
深度强化学习的方法论是什么?
已发表: 2024-02-28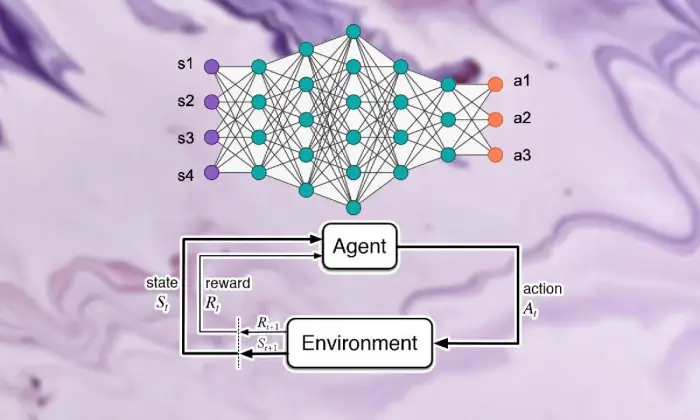
深度强化学习仍然处于最先进的人造推理的最前沿,它混合了深度学习的领域,并支持弄清楚如何使机器能够独立学习和简单决策。
深度强化学习(DRL)包括准备与气候相关的计算,并从批评中获得奖励或惩罚。 这一强大的程序将深刻的大脑网络的象征性力量与支持学习专家的动态能力结合在一起。
DRL 因其在处理不同空间(从游戏和机械技术到背部和医疗服务)的复杂任务方面的惊人技能而受到广泛关注。 它的灵活性和可行性使其成为基于计算机的智力测试和应用领域的基础,有望对企业和教师产生非凡的影响。
当我们进一步深入研究深度强化学习的复杂性时,我们应该揭示它的方法并解开它改变机器如何看待周围环境并与其协作的真正能力。

强化学习的基础知识
踏上深度强化学习之旅需要掌握支持学习的基本要素。 强化学习的核心是人工智能的世界观,它担心专家如何在环境中做出连续的选择以提高综合奖励。
在支持学习领域内,一些重要的部分和想法在形成成长经验中发挥着重要作用。 我们应该深入研究这些角度来理清强化学习方法的精髓:
基本概念和术语
要理解深度强化学习,我们必须首先接受支持学习的基本思想和措辞。 这些包含了状态、活动、奖励和策略等思想,构成了 RL 计算的结构块。
强化学习的组成部分
在深度强化学习场景中,理解支持学习的基本部分至关重要。 支持学习包含几个关键组成部分,这些组成部分决定了专家如何与当前环境联系起来,并在一段时间后学习理想的系统。
这些部分,包括专家、氛围、活动和奖项,构成了支持学习框架的结构块。 通过了解这些基本组成部分,我们可以获得有关深度强化学习计算能力以及如何应用它们来处理令人难以置信的动态问题的知识。
代理人
强化学习中的代理指的是负责简单决策和与气候联系的物质。 它弄清楚如何根据以前的遭遇和批评通过报酬或惩罚来探索气氛。
环境
环境代表了专家合作的外部框架。 它随着国家的进步而对专家进行批评和奖励,形成不断增长的经验。
行动
行动代表专家在每个选择点可以做出的决定。 专家根据活动的现状和理想结果来选择活动,这意味着从长远来看可以提高综合奖励。
奖励
奖励充当代理的输入工具,展示其活动的吸引力。 积极的奖励可以培养人们想要的行为方式,而消极的奖励则可以抑制不幸的行为。
马尔可夫决策过程 (MDP)
马尔可夫决策过程(MDP)提供了一个传统的结构来展示强化学习中的连续动态问题。 它们由状态、活动、变化概率和奖励组成,以概率的方式例证了气候的要素。
了解深度学习
离开深度强化学习的旅程涉及深入学习深度学习领域,这是一个基本部分,可以通过计算将复杂的示例和描述与信息分开。 深度学习成为许多一流的人造推理方法的基础,使机器能够学习复杂的联系并做出精确的选择。
神经网络基础知识
为了理解深度强化学习的实质,我们必须首先掌握大脑组织的基本原理。 大脑网络模仿人类思维的结构和能力,涉及循环和改变输入信息的互连神经元层。 这些组织擅长学习渐进的描述,使他们能够捕捉复杂数据集中的多方面示例和元素。
深度学习架构
在深度强化学习领域,理解深度学习结构的复杂性是首要的。 深刻的学习结构是许多高级计算的基础,让专家从信息中获得复杂的示例和描述。
通过研究这些结构,我们可以解开使专家能够处理和破译数据的组件,并在独特的条件下以敏锐的动态进行工作。
卷积神经网络 (CNN)
卷积神经网络 (CNN) 在处理类似网络的信息(例如图片和录音)方面具有一定的专业知识。 它们影响卷积层以逐步删除空间元素,使它们能够执行图像顺序、对象识别和分割等前沿任务。
循环神经网络 (RNN)
循环神经网络 (RNN) 成功地处理具有瞬态条件的连续信息,例如时间序列和常规语言。 它们具有间歇性的联想,使它们能够在不同的时间步长上保持记忆,从而适合执行语言显示、机器翻译和对话识别等任务。
深度 Q 网络 (DQN)
深度 Q 网络 (DQN) 解决了支持拾取并通过 Q 学习计算巩固深度大脑网络的特定工程。 这些组织知道如何提高活动评估能力,使他们能够在具有高层状态空间的情况下做出理想的选择。
训练神经网络
训练神经网络是深度强化学习的基本组成部分,对于使专家能够获得事实并进一步发展其动态能力具有重要意义。 神经网络准备使用反向传播和斜率直线下降等计算,这些计算可以改变组织的边界以限制期望错误。

在整个准备周期中,组织中都会处理信息,并且模型会迭代地找出如何做出更精确的预测。 通过在发现错误的情况下迭代地刷新组织的边界,大脑网络可以稳定地完成给定任务的呈现。 这种迭代的改进过程是深度强化学习的核心部分,使专家能够从长远来看调整和简化他们的系统。
反向传播
反向传播作为准备大脑组织的基础,使它们能够通过迭代地改变边界来限制期望错误,从而从信息中获益。 该计算计算了网络边界的灾难能力的斜率,并通过斜率下降来提高生产力。
梯度下降
梯度下降是增强大脑网络边界的核心,将教育体验引导至不幸能力的最小值。 通过迭代地刷新最陡峭下降的边界,角度下降计算使大脑组织能够加入理想的排列。
另请阅读:深度学习与机器学习:主要区别
强化学习与深度学习的融合
协调强化学习与深度学习解决了人造意识领域的重要进步,协同利用两种理想模型的品质以卓越的可行性处理复杂的动态任务。
深度学习与支持学习策略的一致结合,揭示了推动它们加入的灵感、传统支持学习所带来的困难以及深度学习方法融合所带来的突破性优势。
深度强化学习的动机
深度强化学习的加入是为了以更通用、适应性更强、更有效的方式在复杂条件下处理学习理想安排的使命推动的。 传统的强化学习计算经常与高层状态空间和微薄的奖励作斗争,阻碍了它们对实际问题的适用性。
深度学习提供了一个答案,让强化学习专家能够从原始的触觉信息源中获得渐进的描述,使他们能够提取对导航至关重要的重要元素和示例。
传统强化学习的挑战
传统的强化学习面临着一系列困难,包括测试失败、非直接和高层状态空间以及维度的祸害。 此外,一些可认证的应用程序提供的奖励微薄且延迟,这使得传统的强化学习计算无法学习强大的安排。 这些障碍需要结合深度学习方法来克服传统强化学习的内在局限性。
深度学习在强化学习中的好处
深度学习在强化学习中的整合呈现出多种优势,改革了该领域,并在不同领域实现了飞跃。
深度神经网络使强化学习专家能够有效地从对活动安排的粗略有形贡献中获得复杂的映射,从而绕过手动元素设计的要求。
此外,深度学习方法还可以在各种条件下对学习方法进行推测,从而提升强化学习算法的适应性和强度。
深度强化学习方法论
深入研究深度强化学习的哲学,揭示了丰富的系统和程序场景,旨在帮助专家在复杂的条件下做出理想的选择。
通过了解这些过程,专业人员可以积累经验基础上的知识,让他们能够规划更高效、更成功的强化学习算法。
A. 无模型与基于模型的强化学习
在深度强化学习中,无模型方法和基于模型的方法之间的决定通常会影响教育体验。 事实上,如果没有模型策略,就可以直接获得理想的策略,从而绕过对明确气候模型的要求。
另一方面,基于模型的技术包括学习气候要素模型并利用它来设计未来的活动。 每种方法都有其优点和妥协,模型策略没有在适应性和多功能性方面取得成功,而基于模型的技术提供了更好的有效性和推测的例子。
探索与利用的权衡
调查双重交易权衡是强化学习的核心,指导专家如何在评估新活动以找到可能更好的策略(调查)和利用已知信息来增加快速奖励(滥用)之间取得平衡。
深度强化学习计算应该在调查和滥用之间找到某种和谐,以在复杂条件下学习理想的策略。 不同的调查程序,如 epsilon-avaricious、softmax 和 Thompson 测试,被用来探索这种权衡并指导学习过程。
策略梯度法
策略斜率技术解决了一类强化学习计算问题,可以直接简化安排边界以扩大预期奖励。 这些策略将策略定义为神经网络,并利用斜率上升来刷新组织负载,因为接近边界的预期补偿角度。
策略角度技术提供了一些好处,包括处理不间断活动空间和随机策略的能力,使它们适合深度强化学习中的复杂任务。
值函数法
尊重能力技术旨在衡量状态或状态活动匹配的价值,为给定策略下的正常回报提供经验。 深度强化学习计算经常使用深度 Q 网络 (DQN) 等估值能力逼近器来获得理想的估值能力。
通过利用深度神经网络,评价能力技术可以使复杂的价值能力变得不精确,并与熟练的方法改进和导航一起工作。
演员批评家方法
演员-评论家方法整合了策略斜率和价值能力技术的优势,利用不同的演员和专家组织同时熟悉安排和价值能力。
行动者网络学习策略参数,而批评者网络估计价值函数以提供有关行动质量的反馈。
这种架构使actor-critic方法能够实现稳定性和效率之间的平衡,使其广泛应用于深度强化学习研究和应用。
深度强化学习算法
深入研究强化学习算法领域,揭示了不同的系统场景,旨在使专家能够独立学习并适应复杂的条件。 这些计算解决了深层大脑组织的力量,向强化学习代理灌输探索令人难以置信的选择空间并在一段时间后改善其行为方式的能力。
深度 Q 网络 (DQN)
深度 Q 网络 (DQN) 解决了深度强化学习领域的原始问题,将深度神经网络与 Q 学习计算相结合。 通过利用大脑组织来近似活动评价能力,DQN 使专家能够从高层状态空间中获得理想的安排,使他们为游戏和机器人等领域的飞跃做好准备。
深度确定性策略梯度(DDPG)
深度确定性策略梯度 (DDPG) 计算将娱乐专家技术的标准扩展到恒定的活动空间,使专家能够通过爬坡来学习确定性方法。 通过将深刻的大脑网络与确定性策略斜率计算相结合,DDPG 可以学习机械控制和独立驾驶等令人难以置信的控制安排。
近端策略优化 (PPO)
近端策略优化 (PPO) 计算提供了一种通过信任区域规则来简化策略边界的原则性方法,从而保证稳定且高效的安排更新。 通过利用随机角度增量迭代地推进排列边界,PPO 计算在不同的支持学习基准中实现了领先的执行,在各种条件下表现出稳健性和多功能性。
信任域策略优化 (TRPO)
信任区域策略优化 (TRPO) 计算侧重于稳定性,并通过强制信任区域内的安排更新来测试生产力,从而减少巨大策略偏差的风险。
通过利用信任域约束来指导策略更新,TRPO 算法表现出增强的收敛特性和对超参数变化的鲁棒性,使其非常适合现实世界的强化学习应用。
异步优势 Actor-Critic (A3C)
异步优势 Actor-Critic (A3C) 计算利用非并发准备周期来加速学习并进一步提高强化学习项目中的测试有效性。 通过利用不同的平等参与者与气候同时连接,A3C 计算可与更多种类的研究相结合,使专家能够在复杂和动态的条件下学习强大的安排。
结论
总而言之,深度强化学习策略体现了一种多层方法,可以使机器在复杂的条件下独立学习和追求选择。 在整个研究过程中,我们深入研究了强化学习的本质、深度学习过程的协调以及推动该领域进展的不同计算表现。
通过了解中心的标准和策略,我们了解了深度强化学习在处理不同领域(从高级机制和游戏到医疗保健和金钱)的可证明困难方面的重要性。 正如我们计划的那样,深度强化学习的进一步进步和改进的潜力是无限的。
通过不断的检查和进展,我们可以期待更精细的计算、更高的适应性以及在不同环境中更广泛的针对性。 为了了解最新的事件发展并加入讨论,请继续在下面的评论中分享您的想法和批评。
请记住将这些重要数据传授给您的同伴和合作伙伴,使其他人能够研究深度强化学习的有趣领域。 我们可以共同推动进步并发挥人工智能的最大能力。