
深度強化學習的方法論是什麼?
已發表: 2024-02-28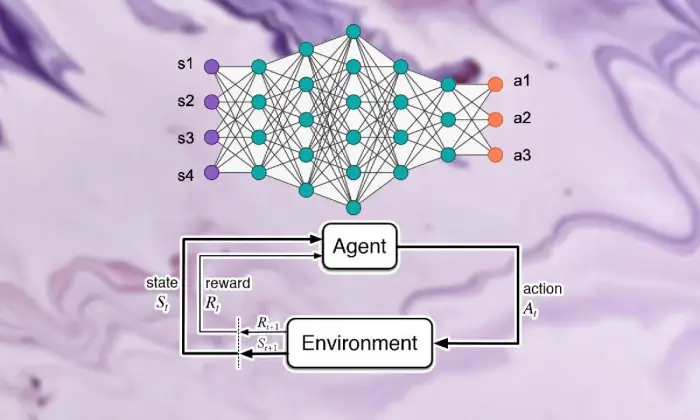
深度強化學習仍然處於最先進的人造推理的最前沿,它混合了深度學習的領域,並支持弄清楚如何使機器獨立學習和簡單決策。
深度強化學習(DRL)包括準備與氣候相關的計算,並從批評中獲得獎勵或懲罰。 這個強大的程序將深刻的大腦網路的象徵性力量與支持學習專家的動態能力結合在一起。
DRL 因其在處理不同空間(從遊戲和機械技術到背部和醫療服務)的複雜任務方面的驚人技能而受到廣泛關注。 它的靈活性和可行性使其成為基於電腦的智力測驗和應用領域的基礎,有望對企業和教師產生非凡的影響。
當我們進一步深入研究深度強化學習的複雜性時,我們應該揭示它的方法並解開它改變機器如何看待周圍環境並與其協作的真正能力。

強化學習的基礎知識
踏上深度強化學習之旅需要掌握支持學習的基本要素。 強化學習的核心是人工智慧的世界觀,它擔心專家如何在環境中做出連續的選擇以提高全面獎勵。
在支持學習領域內,一些重要的部分和想法在形成成長經驗中發揮重要作用。 我們應該深入研究這些角度來釐清強化學習方法的精髓:
基本概念和術語
要理解深度強化學習,我們必須先接受支持學習的基本想法和措詞。 這些包含了狀態、活動、獎勵和策略等思想,構成了 RL 計算的結構塊。
強化學習的組成部分
在深度強化學習場景中,理解支持學習的基本部分至關重要。 支援學習包含幾個關鍵組成部分,這些組成部分決定了專家如何與當前環境聯繫起來,並在一段時間後學習理想的系統。
這些部分,包括專家、氛圍、活動和獎項,構成了支持學習框架的結構塊。 透過了解這些基本組成部分,我們可以獲得有關深度強化學習運算能力以及如何應用它們來處理令人難以置信的動態問題的知識。
代理人
強化學習中的代理人指的是負責簡單決策和與氣候連結的物質。 它弄清楚如何根據以前的遭遇和批評透過報酬或懲罰來探索氣氛。
環境
環境代表了專家合作的外部框架。 它隨著國家的進步而對專家進行批評和獎勵,形成不斷增長的經驗。
行動
行動代表專家在每個選擇點可以做出的決定。 專家根據活動的現狀和理想結果來選擇活動,這意味著從長遠來看可以提高綜合獎勵。
獎勵
獎勵充當代理的輸入工具,展示其活動的吸引力。 正面的獎勵可以培養人們想要的行為方式,而負面的獎勵則可以抑制不幸的行為。
馬可夫決策過程 (MDP)
馬可夫決策過程(MDP)提供了一個傳統的結構來展示強化學習中的連續動態問題。 它們由狀態、活動、變化機率和獎勵組成,以機率的方式例證了氣候的要素。
了解深度學習
離開深度強化學習的旅程涉及深入學習深度學習領域,這是一個基本部分,可以透過計算將複雜的範例和描述與資訊分開。 深度學習成為許多一流的人造推理方法的基礎,使機器能夠學習複雜的聯繫並做出精確的選擇。
神經網路基礎知識
為了瞭解深度強化學習的實質,我們必須先掌握大腦組織的基本原理。 大腦網路模仿人類思維的結構和能力,涉及循環和改變輸入資訊的互連神經元層。 這些組織擅長學習漸進的描述,使他們能夠捕捉複雜資料集中的多面向範例和元素。
深度學習架構
在深度強化學習領域,理解深度學習結構的複雜性是首要的。 深刻的學習結構是許多高階計算的基礎,讓專家從資訊中獲得複雜的範例和描述。
透過研究這些結構,我們可以解開使專家能夠處理和破解數據的組件,並在獨特的條件下以敏銳的動態進行工作。
卷積神經網路 (CNN)
卷積神經網路 (CNN) 在處理類似網路的資訊(例如圖片和錄音)方面具有一定的專業知識。 它們影響卷積層以逐步刪除空間元素,使它們能夠執行影像順序、物件識別和分割等前沿任務。
循環神經網路 (RNN)
循環神經網路 (RNN) 成功地處理具有瞬態條件的連續訊息,例如時間序列和常規語言。 它們具有間歇性的聯想,使它們能夠在不同的時間步長上保持記憶,從而適合執行語言顯示、機器翻譯和對話識別等任務。
深度 Q 網路 (DQN)
深度 Q 網路 (DQN) 解決了支援拾取並透過 Q 學習計算鞏固深度大腦網路的特定工程。 這些組織知道如何提高活動評估能力,使他們能夠在具有高層狀態空間的情況下做出理想的選擇。
訓練神經網絡
訓練神經網路是深度強化學習的基本組成部分,對於使專家能夠獲得事實並進一步發展其動態能力具有重要意義。 神經網路準備使用反向傳播和斜率直線下降等計算,這些計算可以改變組織的邊界以限制期望錯誤。

在整個準備週期中,組織中都會處理訊息,模型會迭代地找出如何做出更精確的預測。 透過在發現錯誤的情況下迭代地刷新組織的邊界,大腦網路可以穩定地完成給定任務的呈現。 這種迭代的改進過程是深度強化學習的核心部分,使專家能夠從長遠來看調整和簡化他們的系統。
反向傳播
反向傳播作為準備大腦組織的基礎,使它們能夠透過迭代地改變邊界來限制期望錯誤,從而從資訊中獲益。 該計算計算了網路邊界的災難能力的斜率,並透過斜率下降來提高生產力。
梯度下降
梯度下降是增強大腦網路邊界的核心,將教育體驗引導至不幸能力的最小值。 透過迭代地刷新最陡峭下降的邊界,角度下降計算使大腦組織能夠加入理想的排列。
另請閱讀:深度學習與機器學習:主要區別
強化學習與深度學習的融合
協調強化學習與深度學習解決了人造意識領域的重要進步,協同利用兩種理想模型的品質以卓越的可行性處理複雜的動態任務。
深度學習與支持學習策略的一致結合,揭示了推動它們加入的靈感、傳統支持學習所帶來的困難以及深度學習方法融合所帶來的突破性優勢。
深度強化學習的動機
深度強化學習的加入是為了以更通用、更適應性、更有效的方式在複雜條件下處理學習理想安排的使命所推動的。 傳統的強化學習計算經常與高層狀態空間和微薄的獎勵作鬥爭,阻礙了它們對實際問題的適用性。
深度學習提供了一個答案,讓強化學習專家能夠從原始的觸覺資訊來源中獲得漸進的描述,使他們能夠提取對導航至關重要的重要元素和範例。
傳統強化學習的挑戰
傳統的強化學習面臨一系列困難,包括測驗失敗、非直接和高層狀態空間以及維度的禍害。 此外,一些可認證的應用程式提供的獎勵微薄且延遲,這使得傳統的強化學習運算無法學習強大的安排。 這些障礙需要結合深度學習方法來克服傳統強化學習的內在限制。
深度學習在強化學習的好處
深度學習在強化學習中的整合呈現出多種優勢,改革了這個領域,並在不同領域實現了飛躍。
深度神經網路使強化學習專家能夠有效地從對活動安排的粗略有形貢獻中獲得複雜的映射,從而繞過手動元素設計的要求。
此外,深度學習方法還可以在各種條件下對學習方法進行推測,從而提升強化學習演算法的適應性和強度。
深度強化學習方法論
深入研究深度強化學習的哲學,揭示了豐富的系統和程序場景,旨在幫助專家在複雜的條件下做出理想的選擇。
透過了解這些過程,專業人員可以累積經驗基礎上的知識,讓他們能夠規劃更有效率、更成功的強化學習演算法。
A. 無模型與基於模型的強化學習
在深度強化學習中,無模型方法和基於模型的方法之間的決定通常會影響教育體驗。 事實上,如果沒有模型策略,就可以直接獲得理想的策略,從而繞過明確氣候模型的要求。
另一方面,基於模型的技術包括學習氣候要素模型並利用它來設計未來的活動。 每種方法都有其優點和妥協,模型策略沒有在適應性和多功能性方面取得成功,而基於模型的技術提供了更好的有效性和推測的例子。
探索與利用的權衡
調查雙重交易權衡是強化學習的核心,指導專家如何在評估新活動以找到可能更好的策略(調查)和利用已知資訊來增加快速獎勵(濫用)之間取得平衡。
深度強化學習計算應該在調查和濫用之間找到某種和諧,以在複雜條件下學習理想的策略。 不同的調查程序,如 epsilon-avaricious、softmax 和 Thompson 測試,被用來探索這種權衡並指導學習過程。
策略梯度法
策略斜率技術解決了一類強化學習運算問題,可以直接簡化安排邊界以擴大預期獎勵。 這些策略將策略定義為神經網絡,並利用斜率上升來刷新組織負載,因為接近邊界的預期補償角度。
策略角度技術提供了一些好處,包括處理不間斷活動空間和隨機策略的能力,使它們適合深度強化學習中的複雜任務。
值函數法
尊重能力技術旨在衡量狀態或狀態活動匹配的價值,為給定策略下的正常回報提供經驗。 深度強化學習計算經常使用深度 Q 網路 (DQN) 等估值能力逼近器來獲得理想的估值能力。
透過利用深度神經網絡,評估能力技術可以使複雜的價值能力變得不精確,並與熟練的方法改進和導航一起工作。
演員批評家方法
演員-評論家方法整合了策略斜率和價值能力技術的優勢,利用不同的演員和專家組織同時熟悉安排和價值能力。
行動者網路學習策略參數,而批評者網路估計價值函數以提供有關行動品質的回饋。
這種架構使actor-critic方法能夠實現穩定性和效率之間的平衡,使其廣泛應用於深度強化學習研究和應用。
深度強化學習演算法
深入研究強化學習演算法領域,揭示了不同的系統場景,旨在使專家能夠獨立學習並適應複雜的條件。 這些計算解決了深層大腦組織的力量,向強化學習代理灌輸探索令人難以置信的選擇空間並在一段時間後改善其行為方式的能力。
深度 Q 網路 (DQN)
深度 Q 網路 (DQN) 解決了深度強化學習領域的原始問題,將深度神經網路與 Q 學習計算相結合。 透過利用大腦組織來近似活動評估能力,DQN 使專家能夠從高層狀態空間中獲得理想的安排,使他們為遊戲和機器人等領域的飛躍做好準備。
深度確定性策略梯度(DDPG)
深度確定性策略梯度 (DDPG) 計算將娛樂專家技術的標準擴展到恆定的活動空間,使專家能夠透過爬坡來學習確定性方法。 透過將深刻的大腦網路與確定性策略斜率運算相結合,DDPG 可以學習機械控制和獨立駕駛等令人難以置信的控制安排。
近端策略優化 (PPO)
近端策略最佳化 (PPO) 計算提供了一種透過信任區域規則來簡化策略邊界的原則性方法,從而確保穩定且高效的安排更新。 透過利用隨機角度增量迭代地推進排列邊界,PPO 計算在不同的支援學習基準中實現了領先的執行,在各種條件下表現出穩健性和多功能性。
信任域策略優化 (TRPO)
信任區域策略最佳化 (TRPO) 計算著重於穩定性,並透過強制信任區域內的安排更新來測試生產力,從而減少巨大策略偏差的風險。
透過利用信任域約束來指導策略更新,TRPO 演算法表現出增強的收斂特性和對超參數變化的穩健性,使其非常適合現實世界的強化學習應用。
非同步優勢 Actor-Critic (A3C)
非同步優勢 Actor-Critic (A3C) 計算利用非並發準備週期來加速學習並進一步提高強化學習項目中的測驗成效。 透過利用不同的平等參與者與氣候同時連接,A3C 計算可與更多種類的研究相結合,使專家能夠在複雜和動態的條件下學習強大的安排。
結論
總而言之,深度強化學習策略體現了一種多層方法,可以使機器在複雜的條件下獨立學習和追求選擇。 在整個研究過程中,我們深入研究了強化學習的本質、深度學習過程的協調以及推動該領域進展的不同計算表現。
透過了解中心的標準和策略,我們了解了深度強化學習在處理不同領域(從高級機制和遊戲到醫療保健和金錢)的可證明困難方面的重要性。 正如我們計劃的那樣,深度強化學習的進一步進步和改進的潛力是無限的。
透過不斷的檢查和進展,我們可以期待更精細的計算、更高的適應性以及在不同環境中更廣泛的針對性。 為了了解最新的事件發展並加入討論,請繼續在下面的評論中分享您的想法和批評。
請記住將這些重要數據傳授給您的同伴和合作夥伴,使其他人能夠研究深度強化學習的有趣領域。 我們可以共同推動進步並發揮人工智慧的最大能力。