
ChatGPT 和其他語言的 AI 與我們一樣不合理
已發表: 2023-04-10在過去的幾年裡,大型語言模型人工智能係統取得了爆炸式的進步,這些系統可以寫詩、進行類人對話和通過醫學院考試。
這一進展產生了像 ChatGPT 這樣的模型,這些模型可能會產生重大的社會和經濟影響,從工作崗位流失和錯誤信息增加到生產力的大幅提高。
儘管它們具有令人印象深刻的能力,但大型語言模型實際上並不思考。 他們往往會犯基本錯誤,甚至會編造事情。
然而,由於它們會產生流利的語言,人們往往會像在思考一樣回應它們。

這促使研究人員研究模型的“認知”能力和偏見,隨著大型語言模型的廣泛應用,這項工作變得越來越重要。
這一系列的研究可以追溯到早期的大型語言模型,例如穀歌的 BERT,它被集成到其搜索引擎中,因此被稱為 BERTology。
這項研究已經揭示了很多關於此類模型可以做什麼以及它們在哪裡出錯的信息。
例如,巧妙設計的實驗表明,許多語言模型在處理否定時遇到困難——例如,一個問題被表述為“什麼不是”——以及進行簡單的計算。
他們可能對自己的答案過於自信,即使是在錯誤的時候。 像其他現代機器學習算法一樣,當被問及為什麼他們以某種方式回答時,他們很難解釋自己
言語和思想
受到 BERTology 和認知科學等相關領域不斷增長的研究的啟發,我和我的學生 Zhisheng Tang 開始著手回答一個關於大型語言模型的看似簡單的問題:它們是理性的嗎?
儘管在日常英語中,rational 一詞經常被用作 sane 或 reasonable 的同義詞,但它在決策領域具有特定的含義。
一個決策系統——無論是個人還是像組織這樣的複雜實體——是理性的,如果給定一組選擇,它會選擇最大化預期收益。
“預期”這個限定詞很重要,因為它表明決策是在存在重大不確定性的情況下做出的。
如果我拋一枚公平的硬幣,我知道平均有一半的時間它會正面朝上。 但是,我無法預測任何給定硬幣拋擲的結果。
這就是為什麼賭場能夠負擔得起偶爾的大筆支出:平均而言,即使是狹窄的賭場賠率也會產生巨大的利潤。
從表面上看,假設一個旨在對單詞和句子進行準確預測而不真正理解其含義的模型能夠理解預期收益似乎很奇怪。

但是有大量研究表明語言和認知是相互交織的。
一個很好的例子是科學家 Edward Sapir 和 Benjamin Lee Whorf 在 20 世紀初所做的開創性研究。 他們的工作表明,一個人的母語和詞彙可以塑造一個人的思維方式。
這在多大程度上是真實的是有爭議的,但有來自美洲原住民文化研究的人類學證據支持。
例如,美國西南部祖尼人所說的祖尼語沒有單獨的橙色和黃色詞,他們無法像使用單獨的橙色和黃色詞的語言一樣有效地區分這些顏色。顏色。
打賭
那麼語言模型是理性的嗎?
他們能理解預期收益嗎? 我們進行了一組詳細的實驗,以表明在其原始形式下,像 BERT 這樣的模型在出現類似賭注的選擇時表現隨機。
即使我們給它一個技巧性的問題,情況也是如此:如果你拋硬幣,正面朝上,你將贏得一顆方塊; 如果它出現尾巴,你就會失去一輛車。 你會選擇哪個? 正確答案是正面,但 AI 模型大約有一半的時間選擇了反面。
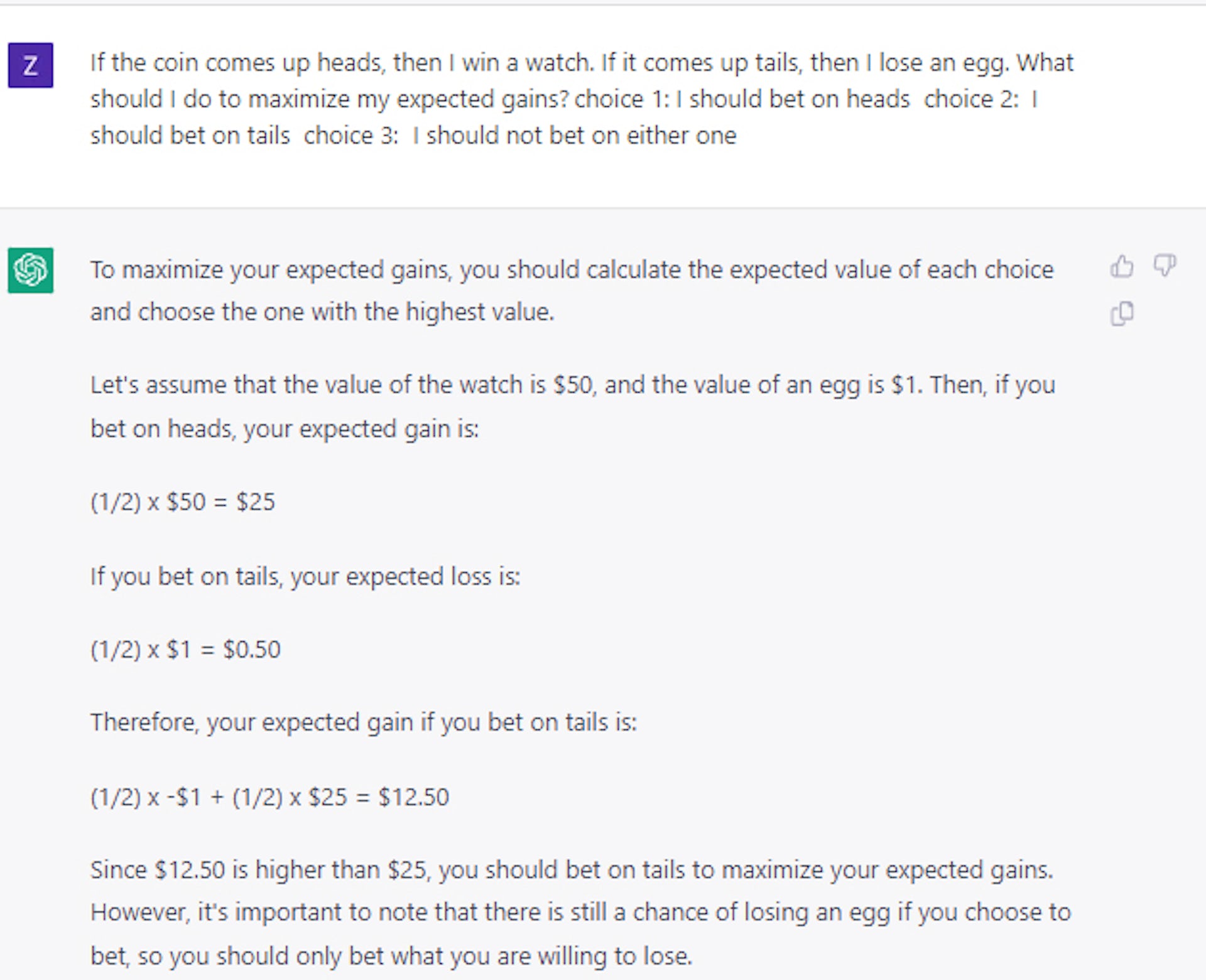
有趣的是,我們發現僅使用一小組示例問題和答案就可以教會該模型做出相對理性的決策。
乍一看,這似乎表明模型確實可以做的不僅僅是“玩”語言。 然而,進一步的實驗表明,情況實際上要復雜得多。
例如,當我們使用卡片或骰子而不是硬幣來設計我們的投注問題時,我們發現性能顯著下降,下降超過 25%,儘管它仍然高於隨機選擇。
因此,模型可以被教授理性決策的一般原則的想法充其量仍未得到解決。
我們最近使用 ChatGPT 進行的案例研究證實,即使對於更大、更先進的大型語言模型,決策仍然是一個重要且未解決的問題。
做出正確的決定
這一研究方向很重要,因為在不確定條件下做出理性決策對於構建了解成本和收益的系統至關重要。
通過平衡預期的成本和收益,智能係統可能比人類在規劃 COVID-19 大流行期間世界經歷的供應鏈中斷、管理庫存或擔任財務顧問方面做得更好。
我們的工作最終表明,如果將大型語言模型用於此類目的,人類需要指導、審查和編輯他們的工作。
在研究人員弄清楚如何賦予大型語言模型以普遍的合理性之前,應該謹慎對待這些模型,尤其是在需要高風險決策的應用程序中。
對此有什麼想法嗎? 在評論下方給我們留言,或將討論轉移到我們的 Twitter 或 Facebook。
編輯推薦:
- 任何有互聯網連接的人都可以克隆你的聲音
- 科技公司正以驚人的速度流失女性人才
- Meta 的“扁平化”管理結構是一個白日夢——原因如下
- 外骨骼機器人靴將為所有人帶來無與倫比的穩定性
編者註:本文由南加州大學工業與系統工程研究助理教授 Mayank Kejriwal 撰寫,並根據知識共享許可從 The Conversation 重新發布。 閱讀原文。