öğrenme (DRL), bir iklimle bağlantı kurmak için hesaplamalar hazırlamayı ve eleştiriden ücret veya ceza olarak kazanç sağlamayı içerir. Bu güçlü prosedür, derin beyin ağlarının sembolik gücünü, destekleyici öğrenme uzmanlarının dinamik kapasiteleriyle birleştirir.
DRL, oyun ve mekanik teknolojiden sırt ve tıbbi hizmetlere kadar farklı alanlardaki karmaşık görevlerin üstesinden gelme konusundaki çarpıcı becerisi nedeniyle büyük ilgi topladı. Esnekliği ve uygulanabilirliği, onu bilgisayar tabanlı istihbarat incelemesi ve uygulaması alanında bir temel haline getirerek girişimler ve öğretmenler arasında olağanüstü etkiler vaat ediyor.
Derin takviyeli öğrenmenin karmaşıklıklarına daha da daldıkça, onun yaklaşımını ortaya çıkarmalı ve makinelerin genel çevrelerini görme ve onlarla işbirliği yapma şeklini değiştirmeye yönelik gerçek kapasitesini ortaya çıkarmalıyız.

Takviyeli Öğrenmenin Temelleri
Derin takviyeli öğrenmeyi görme gezisine çıkmak, destekleyici öğrenmenin temellerini güçlü bir şekilde ele almayı gerektirir. Merkezinde RL, uzmanların birleşik ödülleri artırmak için bir ortamda ardışık seçimlere nasıl karar vereceklerini nasıl anlayacakları konusunda endişe duyan yapay zekanın dünya görüşünü içeriyor.
Destek öğrenimi alanında, birkaç hayati parça ve fikir, büyüyen deneyimin oluşturulmasında önemli rol oynar. RL yaklaşımının özünü çözmek için bu açıları incelemeliyiz:
Temel Kavramlar ve Terminoloji
Derin takviyeli öğrenmeyi anlamak için öncelikle öğrenmeyi destekleyen temel fikirleri ve ifadeleri kabul etmek gerekir. Bunlar, RL hesaplamalarının yapı bloklarını yapılandıran durum, etkinlik, ödül ve strateji gibi düşünceleri içerir.
Takviyeli Öğrenmenin Bileşenleri
Derin takviyeli öğrenme ortamında, destekleyici öğrenmenin temel kısımlarını anlamak hayati öneme sahiptir. Destek öğrenimi, uzmanların mevcut durumlarıyla nasıl bağlantı kuracaklarını ve bir süre sonra ideal sistemleri nasıl öğreneceklerini şekillendiren birkaç temel bileşeni içerir.
Uzmanlık, iklim, etkinlikler ve ödülleri içeren bu bölümler, destekleyici öğrenme çerçevelerinin yapı bloklarını yapılandırır. Bu temel bileşenleri takdir ederek, takviyeli öğrenme hesaplamalarının ne kadar derin olduğu ve bunların akıllara durgunluk veren dinamik sorunların çözümünde nasıl uygulandığı hakkında bilgi edinebiliriz.
Ajan
Takviyeli öğrenmedeki ajan, iklime karar vermek ve onunla bağlantı kurmakla sorumlu olan maddeyi ima eder. Önceki karşılaşmaların ve ücret veya ceza yoluyla yapılan eleştirilerin ışığında ortamın nasıl keşfedileceğini çözer.
Çevre
Çevre, uzmanın işbirliği yaptığı dış çerçevenin tipik bir örneğidir. Devlet ilerledikçe ve ödüllendirdikçe uzmana eleştiri verir, büyüyen deneyimi oluşturur.
Hareketler
Eylemler, uzmanın her seçim noktasında erişebileceği kararları temsil eder. Uzman, etkinlikleri mevcut durumlarına ve ideal sonuçlarına göre seçer, bu da uzun vadede birleşik ödülleri artırmak anlamına gelir.
Ödüller
Ödüller, acentenin faaliyetlerinin çekiciliğini gösteren bir girdi aracı görevi görür. Olumlu ödüller istenen davranış biçimlerini geliştirirken, olumsuz ödüller talihsiz faaliyetleri bastırır.
Markov Karar Süreçleri (MDP'ler)
Markov Karar Süreçleri (MDP'ler), takviyeli öğrenmede ardışık dinamik konuların gösterilmesine geleneksel bir yapı kazandırır. İklim unsurlarını olasılıksal bir şekilde örnekleyen durumlar, faaliyetler, değişim olasılıkları ve ödüllerden oluşurlar.
Derin Öğrenmeyi Anlamak
Derin takviyeli öğrenmeyi görme gezisinden ayrılmak, karmaşık örnekleri ve tasvirleri bilgilerden ayırmak için hesaplamalara olanak tanıyan temel bir kısım olan derin öğrenme alanına dalmayı içerir. Derin öğrenme, makinelere karmaşık bağlantıları öğrenme ve rafine seçimler yapma yeteneği vererek, insan yapımı akıl yürütmede sınıfının en iyisi yaklaşımların temelini oluşturuyor.
Sinir Ağlarının Temelleri
Derin takviyeli öğrenmenin içeriğini anlamak için öncelikle beyin organizasyonunun temellerini kavramak gerekir. Beyin ağları, girdi bilgisini değiştiren ve değiştiren birbirine bağlı nöron katmanlarını içeren, insan zihninin yapısını ve yeteneğini taklit eder. Bu kuruluşlar, ilerici tasvirleri öğrenme konusunda beceriklidir ve karmaşık veri kümeleri içindeki çok yönlü örnekleri ve unsurları yakalamalarını sağlar.
Derin Öğrenme Mimarileri
Derin takviyeli öğrenme alanında derin öğrenme yapılarının karmaşıklığını anlamak esastır. Derin öğrenme yapıları, birçok üst düzey hesaplamanın temeli olarak hareket ederek uzmanların bilgilerden karmaşık örnekler ve tasvirler elde etmelerini sağlar.
Bu yapıları inceleyerek, uzmanların benzersiz koşullarda akıllı dinamiklerle çalışarak verileri işlemesine ve şifresini çözmesine olanak tanıyan bileşenleri çözebiliriz.
Evrişimli Sinir Ağları (CNN'ler)
Evrişimli Sinir Ağları (CNN'ler), resimler ve kayıtlar gibi ağ benzeri bilgilerin işlenmesinde bazı uzmanlığa sahiptir. Uzamsal öğeleri kademeli olarak kaldırmak için evrişimli katmanları etkileyerek resim sırası, nesne tanıma ve bölme gibi son teknoloji görevleri gerçekleştirmelerini sağlarlar.
Tekrarlayan Sinir Ağları (RNN'ler)
Tekrarlayan Sinir Ağları (RNN'ler), zaman serileri ve normal dil gibi geçici koşullarla ardışık bilgileri yönetmeyi başarır. Zaman adımlarında hafızaya ayak uydurmalarına olanak tanıyan aralıklı çağrışımlara sahiptirler; bu da onları dil görüntüleme, makine yorumlaması ve söylem onaylama gibi görevler için uygun kılar.
Derin Q-Ağları (DQN'ler)
Derin Q-Ağları (DQN'ler), destek toplama ve derin beyin ağlarını Q-öğrenme hesaplamalarıyla birleştirmeye yönelik özel bir mühendisliği ele alır. Bu kuruluşlar, yüksek katmanlı devlet alanlarının olduğu koşullarda ideal seçimler yapma konusunda onları güçlendirerek, aktivite saygısı yeteneğini nasıl geliştireceklerini buluyorlar.
Sinir Ağlarının Eğitimi
Sinir ağlarının eğitimi, derin takviyeli öğrenmenin temel bir parçasıdır ve uzmanların aslında kazanç elde etmelerini ve dinamik kapasitelerini daha da geliştirmelerini sağlamada önemlidir. Sinir ağları, beklenti hatalarını sınırlamak için kuruluşun sınırlarını değiştiren geri yayılım ve eğim düşüşü gibi hesaplamaları kullanmaya hazırdır.
Tüm hazırlık döngüsü boyunca, organizasyonda bilgiyle ilgilenilir ve model, daha kesin tahminlerin nasıl yapılacağını yinelemeli olarak belirler. Beyin ağları, fark edilen hatalar göz önüne alındığında organizasyonun sınırlarını yinelemeli olarak yenileyerek, verilen işin sunumu üzerinde sürekli olarak çalışır. Bu yinelemeli iyileştirme süreci, derin takviyeli öğrenmede odak noktasını üstlenir ve uzmanların sistemlerini uzun vadede ayarlamasına ve kolaylaştırmasına olanak tanır.
Geri yayılım
Geri yayılım, beyin organizasyonlarını hazırlamanın, beklenti hatalarını sınırlamak için sınırlarını yinelemeli olarak değiştirerek beyin organizasyonlarını bilgiden kazanmaları için güçlendirmenin temelini oluşturur. Bu hesaplama, eğim dalması yoluyla verimli bir iyileştirme ile çalışan ağ sınırları için talihsizlik yeteneğinin eğimlerini gösterir.
Dereceli alçalma
Kademeli iniş, beyin ağı sınırlarını güçlendirmenin temelinde yer alır ve eğitim deneyimini talihsizlik kapasitesinin minimumuna doğru yönlendirir. Açı dalma hesaplamaları, sınırları en dik düşüşe doğru tekrar tekrar yenileyerek beyin organizasyonlarının ideal düzenlemelere katılmasını sağlar.
Ayrıca Okuyun: Derin Öğrenme ve Makine Öğrenimi: Temel Farklılıklar
Takviyeli Öğrenme ve Derin Öğrenmenin Entegrasyonu
Takviyeli öğrenmeyi derin öğrenmeyle koordine etmek, karmaşık dinamik girişimleri olağanüstü uygulanabilirlikle ele almak için iki ideal modelin niteliklerini sinerjik olarak kullanarak, insan yapımı bilinç alanında önemli bir ilerlemeyi ele alır.
Derin öğrenme ve destekleyici öğrenme stratejilerinin tutarlı birleşimi, bunların katılmasını sağlayan ilhamlara ilişkin içgörüyü açığa çıkarıyor, geleneksel destek öğrenmenin sunduğu zorluklar yaklaşıyor ve derin öğrenme yöntemlerinin birleşiminin sağladığı çığır açıcı avantajlar.

Derin Güçlendirmeli Öğrenme Motivasyonu
Derin takviyeli öğrenmenin birleştirilmesi, karmaşık koşullarda ideal öğrenme düzenlemeleriyle başa çıkmanın daha çok yönlü, uyarlanabilir ve etkili yollarını bulma misyonu tarafından yönlendirilmektedir. Geleneksel takviyeli öğrenme hesaplamaları sıklıkla yüksek katmanlı durum uzayları ve yetersiz ödüllerle mücadele ederek bunların gerçek konulara uygunluğunu engeller.
Derin öğrenme, takviyeli öğrenme uzmanlarını kaba dokunsal bilgi kaynaklarından ilerici tasvirler elde etme kapasitesiyle zenginleştirerek, onlara navigasyon için temel olan dikkat çekici unsurları ve örnekleri çıkarma gücü vererek bir cevap sunuyor.
Geleneksel Pekiştirmeli Öğrenimin Zorlukları
Geleneksel takviyeli öğrenme, test başarısızlığı, doğrudan olmayan ve yüksek katmanlı durum uzayları ve boyutluluk belası gibi bir dizi zorlukla karşı karşıyadır. Buna ek olarak, bazı sertifikalandırılabilir uygulamalar yetersiz ve ertelenmiş ödüller sunarak, güçlü düzenlemeleri öğrenmek için geleneksel RL hesaplamalarını denemeye neden oluyor. Bu engeller, Geleneksel takviyeli öğrenmenin yaklaşmakta olan içsel sınırlamalarını aşmak için derin öğrenme yöntemlerinin dahil edilmesini gerektirir.
Takviyeli Öğrenmede Derin Öğrenmenin Faydaları
Takviyeli öğrenmede derin öğrenmenin birleştirilmesi, alanda reform yapılması ve farklı alanlarda ileri atılımların desteklenmesi gibi çeşitli avantajlar sunar.
Derin sinir ağları, takviyeli öğrenme uzmanlarının, manuel öğe tasarımı gerekliliğini atlayarak, kaba somut katkılardan aktivite düzenlemelerine kadar karmaşık haritalamaları etkili bir şekilde elde etmelerine olanak tanır.
Ayrıca derin öğrenme yöntemleri, çeşitli koşullar altında öğrenilen yaklaşımların spekülasyonuyla çalışır ve takviyeli öğrenme algoritmalarının uyarlanabilirliğini ve gücünü artırır.
Derin Güçlendirmeli Öğrenme Metodolojisi
Derin takviyeli öğrenme felsefesini derinlemesine incelemek, uzmanları karmaşık koşullarda ideal seçimlere karar vermeye hazırlamaya yönelik zengin bir sistem ve prosedür sahnesini ortaya çıkarır.
Profesyoneller, bu prosedürleri anlayarak, büyüyen deneyimin temelini oluşturan bileşenlerle ilgili deneyimler kazanır ve onları daha üretken ve başarılı takviyeli öğrenme algoritmaları planlamaya teşvik eder.
A. Modelsiz ve Model Tabanlı Takviyeli Öğrenim Karşılaştırması
Derin takviyeli öğrenmede, modelsiz ve model tabanlı yaklaşımlar arasındaki karar genellikle eğitim deneyimini şekillendirir. Model stratejiler olmadan, iklimin kesin bir modeline olan gereksinimi atlayarak, aslında ideal stratejiye doğrudan ulaşırsınız.
Öte yandan modele dayalı teknikler, iklim unsurlarının bir modelini öğrenmeyi ve bundan gelecekteki etkinlikleri tasarlamak için kullanmayı içerir. Model stratejilerinin uyarlanabilirlik ve çok yönlülük açısından başarılı olmadığı durumlarda, her yaklaşım kendi yararlarından ve uzlaşmalarından yararlanır; modele dayalı teknikler ise etkinlik ve spekülasyona ilişkin daha iyi örnekler sunar.
Keşif ve Sömürü Dengesi
Araştırmanın çifte-taraflı değiş tokuşu, takviyeli öğrenmenin merkezinde yer alır ve uzmanların, muhtemelen daha iyi stratejiler bulmak için yeni faaliyetleri değerlendirme (soruşturma) ile hızlı ödülleri artırmak için bilinen bilgilerden yararlanma (istismar) arasındaki dengeyi nasıl yönlendirdiğini yönlendirir.
Derin takviyeli öğrenme hesaplamaları, karmaşık koşullarda ideal stratejileri öğrenmek için araştırma ve kötüye kullanma arasında bir tür uyum sağlamalıdır. Bu dengeyi araştırmak ve öğrenme sürecini yönlendirmek için epsilon-avaricious, softmax ve Thompson testi gibi farklı araştırma prosedürlerinden yararlanılır.
Politika Gradyan Yöntemleri
Strateji eğimi teknikleri, beklenen ödülleri genişletmek için düzenleme sınırlarını doğrudan düzenleyen bir dizi takviyeli öğrenme hesaplamasını ele alır. Bu stratejiler, stratejiyi bir sinir ağı olarak tanımlar ve yaklaşma sınırları için öngörülen telafi açıları nedeniyle organizasyon yüklerini yenilemek için eğim artışını kullanır.
Strateji açısı teknikleri, kesintisiz aktivite alanlarıyla ve stokastik stratejilerle başa çıkma kapasitesi de dahil olmak üzere, bunları derin pekiştirmeli öğrenmedeki karmaşık girişimler için uygun hale getiren birkaç fayda sunar.
Değer Fonksiyonu Yöntemleri
Saygı yeteneği teknikleri, belirli bir strateji altında normal getiriye deneyimler kazandırarak durumların veya durum-faaliyet eşleşmelerinin değerini ölçmeyi amaçlamaktadır. Derin takviyeli öğrenme hesaplamaları, ideal değer yeteneğini elde etmek için sıklıkla derin Q ağları (DQN'ler) gibi saygınlık yeteneği tahmin edicilerinden yararlanır.
Derin sinir ağlarını kullanarak, saygı yeteneği teknikleri, karmaşık değer yeteneklerini tam olarak ortaya koyabilir ve yetkin yaklaşma iyileştirme ve gezinme ile çalışabilir.
Aktör-Eleştirmen Yöntemleri
Aktör-eleştirmen yöntemleri, hem strateji eğimi hem de değer yeteneği tekniklerinin faydalarını birleştirir; düzenlemeye ve değer yeteneğine aynı anda aşina olmak için ayrı eğlendirici ve uzman organizasyonlarından yararlanır.
Aktör ağı, politika parametrelerini öğrenirken, eleştirmen ağı, eylemlerin kalitesi hakkında geri bildirim sağlamak için değer fonksiyonunu tahmin eder.
Bu mimari, aktör-eleştirel yöntemlerin kararlılık ve verimlilik arasında bir denge kurmasını sağlar ve bu yöntemlerin derin takviyeli öğrenme araştırmalarında ve uygulamalarında yaygın olarak kullanılmasını sağlar.
Derin Güçlendirmeli Öğrenme Algoritmaları
Takviyeli öğrenme algoritmaları alanına bakıldığında, uzmanların bağımsız olarak öğrenmeleri ve karmaşık koşullara uyum sağlamaları konusunda yetkilendirmeye yönelik farklı bir sistem sahnesi ortaya çıkar. Bu hesaplamalar, takviyeli öğrenme ajanlarına akıllara durgunluk veren seçim alanlarını keşfetme ve bir süre sonra davranış biçimlerini geliştirme yeteneğini aşılamak için derin beyin organizasyonlarının gücünü ele alıyor.
Derin Q-Ağları (DQN)
Derin Q-Ağları (DQN), Q-öğrenme hesaplamalarıyla derin sinir ağlarının bir karışımını sunarak, derin takviyeli öğrenmede orijinal bir ilerlemeyi ele alıyor. DQN'ler, beyin organizasyonlarını kullanan aktivite saygısı kabiliyetine yaklaşarak, uzmanların yüksek katmanlı durum alanlarından ideal düzenlemeler elde etmelerini sağlar ve onları oyun ve robot bilimi gibi alanlarda ileri atılımlara hazır hale getirir.
Derin Deterministik Politika Değişimi (DDPG)
Derin Deterministik Politika Gradyanı (DDPG) hesaplamaları, eğlence uzmanı tekniklerinin standartlarını sabit aktivite alanlarına genişleterek uzmanların yokuş tırmanma yoluyla deterministik yaklaşımları öğrenmesine olanak tanır. DDPG, derin beyin ağlarını deterministik strateji eğim hesaplamasıyla birleştirerek, mekanik kontrol ve bağımsız sürüş gibi girişimlerde akıllara durgunluk veren kontrol düzenlemelerinin öğrenilmesiyle çalışır.
Yakınsal Politika Optimizasyonu (PPO)
Yakınsal Politika Optimizasyonu (PPO) hesaplamaları, güven bölgesi zorunlulukları aracılığıyla strateji sınırlarının düzenlenmesiyle başa çıkmanın ilkeli bir yolunu sunarak istikrarlı ve verimli düzenleme yenilemelerini garanti eder. PPO hesaplamaları, stokastik açı artışını kullanarak düzenleme sınırlarını yinelemeli olarak ilerleterek, farklı destek öğrenme kriterlerinde son teknoloji uygulamaları gerçekleştirerek çeşitli koşullar karşısında içtenlik ve çok yönlülük sergiler.
Güven Bölgesi Politikası Optimizasyonu (TRPO)
Güven Bölgesi Politikası Optimizasyonu (TRPO) hesaplamaları, bir güven bölgesi içindeki düzenlemelerin yenilenmesini zorunlu kılarak ve büyük strateji sapmalarından kaynaklanan kumarı hafifleterek istikrara ve test üretkenliğine odaklanır.
Politika güncellemelerine rehberlik etmek için güven bölgesi kısıtlamalarından yararlanan TRPO algoritmaları, gelişmiş yakınsama özellikleri ve hiperparametre değişikliklerine karşı sağlamlık sergileyerek onları gerçek dünyadaki takviyeli öğrenme uygulamaları için çok uygun hale getirir.
Eşzamansız Avantaj Aktör-Eleştirmen (A3C)
Eşzamansız Avantajlı Aktör-Eleştirmen (A3C) hesaplamaları, öğrenmeyi hızlandırmak ve takviyeli öğrenme girişimlerinde test etkinliğini daha da geliştirmek için eşzamanlı olmayan hazırlık döngülerinden yararlanır. A3C hesaplamaları, iklime eşzamanlı olarak bağlanan farklı eşit eğlence programlarını kullanarak daha çeşitli araştırmalarla çalışır ve uzmanların karmaşık ve dinamik koşullarda güçlü düzenlemeleri öğrenmesine olanak tanır.
Çözüm
Sonuç olarak, derin takviyeli öğrenme stratejisi, makinelerin karmaşık koşullarda bağımsız olarak öğrenmesi ve seçimleri takip etmesi için yetkilendirmeyle baş etmenin çok katmanlı bir yolunu örnekliyor. Tüm bu araştırma boyunca, takviyeli öğrenmenin temellerine, derin öğrenme prosedürlerinin koordinasyonuna ve alanda ilerleme sağlayan farklı hesaplama gösterimlerine daldık.
Merkezin standartlarını ve stratejilerini anlayarak, gelişmiş mekanik ve oyunlardan tıbbi bakım ve paraya kadar farklı alanlardaki belgelenebilir zorlukların üstesinden gelmede derin takviyeli öğrenmenin önemi hakkında bilgi ediniriz. Planladığımız gibi, derin takviyeli öğrenimde ilave ilerleme ve iyileştirme için potansiyel açık kapılar sınırsızdır.
Sürekli inceleme ve ilerlemelerle, çok daha hassas hesaplamalar, gelişmiş uyarlanabilirlik ve farklı ortamlarda daha kapsamlı uygunluk bekleyebiliriz. En son gelişmelerden haberdar olmak ve tartışmaya katılmak için aşağıdaki açıklamalarda düşüncelerinizi ve eleştirilerinizi paylaşın.
Bu önemli verileri arkadaşlarınıza ve ortaklarınıza aktarmayı unutmayın; böylece başkalarının da derin takviyeli öğrenmenin ilginç evrenini keşfetmesine olanak tanımış olursunuz. Birlikte ilerlemeyi teşvik edebilir ve Yapay zekanın maksimum kapasitesini açabiliriz.