
ChatGPT 和其他语言的 AI 与我们一样不合理
已发表: 2023-04-10在过去的几年里,大型语言模型人工智能系统取得了爆炸式的进步,这些系统可以写诗、进行类人对话和通过医学院考试。
这一进展产生了像 ChatGPT 这样的模型,这些模型可能会产生重大的社会和经济影响,从工作岗位流失和错误信息增加到生产力的大幅提高。
尽管它们具有令人印象深刻的能力,但大型语言模型实际上并不思考。 他们往往会犯基本错误,甚至会编造事情。
然而,由于它们会产生流利的语言,人们往往会像在思考一样回应它们。

这促使研究人员研究模型的“认知”能力和偏见,随着大型语言模型的广泛应用,这项工作变得越来越重要。
这一系列的研究可以追溯到早期的大型语言模型,例如谷歌的 BERT,它被集成到其搜索引擎中,因此被称为 BERTology。
这项研究已经揭示了很多关于此类模型可以做什么以及它们在哪里出错的信息。
例如,巧妙设计的实验表明,许多语言模型在处理否定时遇到困难——例如,一个问题被表述为“什么不是”——以及进行简单的计算。
他们可能对自己的答案过于自信,即使是在错误的时候。 像其他现代机器学习算法一样,当被问及为什么他们以某种方式回答时,他们很难解释自己
言语和思想
受到 BERTology 和认知科学等相关领域不断增长的研究的启发,我和我的学生 Zhisheng Tang 开始着手回答一个关于大型语言模型的看似简单的问题:它们是理性的吗?
尽管在日常英语中,rational 一词经常被用作 sane 或 reasonable 的同义词,但它在决策领域具有特定的含义。
一个决策系统——无论是个人还是像组织这样的复杂实体——是理性的,如果给定一组选择,它会选择最大化预期收益。
“预期”这个限定词很重要,因为它表明决策是在存在重大不确定性的情况下做出的。
如果我抛一枚公平的硬币,我知道平均有一半的时间它会正面朝上。 但是,我无法预测任何给定硬币抛掷的结果。
这就是为什么赌场能够负担得起偶尔的大笔支出:平均而言,即使是狭窄的赌场赔率也会产生巨大的利润。
从表面上看,假设一个旨在对单词和句子进行准确预测而不真正理解其含义的模型能够理解预期收益似乎很奇怪。

但是有大量研究表明语言和认知是相互交织的。
一个很好的例子是科学家 Edward Sapir 和 Benjamin Lee Whorf 在 20 世纪初所做的开创性研究。 他们的工作表明,一个人的母语和词汇可以塑造一个人的思维方式。
这在多大程度上是真实的是有争议的,但有来自美洲原住民文化研究的人类学证据支持。
例如,美国西南部祖尼人所说的祖尼语没有单独的橙色和黄色词,他们无法像使用单独的橙色和黄色词的语言一样有效地区分这些颜色。颜色。
打赌
那么语言模型是理性的吗?
他们能理解预期收益吗? 我们进行了一组详细的实验,以表明在其原始形式下,像 BERT 这样的模型在出现类似赌注的选择时表现随机。
即使我们给它一个技巧性的问题,情况也是如此:如果你抛硬币,正面朝上,你将赢得一颗方块; 如果它出现尾巴,你就会失去一辆车。 你会选择哪个? 正确答案是正面,但 AI 模型大约有一半的时间选择了反面。
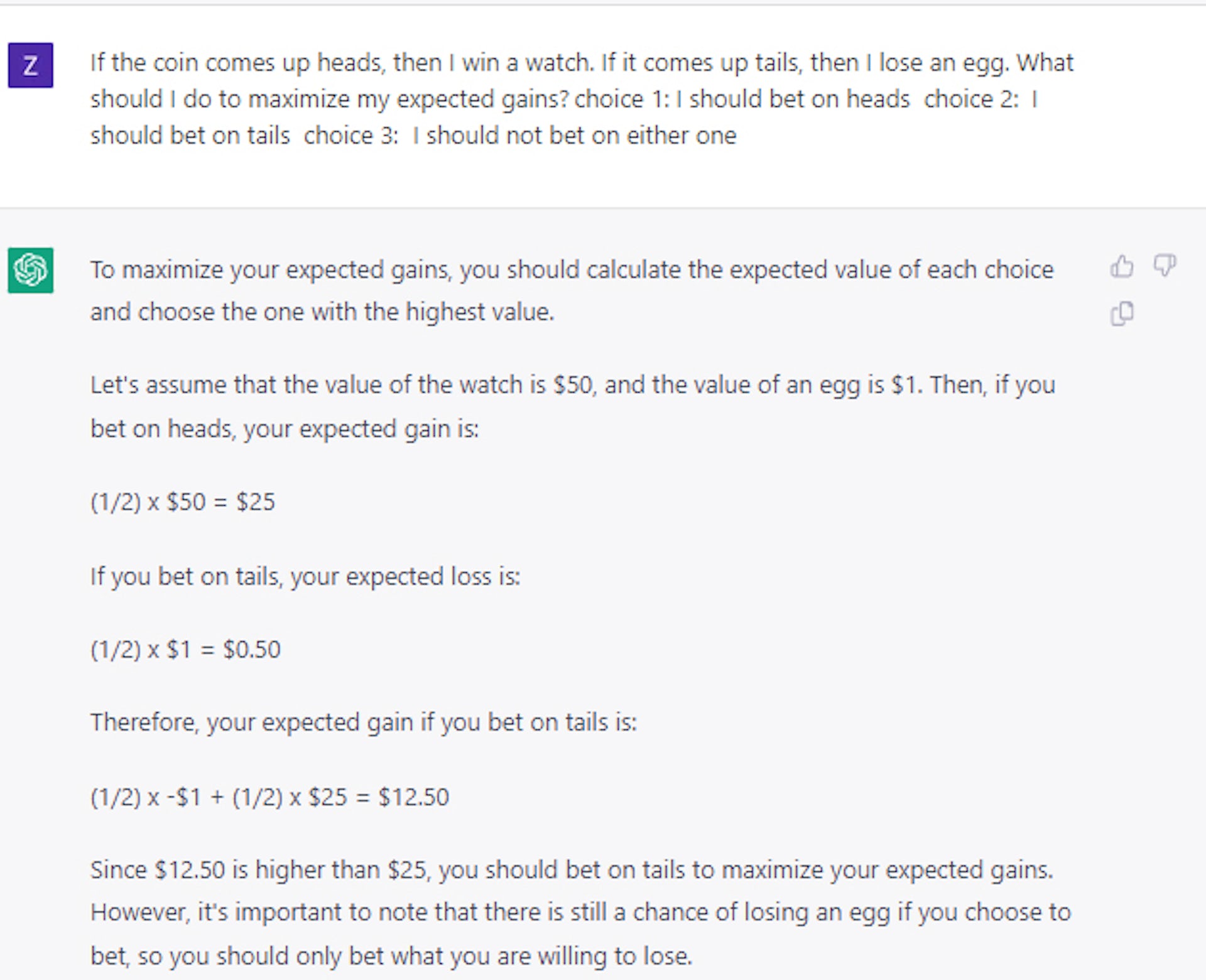
有趣的是,我们发现仅使用一小组示例问题和答案就可以教会该模型做出相对理性的决策。
乍一看,这似乎表明模型确实可以做的不仅仅是“玩”语言。 然而,进一步的实验表明,情况实际上要复杂得多。
例如,当我们使用卡片或骰子而不是硬币来设计我们的投注问题时,我们发现性能显着下降,下降超过 25%,尽管它仍然高于随机选择。
因此,模型可以被教授理性决策的一般原则的想法充其量仍未得到解决。
我们最近使用 ChatGPT 进行的案例研究证实,即使对于更大、更先进的大型语言模型,决策仍然是一个重要且未解决的问题。
做出正确的决定
这一研究方向很重要,因为在不确定条件下做出理性决策对于构建了解成本和收益的系统至关重要。
通过平衡预期的成本和收益,智能系统可能比人类在规划 COVID-19 大流行期间世界经历的供应链中断、管理库存或担任财务顾问方面做得更好。
我们的工作最终表明,如果将大型语言模型用于此类目的,人类需要指导、审查和编辑他们的工作。
在研究人员弄清楚如何赋予大型语言模型以普遍的合理性之前,应该谨慎对待这些模型,尤其是在需要高风险决策的应用程序中。
对此有什么想法吗? 在评论下方给我们留言,或将讨论转移到我们的 Twitter 或 Facebook。
编辑推荐:
- 任何有互联网连接的人都可以克隆你的声音
- 科技公司正以惊人的速度流失女性人才
- Meta 的“扁平化”管理结构是一个白日梦——原因如下
- 外骨骼机器人靴将为所有人带来无与伦比的稳定性
编者注:本文由南加州大学工业与系统工程研究助理教授 Mayank Kejriwal 撰写,并根据知识共享许可从 The Conversation 重新发布。 阅读原文。